
Published Date : December 21, 2016
I’ve talked about Data Preparation many times in conferences such as PASS Summit, BA Conference, and many other conferences. Every time I talk about this I realize how much more I need to explain this. Data Preparation tips are basic, but very important. In my opinion as someone who worked with BI systems more than 15 years, this is the most important task in building in BI system. In this post I’ll explain why data preparation is necessary and what are five basic steps you need to be aware of when building a data model with Power BI (or any other BI tools). This post is totally conceptual, and you can apply these rules on any tools.
All of us have seen many data models like screenshot below. Transactional databases has the nature of many tables and relationship between tables. Transactional databases are build for CRUD operations (Create, Retrieve, Update, Delete rows). Because of this single purpose, transactional databases are build in Normalized way, to reduce redundancy and increase consistency of the data. For example there should be one table for Product Category with a Key related to a Product Table, because then whenever a product category name changes there is only one record to update and all products related to that will be updated automatically because they are just using the key. There are books to read if you are interested in how database normalization works.

I’m not going to talk about how to build these databases. In fact for building a data model for BI system you need to avoid this type of modeling! This model works perfectly for transactional database (when there are systems and operators do data entry and modifications). However this model is not good for a BI system. There are several reasons for that, here are two most important reasons;
You never want to wait for hours for a report to respond. Response time of reports should be fast. You also never wants your report users (of self-service report users) to understand schema above. It is sometimes even hard for a database developer to understand how this works in first few hours! You need to make your model simpler, with few tables and relationships. Your first and the most important job as a BI developer should be transforming above schema to something like below;
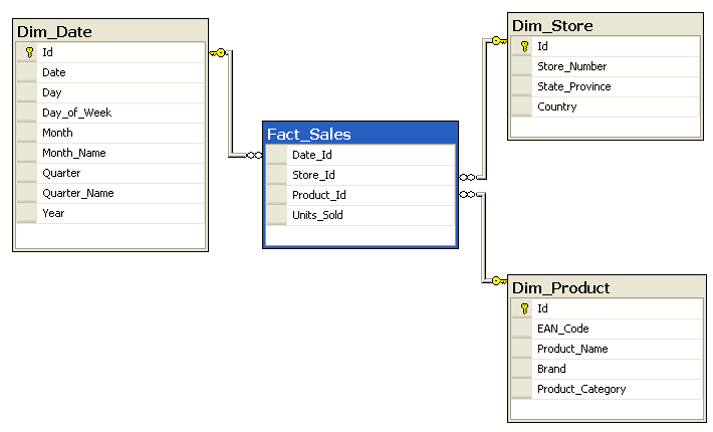
This model is far simpler and faster. There is one table that keeps sales information (Fact_Sales), and few other tables which keep descriptions (such as Product description, name, brand, and category). There is one one relationship that connects the table in the middle (Fact) to tables around (Dimensions). This is the best model to work with in a BI system. This model is called Star Schema. Building a star schema or dimensional modeling is your most important task as a BI developer.
To build a star schema for your data model I strongly suggest you to take one step at a time. What I mean by that is choosing one or few use cases and start building the model for that. For example; instead of building a data model for the whole Dynamics AX or CRM which might have more than thousands of tables, just choose Sales side of it, or Purchasing, or GL. After choosing one subject area (for example Sales), then start building the model for it considering what is required for the analysis.
Fact tables are tables that are holding numeric and additive data normally. For example quantity sold, or sales amount, or discount, or cost, or things like that. These values are numeric and can be aggregated. Here is an example of fact table for sales;

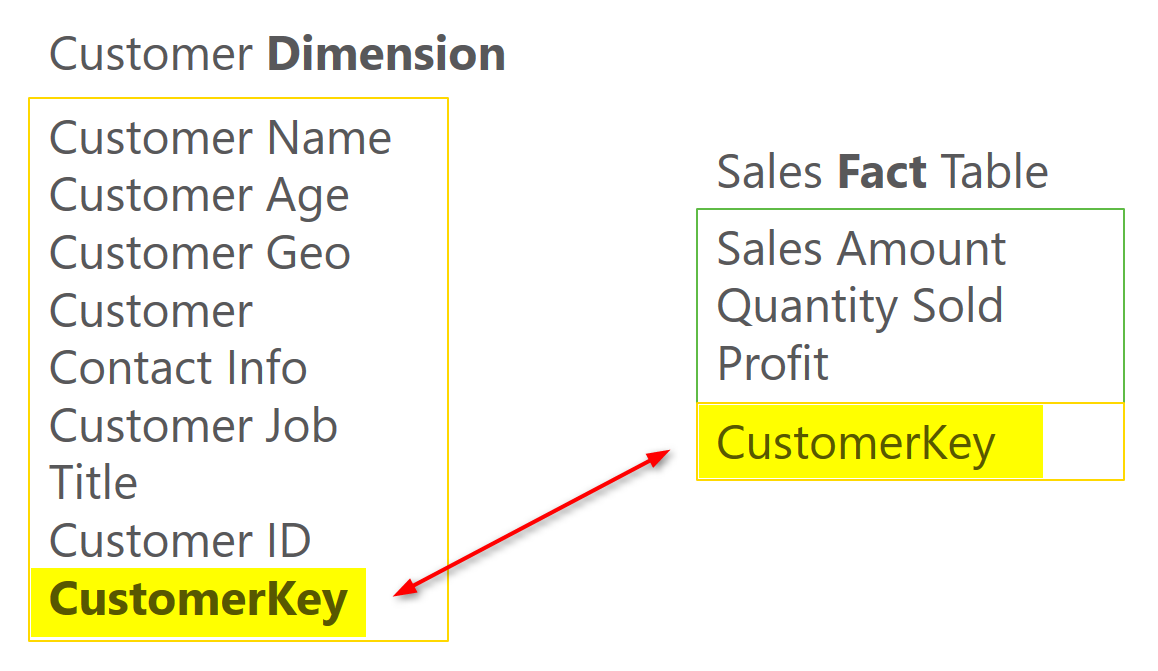
Any descriptive information will be kept in Dimension tables. For example; customer name, customer age, customer geo information, customer contact information, customer job, customer id, and any other customer related information will be kept in a table named Customer Dimension.

each dimension table should contain a key column. this column should be numeric (integer or big integer depends on the size of dimension) which is auto increment (Identity in SQL Server terminology). This column should be unique per each row in the dimension table. This column will be primary key of this table and will be used in fact table as a relationship. This column SHOULDN’T be ID of the source system. There are several reasons for why. This column is called Surrogate Key. Here are few reasons why you need to have surrogate key:
Surrogate key of the dimension should be used in the fact table as foreign key. Here is an example;
Other dimensions should be also added in the same way. in example below a Date Dimension and Product Dimension is also created. You can easily see in the screenshot below that why it is called star schema; Fact table is in the middle and all other dimensions are around with one relationship from fact table to other dimensions.
Building star schema or dimensional modeling is something that you have to read books about it to get it right, I will write some more blog posts and explain these principles more in details. however it would be great to leave some tips here for you to get things started towards better modeling. These tips are simple, but easy to overlook. Number of BI solutions that I have seen suffer from not obeying these rules are countless. These are rules that if you do not follow, you will be soon far away from proper data modeling, and you have to spend ten times more to build your model proper from the beginning. Here are tips:
Why?
Tables can be joined together to create more flatten and simpler structure.
Solution: DO create flatten structure for tables (specially dimensions)
Why?
Fact table are the largest entities in your model. Flattening them will make them even larger!
Solution: DO create relationships to dimension tables
Why?
names such as std_id, or dimStudent are confusing for users.
Solution: DO set naming of your tables and columns for the end user
Why?
Some data types are spending memory (and CPU) like decimals. Appropriate data types are also helpful for engines such as Q&A in Power BI which are working based on the data model.
Solution: DO set proper data types based on the data in each field
Why?
Filtering part of the data before loading it into memory is cost and performance effective.
Solution: DO Filter part of the data that is not required.
This was just a very quick introduction to data preparation with some tips. This is beginning of blog post series I will write in the future about principles of dimensional modeling and how to use them in Power BI or any other BI tools. You can definitely build a BI solution without using these concepts and principles, but your BI system will slow down and users will suffer from using it after few months, I’ll give you my word on it. Stay tuned for future posts on this subject.