

Azure HDInsight is an open-source analytics and cloud base service. Azure HDInsight is easy, fast, and cost-effective for processing the massive amounts of data. There are many different use case scenarios for HDInsight such as extract, transform, and load (ETL), data warehousing, machine learning, IoT and so forth.
The main benefit of using HDInsight for machine learning is to about access to a memory-based processing framework. HDInsight helps developers to process and analyze big data, and develop solutions using some great and open source framework such as Hadoop, Spark, Hive, LLAP, Kafka, Storm, and Microsoft Machine Learning Server [1].
Set up clusters in HDInsight
The first step is to set up an HDInsight in Azure. Login to your Azure account and create an HDInsight component in Azure . As you can see in the below figure, there are different modules for HDInsight such as HDInsight Spark monitoring and HDInsight Interactive Query monitoring. Among those select the HDInsight analytics option.

When you create an HDInsight, you need to follow some steps for setting up the cluster and identifying the size. In the first step, you need to set a name for the cluster, set the subscription, and the cluster type. There are different cluster types such as Spark, Hadoop, Kafka, ML Services and so forth.
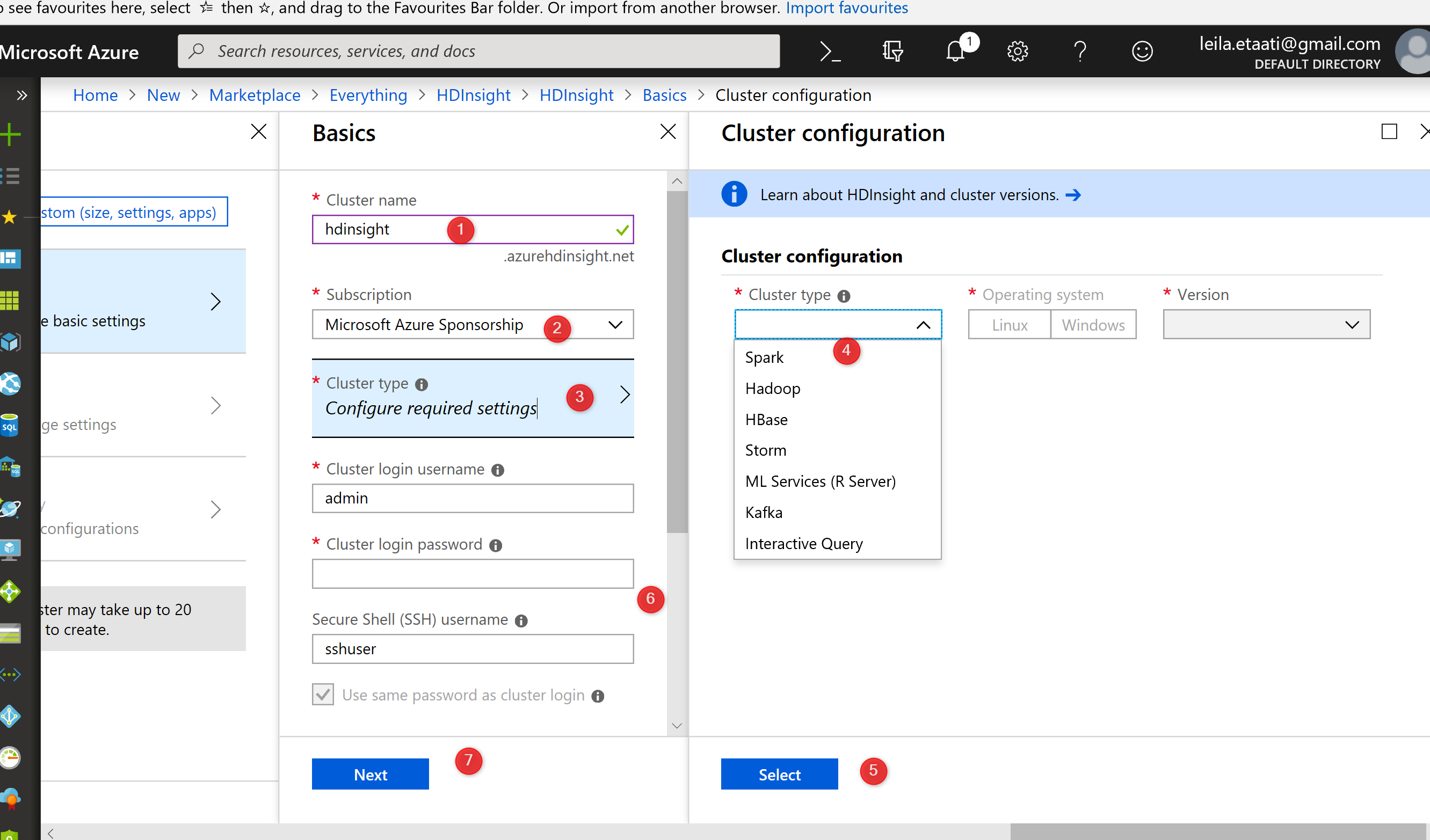
In the next step, you should identify the size and check the summary.
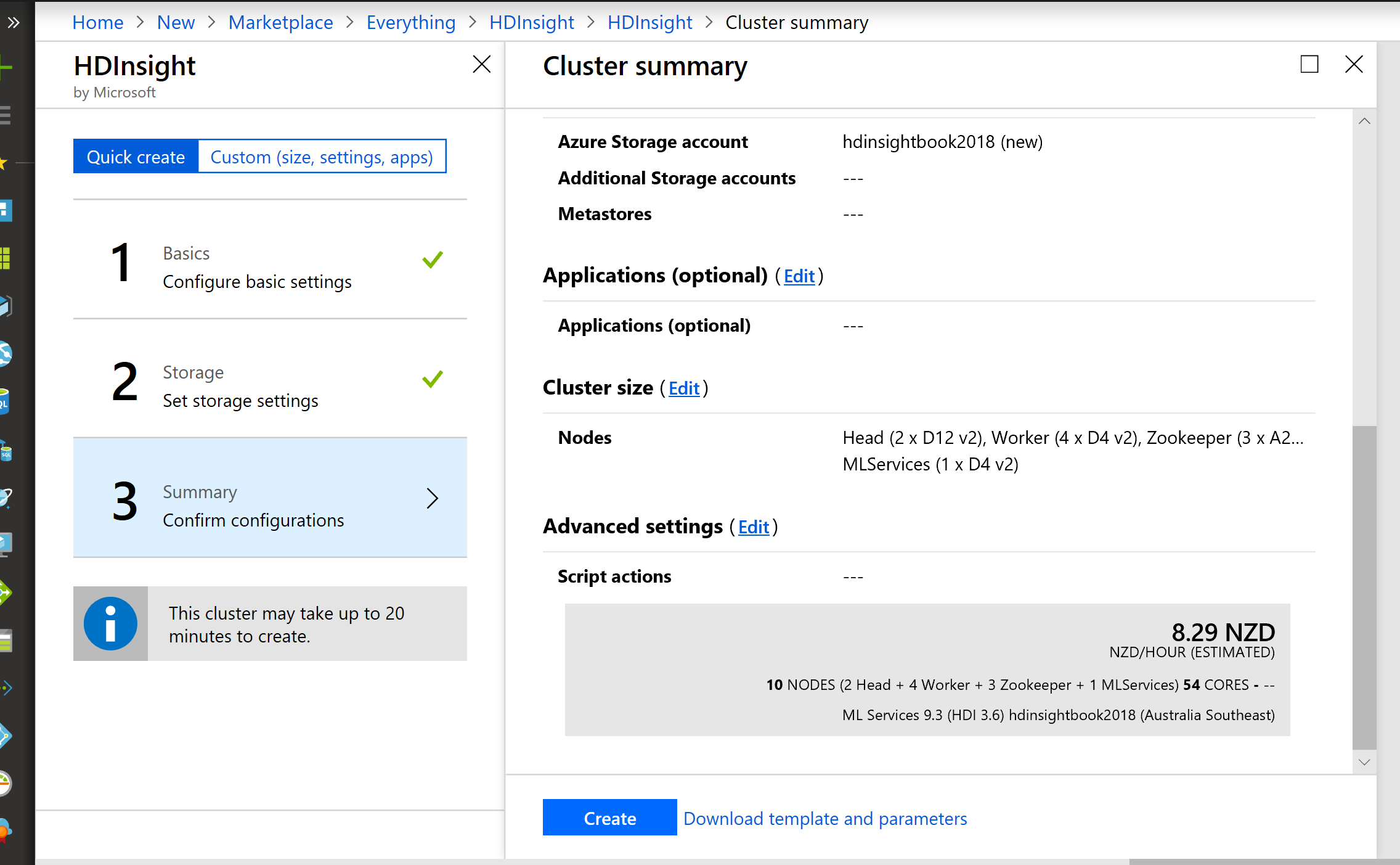
Creation of the HDInsight makes takes a couple of minutes. After creating an HDInsight component, on the main page, in the Overview section, select the Cluster Dashboard
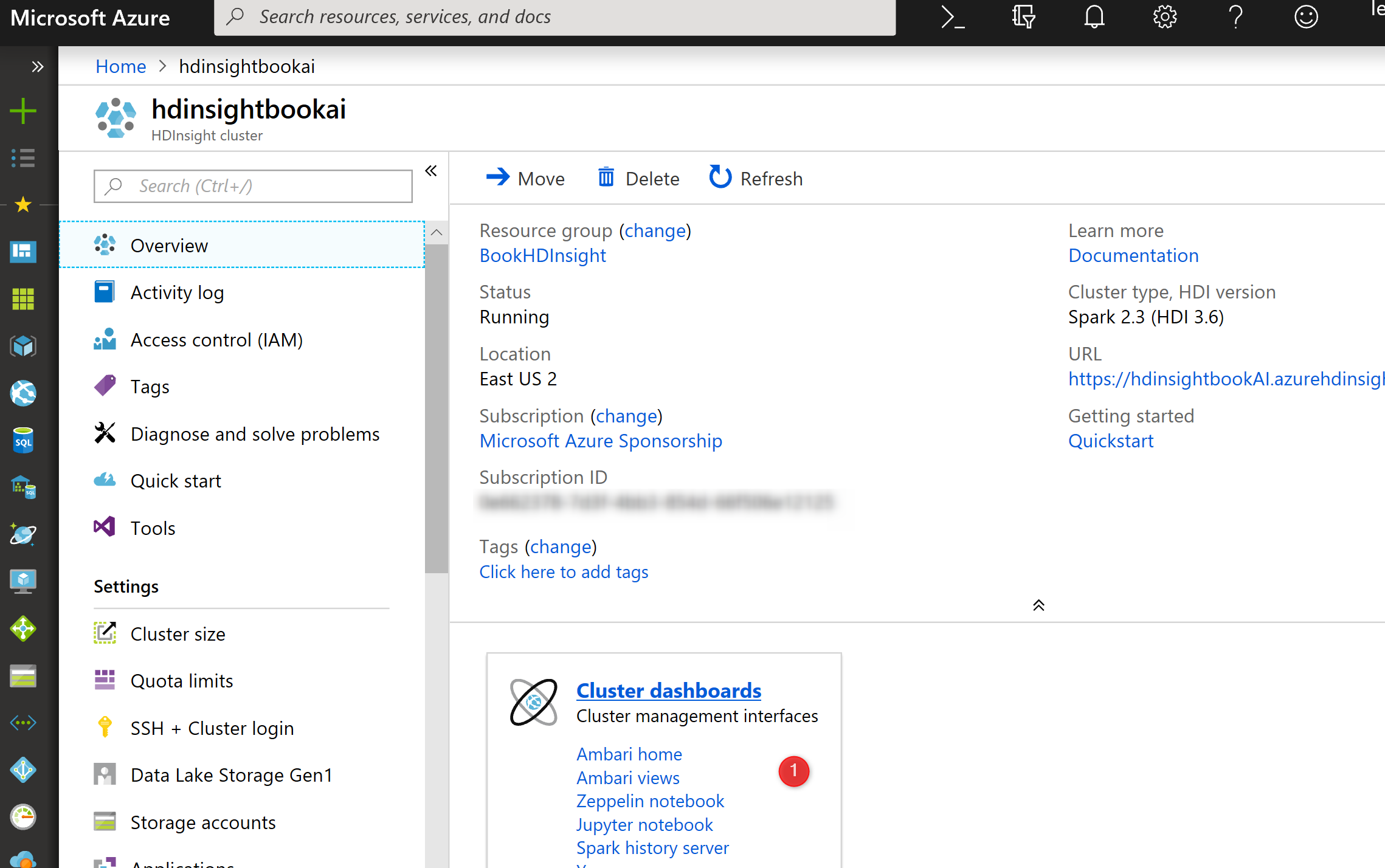
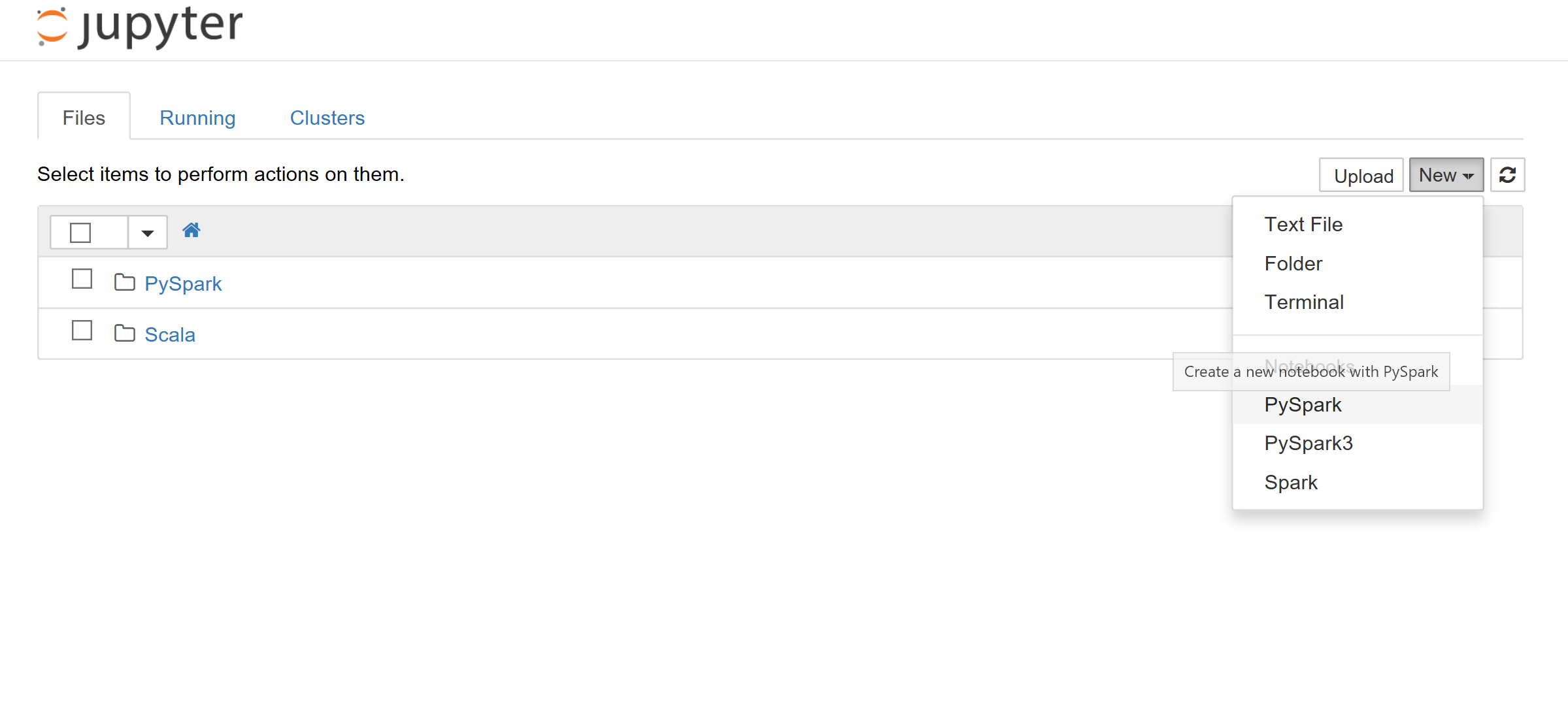
Next, select the Jupyter Notebook, on the new page, choose the New option.
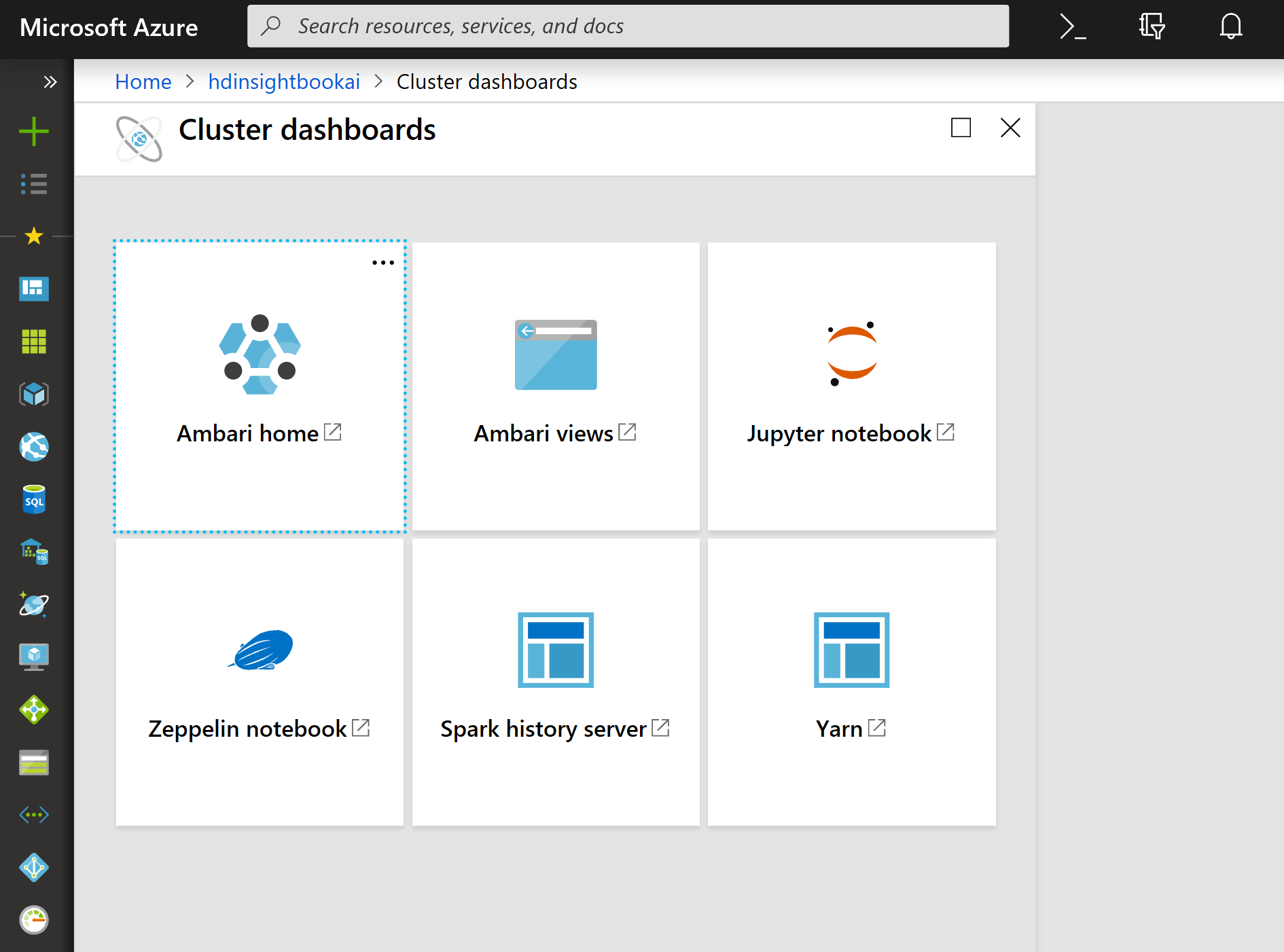
As you can see in the below figure there are different options such as PySpark, PySpark3, and Spark notebook. You can write the python code in all of them. After creating the new page for Spark, there is a need to log in with the username and password that you provided for creating the HDInsight component. The Jupyter environment is like a notebook and so like Azure Databricks environment. Also, there is a possibility to write the code there and run the whole cell to see the result.
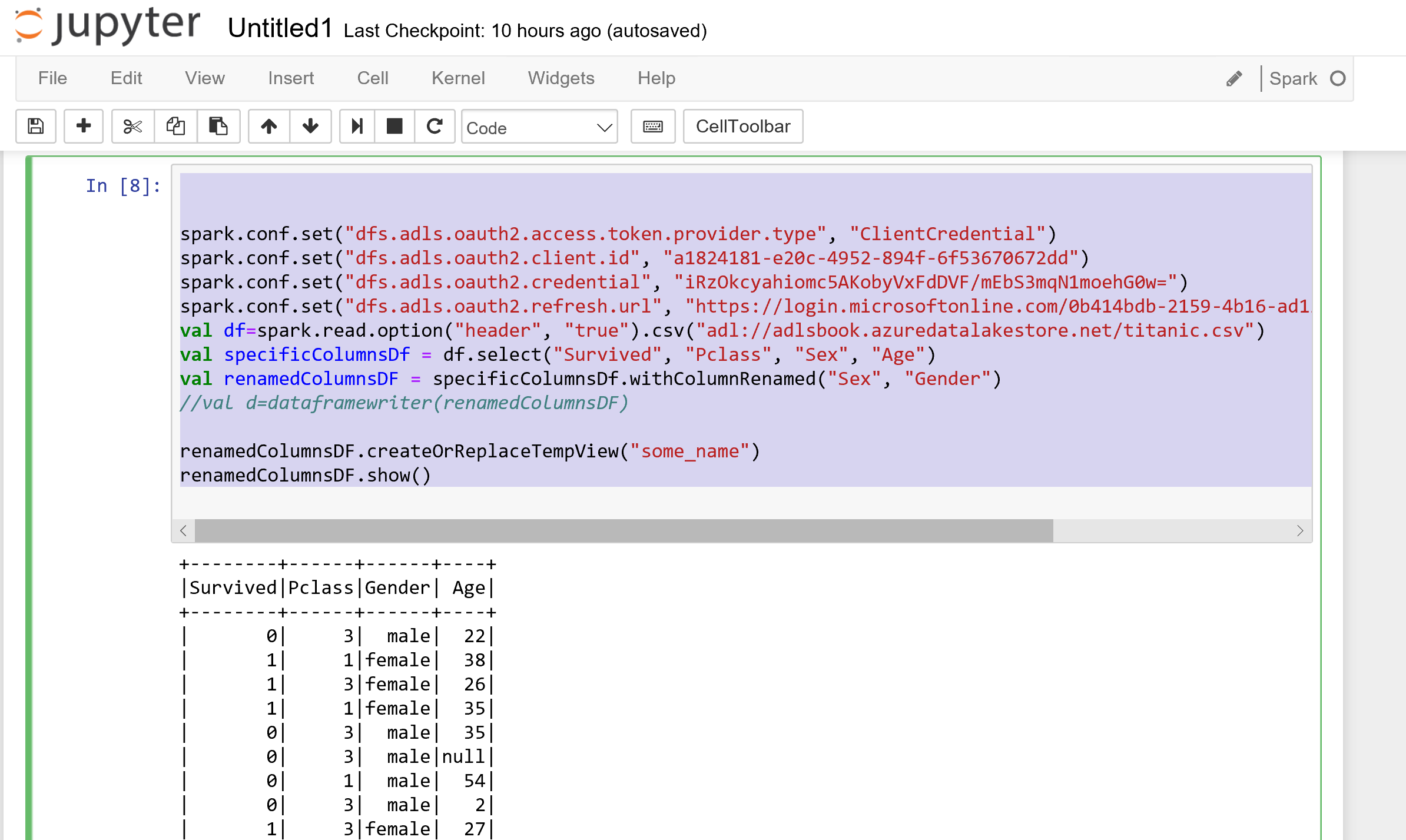
There is a possibility to fetch the data from other Azure components such as Azure Data Lake Store Gen1. To do that you need to run the below codes (In Databricks we run the same code).
spark.conf.set(“dfs.adls.oauth2.access.token.provider.type”, “ClientCredential”)
spark.conf.set(“dfs.adls.oauth2.client.id”, “a1824181-e20c-4952-894f-6f53670672dd”)
spark.conf.set(“dfs.adls.oauth2.credential”, “iRzOkcyahiomc5AKobyVxFdDVF/mEbS3mqN1moehG0w=”)
spark.conf.set(“dfs.adls.oauth2.refresh.url”, “https://login.microsoftonline.com/0b414bdb-2159-4b16-ad13-b2d54a1781da/oauth2/token”)
val df=spark.read.option(“header”, “true”).csv(“adl://adlsbook.azuredatalakestore.net/titanic.csv”)
val specificColumnsDf = df.select(“Survived”, “Pclass”, “Sex”, “Age”)
val renamedColumnsDF = specificColumnsDf.withColumnRenamed(“Sex”, “Gender”)
renamedColumnsDF.createOrReplaceTempView(“some_name”)
renamedColumnsDF.show()
There is a possibility to do machine learning in Jyputer Notebook Spark as well. To see an example, follow the tutorial in reference number 4 [4].
[1] https://docs.microsoft.com/en-us/azure/hdinsight/
[2] https://docs.microsoft.com/en-us/azure/hdinsight/spark/apache-spark-jupyter-spark-sql



