
A recent post on a community.powerbi.com forum asked if it was possible to show a slicer of months, and configure a report so when a user selects a single month from the slicer, visuals will show data for a date range relative to that selection e.g. the preceding 10 months of data.
If a user selects March 2017, visuals will display a date range between May 2016 and March 2017. If a user then selects December 2016 on the slicer, visuals will update to show data for a date range between March 2016 and December 2016.
The challenge is if the “Month” slicer uses a field from the data table used to generate values for the visuals it will restrict the rows from the data table available to generate the axis, that no amount of fiddling with row or filter context can over-ride. The same is true when using a field for the slicer from a related table.
A way to solve this is to use a field for the slicer from a table that has no relationship with the data table.
Lets generate two tables of dummy data to demonstrate.
Table 1 : This will generate a date table that we can use for the slicer.
Dates =
ADDCOLUMNS(
ADDCOLUMNS(
CALENDAR("2016-01-01",TODAY()),
"Month" , DATE(
YEAR([Date]),
MONTH([Date]),
1
)
),
"Month Inverse Sort Col" , -INT([Month])
)
If you cut and paste this code into a blank Power BI Desktop file as a New Table, this will give you a table called ‘Dates’.
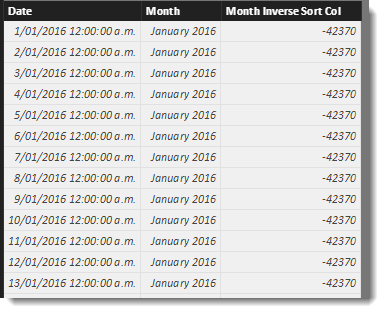
Table 2 : This table will generate some fake sales to be visualised.
Data Table =
ADDCOLUMNS(
GENERATE(
CALENDAR("2012-01-01",TODAY()) ,
SELECTCOLUMNS(GENERATESERIES(1,2),"Units Sold",RANDBETWEEN(1,5))
),
"Month" , DATE(YEAR([Date]),MONTH([Date]),1))

This calculated table will generate a table with 2 sales per day between 1 January 2012 and the current day. It generates a random number between 1 and 5 in each row for the [Units Sold] column. The third column [Month] is the start of the month value relevant for each [Date]. This is the column we will use in the axis of a visual. This code can be tweaked a number of ways to control when the data table starts and finishes, how many rows per day, as well as the parameters for the random number used for [Units Sold].
The important thing is to make sure there is no relationship between these two tables. Power BI Desktop may attempt to link the two tables, so delete the relationship if this happens.
The final piece of code is to create a calculated measure based filter that will be used to help select the date range. Add the following calculated measure to the model. This measure can be added to either table. It will not impact the result.
Measure as filter =
VAR MonthsToLookBack = 10
VAR DataTableDate = MIN('Data Table'[Date])
VAR DateTableDate = MIN('Dates'[Date])
VAR DateAddAlternative = EDATE(DateTableDate,-MonthsToLookBack)
RETURN
IF(
(DataTableDate < DateTableDate) &&
(DataTableDate > DateAddAlternative) ,
-- FLAG IF TRUE --
1
)
A breakdown of the code in the calculated measures is as follows:
The MonthsToLookBack variable stores a value that will be used to control how many months back from the slicer selection will be used for the date range. This variable could be substituted with a What-If parameter if you’d like to provide more flexibility to your end users.
The DataTableDate variable will store the minimum value of the [Date] field from the ‘Data Table’ for each bucket on the axis. This will effectively control which rows from the ‘Data Table’ table will be used by the calculated measures on the visual.
The DateTableDate variable will store the value selected from the Slicer. The MIN function is used to guarantee a single date value. If the user selects January 2017 from the slicer, it will be this value that gets stored in this variable.
The DateAddAlternative variable uses the EDATE function to perform a DATEADD like jump back in months using the MonthsToLookBack variable to determine the range. The DATEADD function can only work with a column reference and cannot use the output of a MAX function.

The key features of the report are that the visual uses the [Month] column from the ‘Data Table’ and not the month column from ‘Dates’. The [Measure as filter] calculated measure is added to the filter pane and set that it must have a value of 1. Then add measures to Values section of the visual. This example uses a simple SUM over the [Units Sold] column.
The next task is to add a slicer. In this case, drag the [Month] column from the ‘Date’ table to a blank area of canvas and set the visual to be a slicer. In my version of Power BI Desktop I have set the slicer to be a List and formatted the [Month] column from the Date Table using the Format option in the Modeling table to set the field to be (MMMM yyyy).
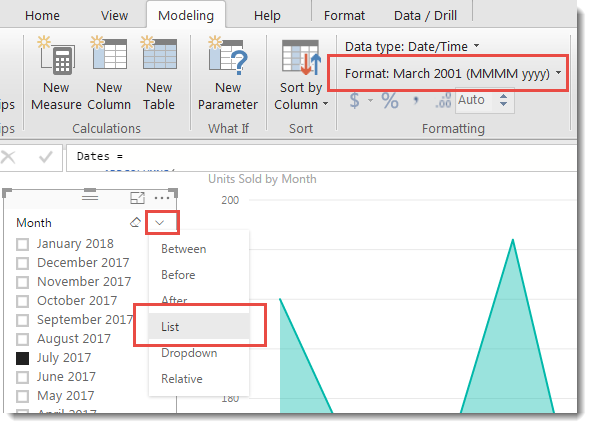
This means when different months are selected from the slicer, the date range shown in visuals will be for a date range relative to the selection on the slicer.
This will also work if the ‘Data Table'[Date] field is used on the axis of the visual.
Here is an image of the relationship view for the model.
Finally the [Month Inverse Sort Col] column that as added to the ‘Date’ table back in step one, is used to allow the month values in the slicer to appear in descending order, so the current month will always be at the top of the list. This works by creating a column with a negative integer for each month value. Newer months will have lower values. So when the [Month] column in the ‘Date’ table is set to use this column to sort by, the order of months in the slicer have the newest months at the top of the list.
The PBIX file used in this blog can be downloaded here:
https://1drv.ms/u/s!AtDlC2rep7a-oX1aDVEJ6Ty7oTvy




I also have put a similar question at Power BI form, and get a good solution
In my case I want to get data from 12 months back, instead of 10.
This is the post I create, and where I get the answer:
https://community.powerbi.com/t5/Desktop/Filter-of-some-period-and-get-the-information-from-the-previous/td-p/325460
Thank you very much!!! This solution is excellent! I transformed your example, applying the measure to a second Calendar table that works on reports filtering all the fact tables “behind the scenes” 🙂
Is there any way to have this show the month in the slicer instead of the previous month? I’ve tried everything I can think of and it isn’t working.
And of course I figure it out right after I say something.
Thanks for the post, this is a very slick idea. When I apply it to my model, switching to a matrix view, it works until I add rows. At that point it displays no information with the measure as a filter actively filtering for “1”. Any suggestions?
Hi: I have a question based on this solution. Is there a way to use the Calendar table related to fact table I mean, the same solution but with no a secondary date table. IS there a way to do that?
I have a report with year-quarter and the filter can filter different charts and tables. I would like to have only one filter and create this same logic based on that filter. Do you know if this is possible?
Thank you so much for your help
Erica