
A recent post on the Power BI community website asked if it was possible to compress a group of numbers into text that described the sequential ranges contained within the numbers. This might be a group of values such as 1, 2, 3, 4, 7, 8, 9, 12, 13: (note there are gaps) with the expected result grouping the numbers that run in a sequence together to produce text like “1-4, 7-9, 12-13”. Essentially to identify gaps when creating the text. This seemed like an interesting challenge and here is how I solved it using DAX.
First I created some working data in a clean Power BI Desktop model by creating the following calculated table.
Table = GENERATESERIES(1,50)
This provides a single column table with 50 rows in a sequence. I use the ‘Table'[Value] field in a slicer and disabled the single select formatting option so I could click a series of numbers.
The image below shows the slicer with some values selected AND it shows the text generated by the finished measure.
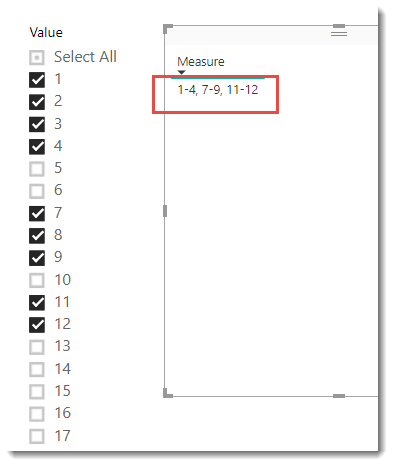
Now let’s take a look at the measure. For readability, I break the measure into steps using variables. I use a very unimaginative naming system but will describe the point of each variable as I go.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
Variable A will store a table expression that only contains rows from ‘Table’ that have been selected using the slicer. The table expression stored in A will only have a single column and only as many rows as there are selections on the slicer. In my example, that means just 9 of the 50 rows.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
Variable B will store every value from the original ‘Table’. This is mainly done for readability when I start to play table A off against table B. Table B will contain 50 rows (1 through 50).
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
Variable GAPS creates a list of values that exist in B, that doesn’t exist in A. This will create an inverse list of values and should be the numbers from our ‘Table’ that aren’t selected. The column in this table is renamed. The number of rows in A + GAPS should always = 50 in this case.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
VAR C = SELECTCOLUMNS(A,"End Num",[N])
Variable C makes a copy of A but renames the only column in the table to be “End Num”.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
VAR C = SELECTCOLUMNS(A,"End Num",[N])
--- Get a bunch of possible sequences
VAR D = GENERATE(
A,
FILTER(
C,
[End Num] >= [N])
)
Variable D now creates a Cartesian join for every row in variable A with every row in variable C, but only where the value in C is greater than the value in A and at this point will look something like this:
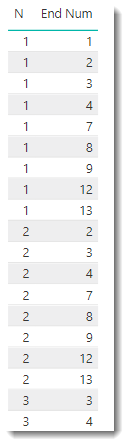
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
VAR C = SELECTCOLUMNS(A,"End Num",[N])
--- Get a bunch of possible sequences
VAR D = GENERATE(
A,
FILTER(
C,
[End Num] >= [N])
)
-- Make a list of sequences WTIH a gap in them
VAR E = SELECTCOLUMNS(
GENERATE(
D ,
FILTER(
GAPS,
[Gap Value]>=[N] && [Gap Value] <= [End Num])
),
"N1",[N] ,
"N2",[End Num] +0 )
Variable E now makes a list of the number ranges (start/finish) generated in variable D, but keeps sequences that DO contain a value stored in the GAPS variable. This is looking for bad sequences that we want to discard as we only want to keep sequences without gaps.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
VAR C = SELECTCOLUMNS(A,"End Num",[N])
--- Get a bunch of possible sequences
VAR D = GENERATE(
A,
FILTER(
C,
[End Num] >= [N])
)
-- Make a list of sequences WTIH a gap in them
VAR E = SELECTCOLUMNS(
GENERATE(
D ,
FILTER(
Gaps,
[Gap Value]>=[N] && [Gap Value] <= [End Num])
),
"N1",[N] ,
"N2",[End Num] +0 )
VAR F = EXCEPT(D,E)
Variable F takes our list of every data range pair that we stored in variable D, but now remove the bad sequences identified using variable E. None of the pairs now stored in variable F will have gaps, but there will be overlaps.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
VAR C = SELECTCOLUMNS(A,"End Num",[N])
--- Get a bunch of possible sequences
VAR D = GENERATE(
A,
FILTER(
C,
[End Num] >= [N])
)
-- Make a list of sequences WTIH a gap in them
VAR E = SELECTCOLUMNS(
GENERATE(
D ,
FILTER(
Gaps,
[Gap Value]>=[N] && [Gap Value] <= [End Num])
),
"N1",[N] ,
"N2",[End Num] +0 )
VAR F = EXCEPT(D,E)
VAR G =
SELECTCOLUMNS(
GENERATE(
F,
FILTER(
SELECTCOLUMNS(
f,
"D",[N] ,
"E",[End Num] +0
) ,
([D]>[N] && [D]<=[End Num])
||
([E]>=[N] && [E]<[End Num])
)
)
,"D",[D],"E",[E])
Variable G now joins variable F back to itself with some filter criteria to help look for pairs in F that are overlapped by another pair in the list, either by the pair starting before, or ending after. Pairs in F that are NOT overlapped by another pair do not make this list. It is these pairs that we eventually want to keep, but if we identify the “bad” pairs first, it makes the next step easier.
Measure =
VAR A = SELECTCOLUMNS('Table',"N",[Value])
VAR B = ALL('Table'[Value])
VAR GAPS = SELECTCOLUMNS(EXCEPT(B,A),"Gap Value",[Value])
VAR C = SELECTCOLUMNS(A,"End Num",[N])
--- Get a bunch of possible sequences
VAR D = GENERATE(
A,
FILTER(
C,
[End Num] >= [N])
)
-- Make a list of sequences WTIH a gap in them
VAR E = SELECTCOLUMNS(
GENERATE(
D ,
FILTER(
Gaps,
[Gap Value]>=[N] && [Gap Value] <= [End Num])
),
"N1",[N] ,
"N2",[End Num] +0 )
VAR F = EXCEPT(D,E)
VAR G =
SELECTCOLUMNS(
GENERATE(
F,
FILTER(
SELECTCOLUMNS(
f,
"D",[N] ,
"E",[End Num] +0
) ,
([D]>[N] && [D]<=[End Num])
||
([E]>=[N] && [E]<[End Num])
)
)
,"D",[D],"E",[E])
VAR H =
SELECTCOLUMNS(
EXCEPT(F,G),
"Output",
IF(
[N] = [End Num],
[N],
[N] & "-" & [End Num]
)
)
RETURN CONCATENATEX(H,[Output], ", ")
The last variable H, uses the EXCEPT function to only return pairs from variable F that were not identified as bad (variable G). The IF function is used to decide if a hyphen is needed, or if the pair starts and stops at the same value.
The CONCATENATEX function finally pivots the list stored in variable H that looks like :

Into

The PBIX file can be downloaded here, and allows you to play with a slicer and see the effect it has on the calculated measure on the same canvas.
This approach could be tweaked to use dates in place of numbers so you can create a text-based description of your date ranges. This might be useful in a report title especially given that it can update based on user interaction with slicers.
The code can also simply run over a column of numbers (or dates) without the need for a slicer. I found the question interesting and enjoyed coming up with a solution that I’m sure might be helpful to someone after something similar.




Well done, on the surface it seems like a simple thing, but the implementation involves a bit of abstract thinking. I can see that this is the sort of feature that I might be asked to create.
I’m thinking that if I was working on something like this I would probably use calculated tables to debug the output of each step to make sure that I could really understand what each of the steps was achieving.
Hi Andrew,
I made good use of calculated tables as a technique to debug and it certainly made it faster and easier to generate the final code.
I’m glad you liked the article.
Hi Phil, can you send the link of the post on the Power BI community website?
I think i have another alternative and i want to share it.
Thanks,