
In the previous posts from Part 1 to 7, I have explained how to do machine learning with Azure ML. I have explained some of the main components in Azure ML that helps us to do data wrangling, train the model, feature selection and evaluating the result.
The data cleaning such as SQL transformation, select specific columns, remove missing values, Edit meta data, and normalize data. Also, I have explained how to find relevant attributes using Feature Selection Feature to identify which feature are more important than the other. Then, I shown how to split data using Split Data component to train and test the model. Then, I show how to train and test the model. Moreover, in the last post I have explained the evaluation process Evaluate Model.
In this post, I am going to show the another way for enhancing the model as “Try Different parameters“. Each algorithms has its own parameters. Choosing the right Parameters for each dataset and algorithms can improve the accuracy. In Azure ML, there is a component name “Tune Hyper Parameters” . This component will help us to better improve the accuracy.

“Tune Model Hyperparameters” get two inputs: one for data and for aim of the training model, which comes from the split data component, another one from algorithm. Actually this component can be replacement of Train Model.
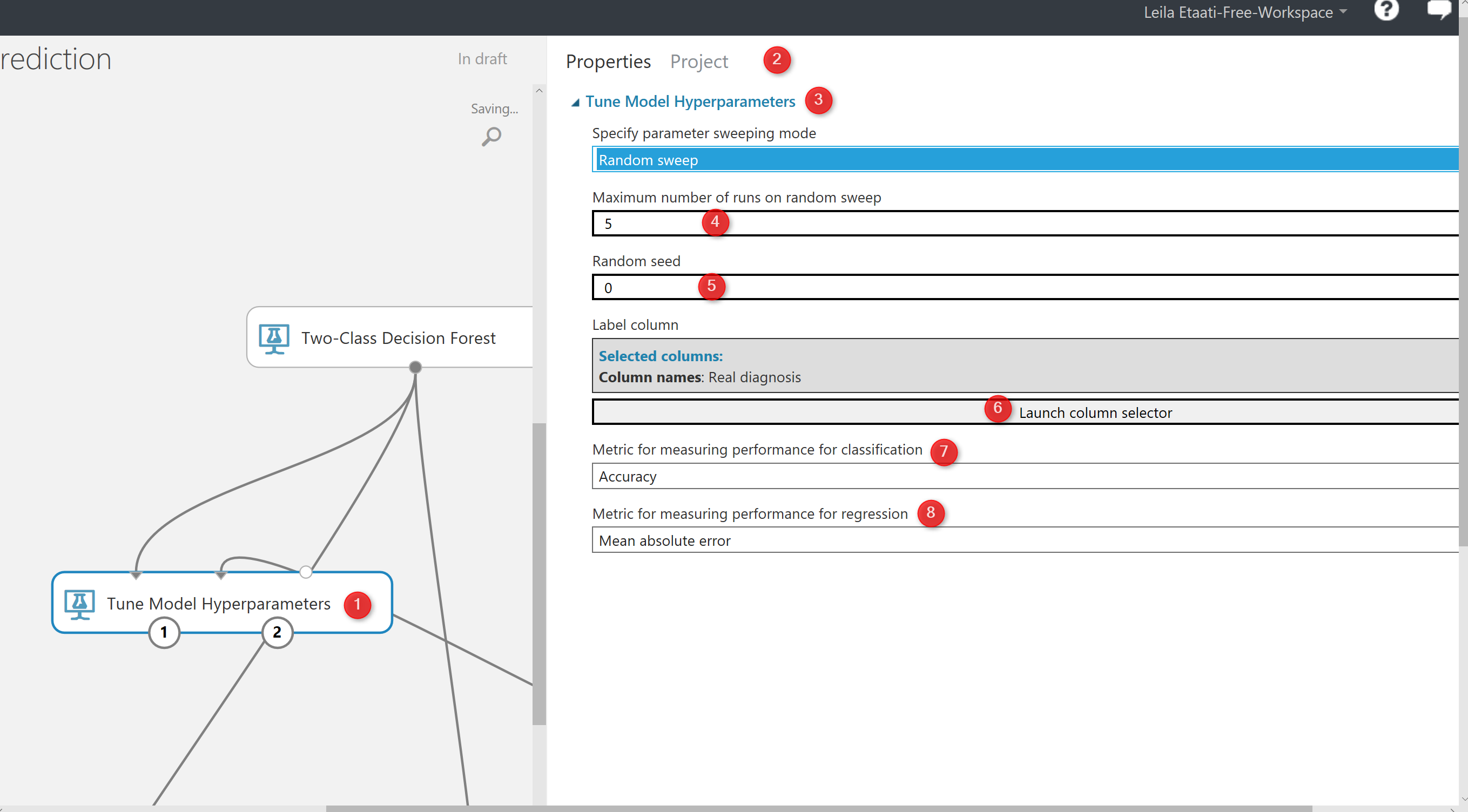
if you click on the component, in the right side of experiment area, you will see the properties panel. as you can see in the below picture, by clicking on the “Tune Model Hyperparameters“. We have couple of the parameters that we should set them up. the first parameter is about the method that we want to try different parameters value. In the below picture, first I have choose the “Random Sweep“. It performs a set number of training iterations by randomly choosing parameter’s value. So, this component will try different parameter’s value randomly and train the model based on them(Number 3). the second parameters to set up is (number 4) how to specify number of times we have to run the code. This help us to identify with which parameters what accuracy we will have.
Then in the number 6, we have to specify the item we are going to train the model and identify which column we are going to predict. For this example we choose “Real Diagnosis“. In number 7 and 8, we have to specify the metric for measuring the model performance. if the problem is classification, then we need go for accuracy or recall measures. If the model is about predicting a value and we using the regression models, then we should select one of the item from number 8 in the picture.
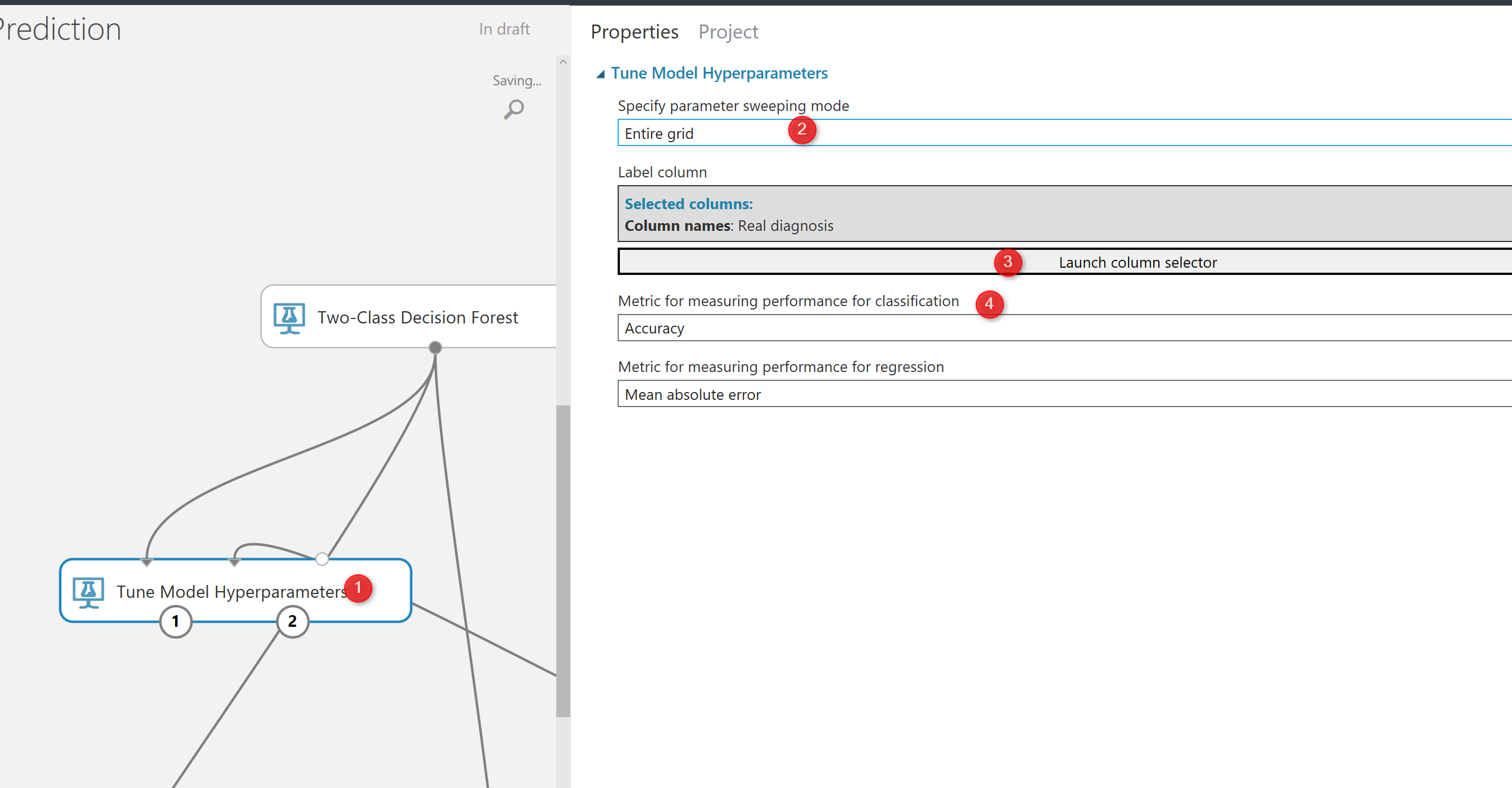
The other option is to test all the parameters against each other that means trying different parameters combinations and identifying the best of them. we call this approach as trying “Entire Grid“. as you can see in the below picture in number 1, we select “Entire Grid” as the approach to find the best parameters. as you see here we are not to specify the number of times we run the training model.
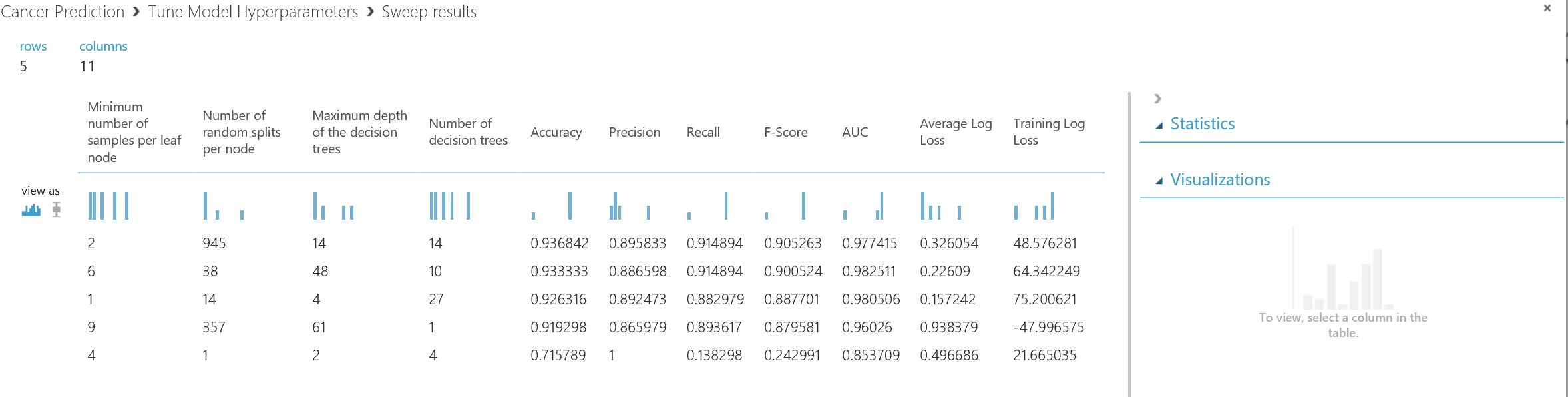
Now, we setup the code, we are going to just run the experiment. after run the experiment you will see we have two output for the “Tune model Hyperparameters”. The first output at the left side has the dataset that shows the parameters value and relative accuracy to them (See below picture).
As you can see in the below picture, the first4 first column are parameters for decision forest algorithm that we have. Such as number of sample per leaf, depth of the decision tree, number of decision tree. as you can see from the below picture, we have 6 other column that shows the accuracy, Precision, Recall, and so forth value that we got based on the selected parameters. so it help us to assign better parameters for our model.
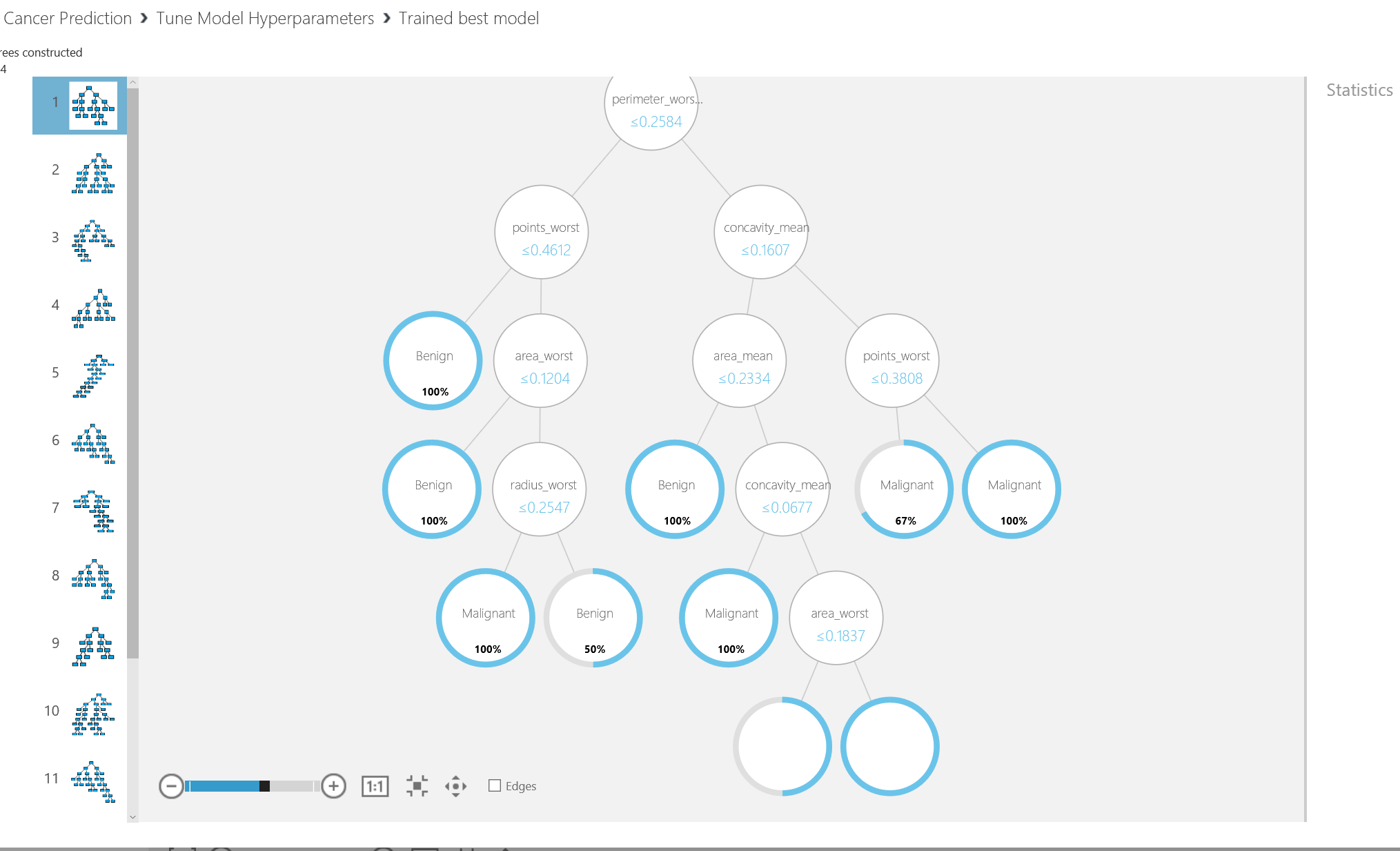
The other output of the “Tune Model Hyperparameter” is to visualize of the decision tree (see below picture). So you see the different models that has been trained.
In next post I will talk about the “Cross Validation” component that is another way of enhancing the accuracy by trying different datasets.
https://msdn.microsoft.com/library/azure/038d91b6-c2f2-42a1-9215-1f2c20ed1b40



