
You can have a distinct count calculation in multiple places in Power BI, through DAX code, using the Visual’s aggregation on a field, or even in Power Query. If you are doing the distinct count in Power Query as part of a group by operation, however, the existing distinct count is for all columns in the table, not for a particular column. In this article, I’ll show you a method you can use to get the distinct count of a particular column through the Group By transformation in Power Query component of Power BI.
Why Power Query Transformation?
Before we start, it is important to know why in some scenarios, you might consider using Power Query for a transformation such as Distinct Count. Having a distinct count in Power BI using DAX is great. However, sometimes this calculation can be done as a pre-calculation, and only the aggregated result is what needed at the end, the details are not needed. If the dynamic calculation is not part of the requirement, then Power Query can be a good consideration for the implementation. To learn more about when to choose M (Power Query), or when to choose DAX for a calculation, read my article here.
What is Group By?
Group By is a transformation which groups the result based on one or more fields, and provide an aggregated result from the existing table.
Consider the table below, which is the FactInternetSales table. this table has multiple records per each CustomerKey;
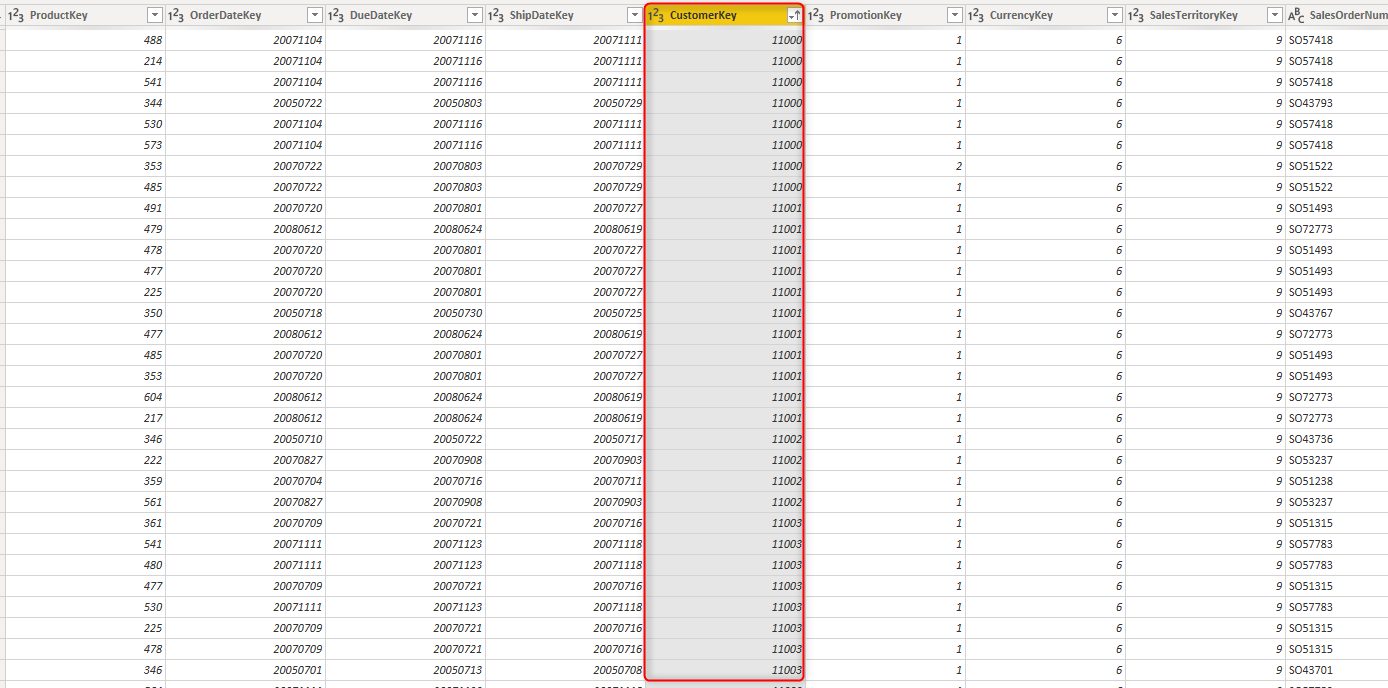
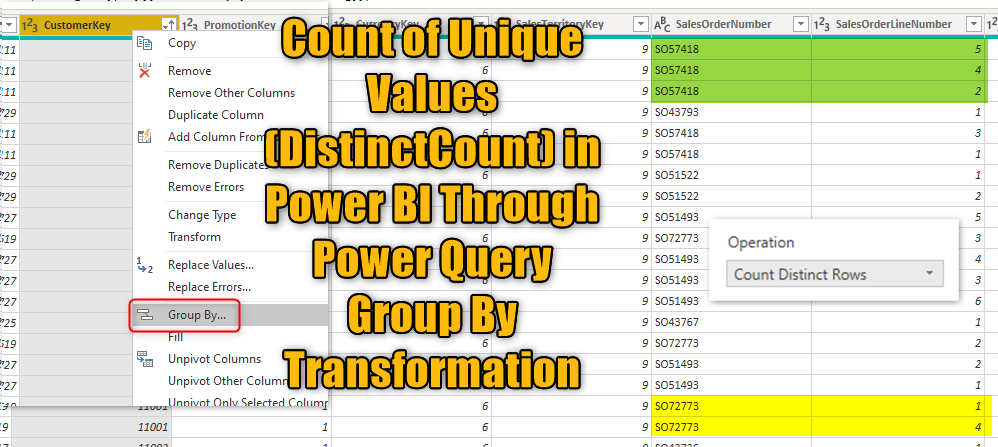
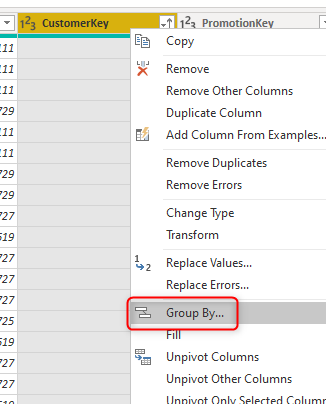
You can use Group By on a table like below on the CustomerKey (this table has multiple records per each CustomerKey);
And the result then would be a table with one CustomerKey per row;

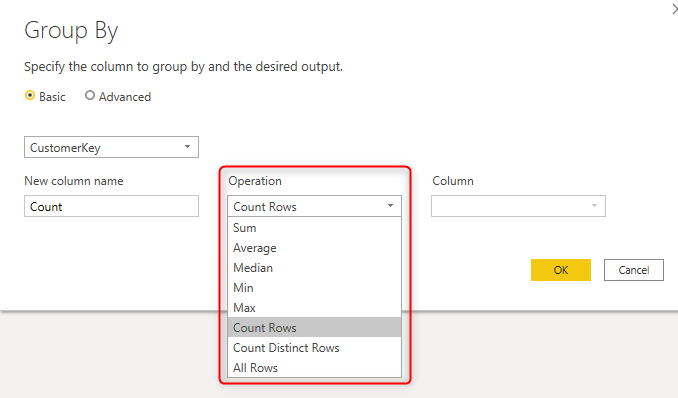
Besides the Group by field, you can also have aggregated results from the other parts of the table, which can be determined in the Group By Configuration window;
The Limitation of Distinct Count in Group By
The list of operations in the Group By aggregation, also useful, but it is limited. I previously wrote about a scenario that you can use to get the FIRST or LAST item in the group. The limitation that I want to point out here is the DistinctCount. The option that you see in the operations is Count Distinct Rows, which means for all columns except the Group By Column
This operation is most likely to return the same result as the Count Rows. It might be only different if you really have a duplicate row with all columns having exactly the same value.
What is usually more useful is the distinct count of a specific column. For example, I am interested to know how many unique SalesOrderNumbers I have for each customer. and that cannot be achieved with a count of rows, because there might be multiple records even per one SalesOrderNumber because the OrderLine information is also in the table;
You can see some examples of such a scenario in the below screenshot:
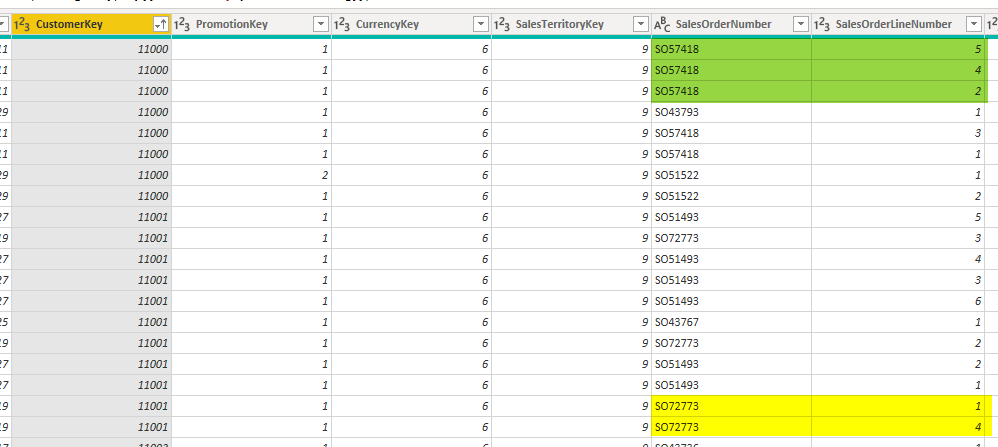
so the challenge is how to do Distinct Count for the SalesOrderNumber column when using Group By.
Adding Distinct Count to Group By
The Power Query function for a list of distinct values of a column is List.Distinct, which you can use it as below:
List.Distinct(<column name>)
If you use the Count Distinct Rows in the group by;
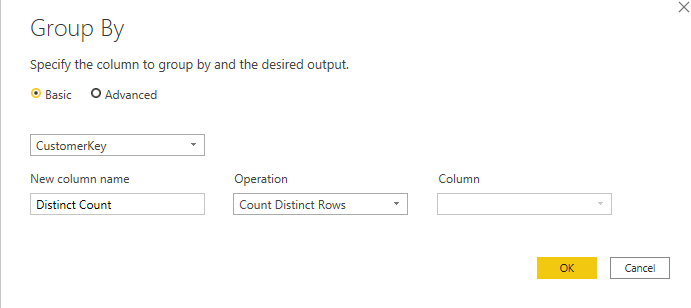
it, however, uses the Table.Distinct function, which ends up with something like below:
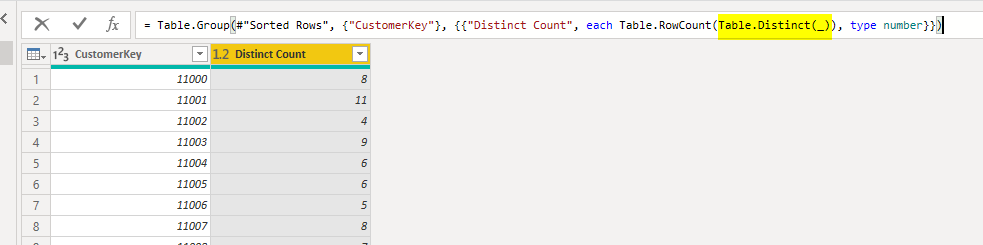
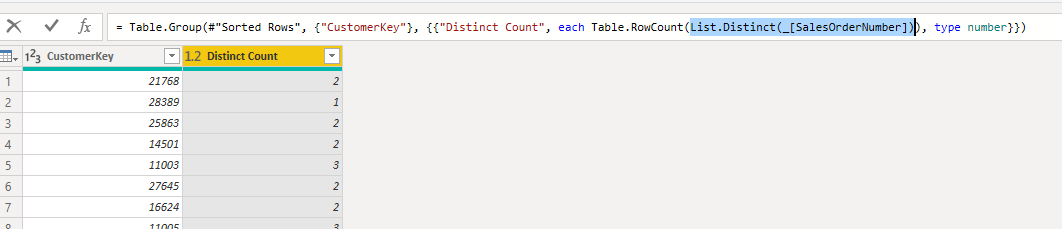
Table.Distinct is used inside the Table.RowCount function. The (_) input for the Table.Distinct is the input parameter from the group by action, which is the sub-table for each group.
you can replace that line of code with below;
= Table.Group(#'Sorted Rows', {'CustomerKey'}, {{'Distinct Count', each Table.RowCount(List.Distinct(_[SalesOrderNumber])), type number}})
And that will give you the distinct count for the SalesOrderNumber columns.
this happens by replacing the:
Table.Distinct(_)
with
List.Distinct(_[SalesOrderNumber])
The _ means the input table, and the SalesOrderNumber is the column that we want the unique values out of it, used inside the List.Distinct, the result is now the distinct count;
As I mentioned before in my other Power Query articles, once you know your way to writing M scripts (even part of the script), then Sky is the limit for the data transformation in Power BI.
Download Sample Power BI File
Download the sample Power BI report here:
Video




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Hi Reza,
I followed the instructions in this blog and I am still getting all rows instead of distinct count of a column. I have spent hours and hours and literally copied it down to the T.on this and I can’t seem to figure out what the issue is. Would you mind advising what may be the issue with my code below?
= Table.Group(#”Changed Type”, {“VISIT_START_TIMESTAMP”, “VISIT_END_TIMESTAMP”, “RECV_SEX_CD”, “VISIT_TYPE_CD”, “VISIT_STATE_CD”, “APP_TYPE_NAME”, “APPOINTMENT_IND”, “OFFLINE_REFER_RESULT_IND”, “NDC1_ID”, “NDC2_ID”, “NDC3_ID”, “NDC4_ID”, “NDC5_ID”, “PRIMARY_DIAG_CD”, “SRC_CUST_ID”, “Age Group”}, {{“Members_Count”, each Table.RowCount(List.Distinct(_[SRC_MBR_ID])), type number}, {“Visits_sum”, each Table.RowCount(_), type number}, {“Mbr_Ratings_sum”, each List.Sum([RATED_BY_MBR_SCR]), type number}})
Hi Sal,
I can’t give you an exact answer without seeing what are columns of your table,
but with the first look at your expression, I see that your group is based on multiple columns: “VISIT_START_TIMESTAMP”, “VISIT_END_TIMESTAMP”, “RECV_SEX_CD”, “VISIT_TYPE_CD”, “VISIT_STATE_CD”, “APP_TYPE_NAME”, “APPOINTMENT_IND”, “OFFLINE_REFER_RESULT_IND”, “NDC1_ID”, “NDC2_ID”, “NDC3_ID”, “NDC4_ID”, “NDC5_ID”, “PRIMARY_DIAG_CD”, “SRC_CUST_ID”, “Age Group”
this is probably all columns in your table? in that case, your grouping is at the same granularity of your table anyway! it looks like that you are not grouping at all. You should only select the columns that you want to be your group headers,and then do the group by.
Cheers
Reza
Hi Reba,
I did the same but it takes much longer time to refresh the data. Everything works fine before applying group by and finding distinct values of multiple columns. Amount of data I am dealing with is 9M. Could you please advise how I can improve the performance.
Hi Karthik
I need to have your table and the full M expression of your query to be able to help with the performance.
Cheers
Reza
Reza, is it possible to simply add a column that will show the distinct count based on another column, without using Group By? I want all records/rows to remain in my results, but I need to know how many unique items there are based on a particular field.
Hi Jerry.
You can use a profiling query. here is an example
Cheers
Reza
Hi Reza,
Amazing blog. A follow-up question. The distinct count also calculates the null value. How can we add that extra code to remove the null values from count.
Thanks!
Thanks 🙂
You can add an step before that which is removing empty values from the column. that would get rid of nulls before the distinct count
Cheers
Reza
Thanks Reza!