
All source files for this article can be downloaded here :
A good friend and member of my local Power BI User Group contacted me recently to ask if I might help with a problem he trying to solve in DAX. He was keen to track the value of items purchased over time in chronological order, and when sales were made, the older items are sold first using the value at the time the items were purchased.
The trick is that the quantities sold, may not align with the quantities purchased.
Imagine the following purchases have been made
- Day 1: 4 items purchased @ $1.10 per unit
- Day 2: 4 items purchased @ $1.20 per unit
- Day 3: 4 items purchased @ $1.30 per unit
- Day 4: 9 items SOLD @ $2.50 per unit
- Day 5: 4 items purchased @ $1.50 per unit
- Day 6: 4 items purchased @ $1.60 per unit
- Day 7: 8 items SOLD @ $ 3.00 per unit
The idea is to create a calculation for the day’s items were sold. The sale value of the transaction on day 4 was 9 items x $2.50 = $ 22.50.
The cost component is made up of three parts.
- four of the items come from day 1 (4 x $1.10 = $4.40),
- four from day 2 (4 x $1.20 = $4.80)
- only one item should be used from the stock purchased on day 3 (1 x $1.30)
When combined the total FIFO cost is $4.40 + $4.80 + $1.30 = $10.50. This represents a profit of +$12.00 for the transaction.
This is easy enough, however, the trick is how to manage the sale transaction on day 7. We have already used an item from the batch purchased on day three, so to calculate the correct cost for the 8 items sold, the components are the following :
- three come from the remaining items from day 3 (3 x $1.30 = $3.90)
- the next four use all items from the day 5 batch (4 x $1.50 = $6.00)
- only one item is used from the stock purchased on day 6 (1 x $1.60)
The solution I come up with uses calculated columns and keeps track of two sets of running totals. Each row contains the current value of each of the running totals, along with the previous total.
The dataset I used in the PBIX file is the following :
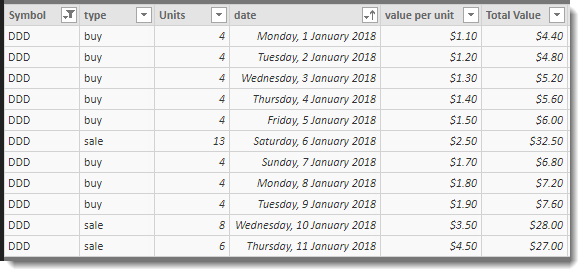
To start with, I add two columns that track the cumulative totals for units for each type = buy row.
The first calculated column is :
Cumulative Buy =
VAR mySymbol = 'Table1'[Symbol]
VAR myDate = 'Table1'[date]
VAR myFilter = FILTER(
'Table1',
'Table1'[Symbol] = mySymbol &&
'Table1'[type] = "buy" &&
'Table1'[date] <= myDate
)
RETURN
SUMX(
myFilter ,
'Table1'[Units]
)
While the second calculated column is slightly longer as it needs to determine the cumulative total for the previous value:
Previous Cumulative Buy =
VAR mySymbol = 'Table1'[Symbol]
VAR myDate = 'Table1'[date]
VAR myFilterTable =
FILTER(
'Table1',
'Table1'[Symbol] = mySymbol &&
'Table1'[date] < myDate &&
'Table1'[type] = "Buy"
)
VAR LastBuyDate =
MAXX(
myFilterTable ,
'Table1'[date]
)
VAR LastBuyValue =
MAXX(
FILTER(
myFilterTable,
'Table1'[date] = LastBuyDate
) ,
'Table1'[Cumulative Buy]) + 0
RETURN
IF(
'Table1'[type] = "Buy",
LastBuyValue
)
The dataset now looks as follows and the two new columns are the right-most columns:
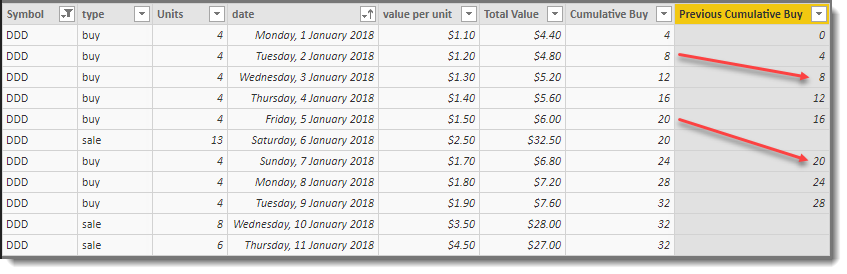
The dataset is pretty clean and only has a single “buy” record on any given day. If your dataset has more than 1 per day, a different column should be used to order the cumulative total.
The [Cumulative Buy] and [Previous Cumulative Buy] columns take care of the running totals and note that no deduction is made for the sale. This is deliberate and necessary for the end result.
The next step is to add two columns to keep track of the running totals of sales, in much the same way as the two “buy” columns.
Cumulative Sell =
VAR mySymbol = 'Table1'[Symbol]
VAR myDate = 'Table1'[date]
VAR myFilter = FILTER(
'Table1',
'Table1'[Symbol] = mySymbol &&
'Table1'[type] = "Sale" &&
'Table1'[date] <= myDate
)
VAR RunningTotal =
SUMX(
myFilter,
'Table1'[Units]
)
RETURN
IF(
'Table1'[type]="Sale",
RunningTotal
)
and
Previous Cumulative Sell =
VAR mySymbol = 'Table1'[Symbol]
VAR myDate = 'Table1'[date]
VAR myFilterTable =
FILTER (
'Table1',
'Table1'[Symbol] = mySymbol
&& 'Table1'[date] < myDate
&& 'Table1'[type] = "Sale"
)
VAR LastSaleDate =
MAXX ( myFilterTable, 'Table1'[date] )
VAR LastSaleValue =
MAXX (
FILTER ( myFilterTable, 'Table1'[date] = LastSaleDate ),
'Table1'[Cumulative Sell]
) + 0
RETURN
IF (
'Table1'[type] = "Sale",
LastSaleValue
)
The dataset now appears as follows and shows the additional two columns on the right-hand side:
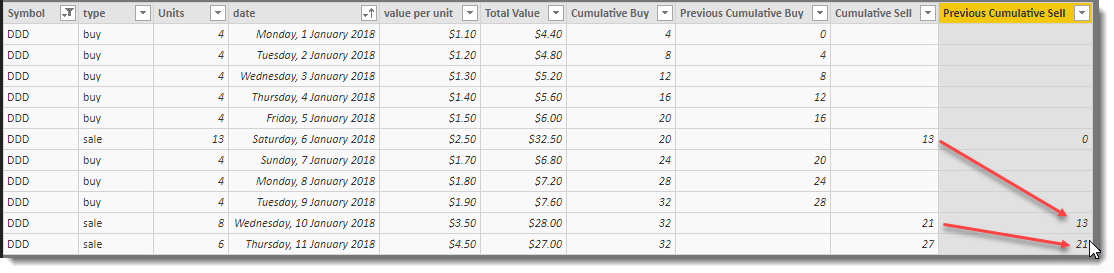
The final calculation makes use of the four running total columns to help detect which “buy” row should be considered for any given “Sale” row.
FIFO column =
VAR myCurrentSell = 'Table1'[Cumulative Sell]
VAR myLastSell = 'Table1'[Previous Cumulative Sell]
VAR mySymbol = 'Table1'[Symbol]
VAR myCumulativeBuy = 'Table1'[Cumulative Buy]
VAR myLastCumulativeBuy = 'Table1'[Previous Cumulative Buy]
VAR FIFOFilterTable =
FILTER (
'Table1',
'Table1'[Symbol] = mySymbol
&& 'Table1'[type] = "Buy"
&& ( ( 'Table1'[Cumulative Buy] >= myLastSell
&& 'Table1'[Cumulative Buy] < myCurrentSell )
|| 'Table1'[Cumulative Buy] >= myCurrentSell
&& 'Table1'[Previous Cumulative Buy] < myCurrentSell
|| 'Table1'[Previous Cumulative Buy] > myLastCumulativeBuy
&& 'Table1'[Cumulative Buy] < myLastCumulativeBuy )
)
VAR FilteredFIFOTable =
ADDCOLUMNS (
FIFOFilterTable,
"New Value", SWITCH (
TRUE (),
'Table1'[Cumulative Buy] > myLastSell
&& 'Table1'[Previous Cumulative Buy] < myLastSell, 'Table1'[Units]
- ( myLastSell - 'Table1'[Previous Cumulative Buy] ),
'Table1'[Cumulative Buy] < myCurrentSell, 'Table1'[Units],
-- ELSE --
'Table1'[Units]
- ( 'Table1'[Cumulative Buy] - myCurrentSell )
)
)
VAR Result =
Table1[Total value]
- SUMX ( FilteredFIFOTable, [New Value] * 'Table1'[value per unit] )
RETURN
IF ( 'Table1'[type] = "Sale", Result )
The calculation will only return a value in the [FIFO Column] for a row that has a [type] = “Sale”. For these rows, an upper and lower boundary is determined by the numbers in the [Cumulative Sell] and [Previous Cumulative Sell] columns. These numbers are stored in the myCurrentSell and myLastSell variables.
The next step is to create a filtered table that only contains [type] = “buy” row where it’s [Cumulative Buy] and [Previous Cumulative Buy] values cross or are fully contained within the numbers stored in the myCurrentSell and myLastSell variables. This filtered table is stored in the FIFOFilterTable variable.
The next step in the process is to figure out how many units should be considered from each batch. If a batch is fully contained within the myCurrentSell and myLastSell variables, then it is considered in full. However, if the batch overlaps the myCurrentSell and myLastSell values, then an adjustment is made and stored in a column called “New Value” that is added to the table variable. There is some simple maths in a SWITCH statement that works out how many units need to be shaved off.
The final calculation then iterates over the table variable and performs a SUMX using the number of units stored in the [New Value] column instead of the original number of units for the row.
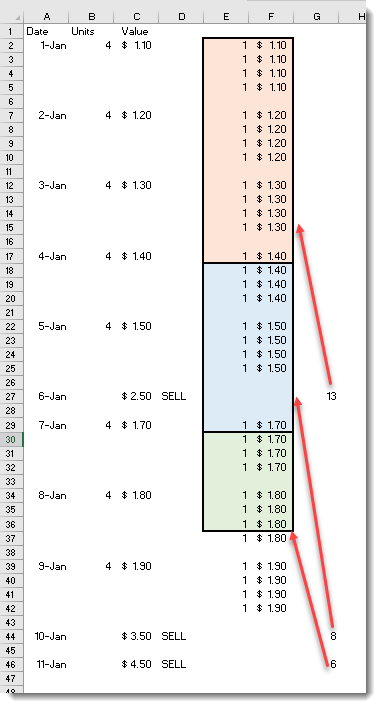
The following image shows the transactions laid out in Excel and show each “Buy” record expanded into individual rows that are grouped into the block allocated to the appropriate “Sale” record.
I hope this article makes sense and gives you an option to consider if you are struggling with a similar problem. Please feel free to comment, or contact me if you have any feedback.




Great article, Phil!
What’s the largest dataset you tried this on?
This is a brilliant technique! Unfortunately DAX could be very slow for these calculations, I’m worried that with millions of rows there could be minutes waiting.
I agree with you Marco and this did worry me, but given the solution is based on calculated columns and not measures, the processing hit is only at the point data is loaded, which for lots of models happens well before any end user starts to query the dataset.
There are also smarter ways to manage cumulative totals, but for this blog, I was keen to focus on the pattern and not get too distracted with optimising cumulative total calculations. I will give this a crack over a larger dataset at some point and let you know how I get on.
Thanks for the feedback though. Definitely much appreciated. 😀
Awesome solution! Very helpful
What does +0 mean within the formulas explained?
Friends already understood the 0, is an accountant, interesting challenge for the other types of inventory systems there.
“The dataset is pretty clean and only has a single “buy” record on any given day. If your dataset has more than 1 per day, a different column should be used to order the cumulative total.”
So what should I have do if I have more than 1 buy/sale per day?
Hi
If you have more that one transaction per day. let’s say one record per product per day, then you need to bring the product into the context of your visual and your DAX expression too.
Cheers
Reza