
In the last post, you learned about Import Data or Scheduled Refresh as a connection type. In this post, you’ll learn about the second type of connection named; DirectQuery. This type of connection is only supported by a limited number of data sources, and mainly targets systems with a huge amount of data. DirectQuery is different from another type of connection which I’ll talk about it in the next post named Live Connection.
What is DirectQuery?
DirectQuery is a type of connection in Power BI which does not load data into the Power BI model. If you remember from the previous post, Power BI loads data into memory (when Import Data or Scheduled Refresh is used as a connection type). DirectQuery doesn’t consume memory because there will be no second copy of the data stored. DirectQuery means Power BI is directly connected to the data source. Anytime you see a visualization in a report; the data comes straight from a query sent to the data source.
Which Data Sources Support DirectQuery?
Unlike Import Data which is supported in all types of data sources, DirectQuery is only supported by a limited number of data sources. You cannot create a connection as a DirectQuery to an Excel File. Usually, data sources that are relational database models, or have a modeling engine, support DirectQuery mode. Here are some of the data sources supported through DirectQuery;
- Amazon Redshift
- Azure HDInsight Spark
- Azure SQL Database
- Azure SQL Data Warehouse
- Google BigQuery
- IBM Netezza
- Impala
- Oracle Database
- SAP Business Warehouse
- SAP HANA
- Snowflake
- Spark
- SQL Server
- Teradata Database
- Vertica
This list may change, with every new update in Power BI connectors, some new data sources may be added to the DirectQuery supported lists of Power BI. To view the up-to-date list always use this link.
How to Use DirectQuery
For running this example, you need to have a SQL Server instance installed. You can download the SQL Server Developer Edition from here: https://www.microsoft.com/en-us/sql-server/sql-server-downloads
Then set up AdventureWorksDW database on it. You can get the database from here: https://github.com/microsoft/sql-server-samples/tree/master/samples/databases/adventure-works/data-warehouse-install-script
This post is not about installing and configuring SQL Server or setting up a database on it. So, I’m not going to explain how to do that. We’ll only talk about the Power BI part of the example;
Open a Power BI Desktop and start with the Get Data from SQL Server.
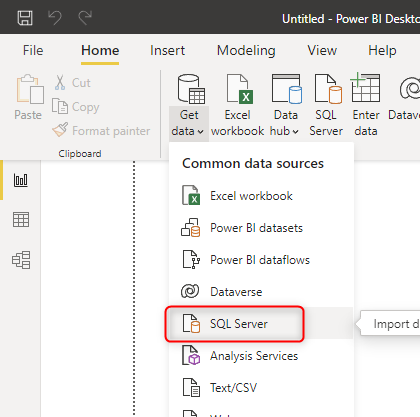
The very first query you will get when connecting to SQL Server data source includes an option for choosing the Data Connectivity mode. Select DirectQuery here. Also, you need to put your server name; If your SQL Server instance is the default instance on your machine, you can use (.) for the server.
Please note that data sources which support DirectQuery, Also, support Import Data (Any data sources support Import Data).
In the Navigator window, you can select some tables from the AdventureWorksDW database, such as DimDate, and FactInternetSales.

After selecting tables, click on Load. The data load dialog in this connection mode will be much faster because there is no process of loading data into the memory. This time, only metadata will be loaded into Power BI. The data remains in SQL Server.
No Data Tab in DirectQuery Mode
One of the very first things you will notice in the DirectQuery Mode is that there is no Data Tab (the middle tab on the left-hand side navigations of Power BI.
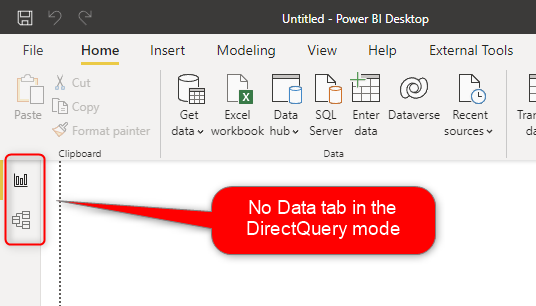
The Data tab shows you the data in the Power BI model. However, with DirectQuery, there is no data stored in the model.
Also at the bottom right side of the Power BI Desktop, you will notice that there is a note about the DirectQuery connection.
How DirectQuery Works
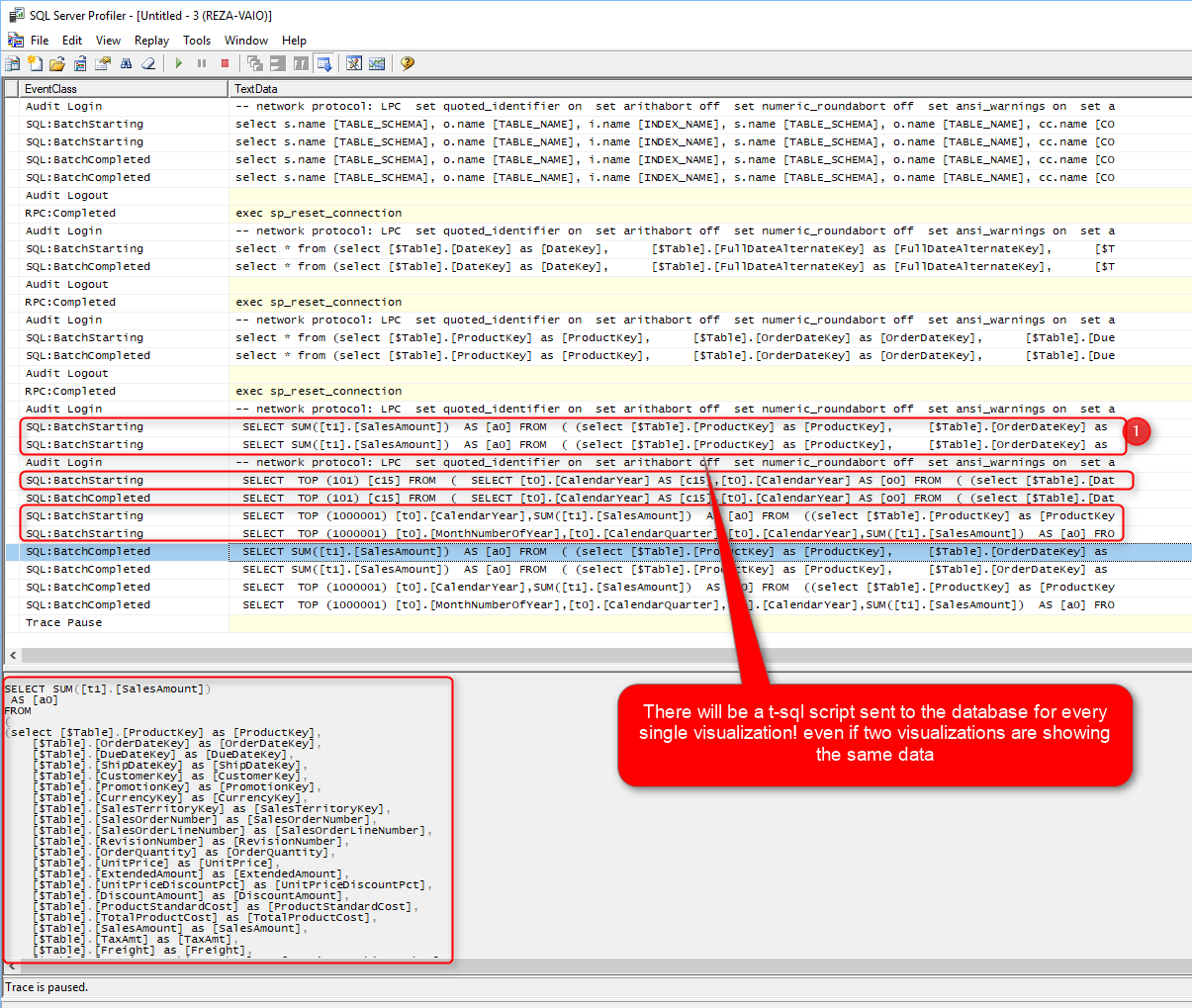
With DirectQuery enabled; every time you see a visualization, Power BI sends a query to the data source, and the result of that comes back. You can check this process in SQL Profiler. SQL Profiler is a tool that you can use to capture queries sent to a SQL Server database. Here is an example Power BI report visual on a DirectQuery model:

And running a SQL Profiler will show you that every time you refresh that report page or change something, there will be one query for every single visualization!
You can see that in the SQL Profiler; Five queries have been sent to the database. One query, for each visualization. Even if two visualizations are showing the same thing, they still send two separate queries to the database.

Performance
The understanding of how DirectQuery mode works, brings you straight to one point: How is the performance of this connection? The question about the performance is a very valid question to ask. You must ask this question Before deciding to use this connection type of course. DirectQuery is performing much slower than the Import Data option.
Import Data loads data into memory. It is always faster to query data from memory (Import Data), rather than querying it from disk (DirectQuery). However, to answer the question that how much faster it is, we need to know more details about the implementation. Depending on the size of data, specification of the server that the database is running on it, the network connection speed, and factors such as is there any database optimization applied to the data source, the answer might be entirely different.
The critical thing to understand is that this type of connection is the slowest type of connection, and whenever you decide to use it, you must immediately think about performance tuning for your database.
Using DirectQuery without performance tuning the source database, is a big mistake that you should avoid.
To understand the need for performance tuning, let’s go through an example. Assume that we have a large table in a SQL Server database, a table with 48 million rows in it. And we are querying the only Sum of Sales column from that table.
Here is the performance I get when I have a normal index on my table with 48 Million records;
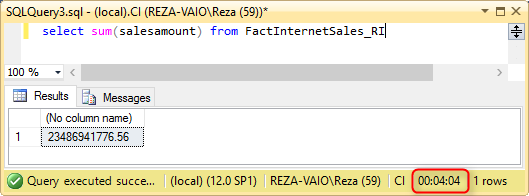
A regular select sum from my table with 48 million records takes 4 minutes and 4 seconds to run. And the same query responds in less than a second when I have clustered column store index and significantly improved performance when I have a Clustered Column Store index on the same table with the same amount of data rows;

I’m not going to teach you all performance tuning in this post, and I can’t do it because you have to read books, blog posts, and watch videos to learn that. That is a whole different topic on its own. And the most important thing is that; Performance tuning is different for each data source. Performance tuning for Oracle, SQL Server, and SSAS are entirely different. Your friend for this part would be Google, and the vast amount of free content available on the internet for you to study.
Query Reduction
One of the newest features added in Power BI is to help to reduce the number of queries sent to the database in the DirectQuery mode. The default behavior of a slicer or filter in Power BI is that by selecting an item in the slicer or filter, other visuals will be filtered immediately. In the DirectQuery mode, it means it will send multiple queries to the database with every selection in filter or slicer. Sending multiple queries will reduce the performance of your report.
You may want to select multiple items, but with only selecting the first item, five queries will be sent to the database. Then after selecting the second item, another five queries will be sent to the database. The speed, as a result, will be twice slower. To fix this issue, you can set a property in the Options of your Power BI file.
Click on the File menu in Power BI Desktop, and then select Options and Settings, from there select Options.
Then click on Query Reduction on the left-hand side (the last item)
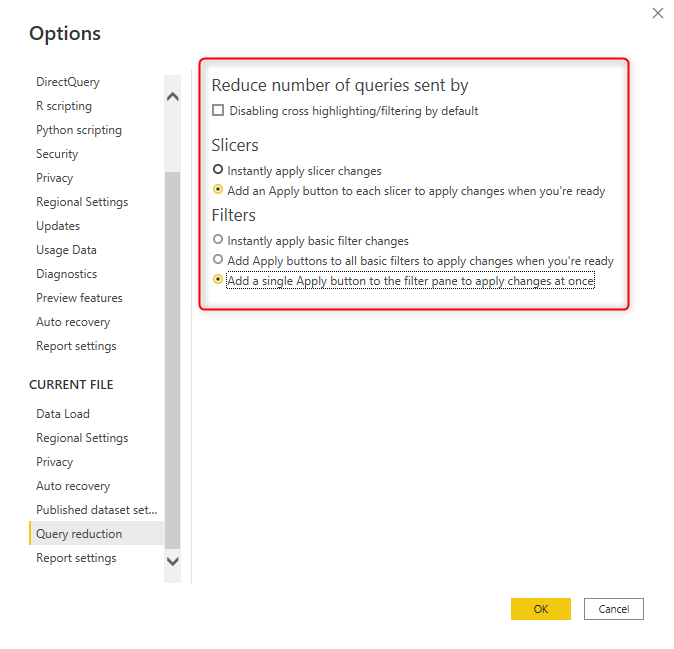
The first item is what I do not recommend in most cases. The first item will disable cross highlighting/filtering by default. With selecting the first option, the main functionality of Power BI, which is cross highlighting/filtering will not work by default. Cross-highlighting/filtering means that, when you click on a visual, other visuals will be either filtered or highlighted. This feature is what makes the Power BI an interactive visualization tool. The option for removing it for most of the cases is not useful. However, if you have some visuals that don’t need to interact with each other, enabling this option will reduce the number of queries sent to the database.
The second and third options, however, are beneficial, especially if you have multi-select slicers and filters. When you choose this option, then your filters or slicers will have an Apply button on them. Changes will not apply until you click on the apply button, and then all queries will be sent to the database. This option is highly recommended when you have a multi-selection slicer or filter. You can even choose to have one single Apply button for the entire Filter pane, which can be very helpful in query reduction.

Maximum connections per data source
The number of concurrent queries sent from Power BI to the data source is an important number. If you allow too many concurrent queries, then you are applying a very high load on the data source. On the other hand, if you have created a report page with over 15 visuals, then you would need 15 concurrent queries (assuming they are not slicers, and query reduction won’t reduce the number of queries).
You have the option to set the number of concurrent queries per data source in the Power BI file options.
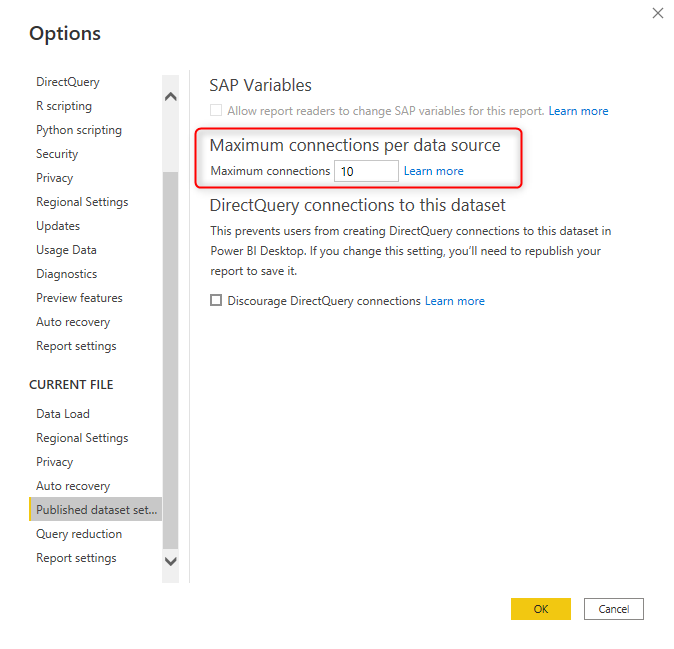
This setting is for the published Power BI file. And a published Power BI report can be opened by multiple users. This also means increasing the concurrent connections. So when you are setting this number, you have to take into account not only the number of visuals on the page and the performance of the data source but also the number of concurrent report users.
Depending on the license of Power BI and the environment, there are some limits on this number as below;
| Environment | Upper limit (active connections per data source) |
|---|---|
| Power BI Pro | 10 |
| Power BI Premium | 30 |
| Power BI Report Server | 10 |
Adding extra Data Sources: Composite Mode
Back in the older days of using Power BI Desktop, if the DirectQuery was the mode of the connection, it was not possible to add any other data sources. However, that changed a few years ago. You can add extra data sources (Import, or any other connection types) to a DirectQuery-based Power BI file, This will change the file to something we call Composite Mode. The below warning will be, however, visible when you are bringing data from other data sources;
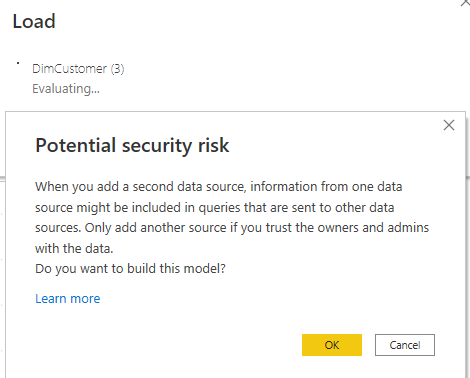
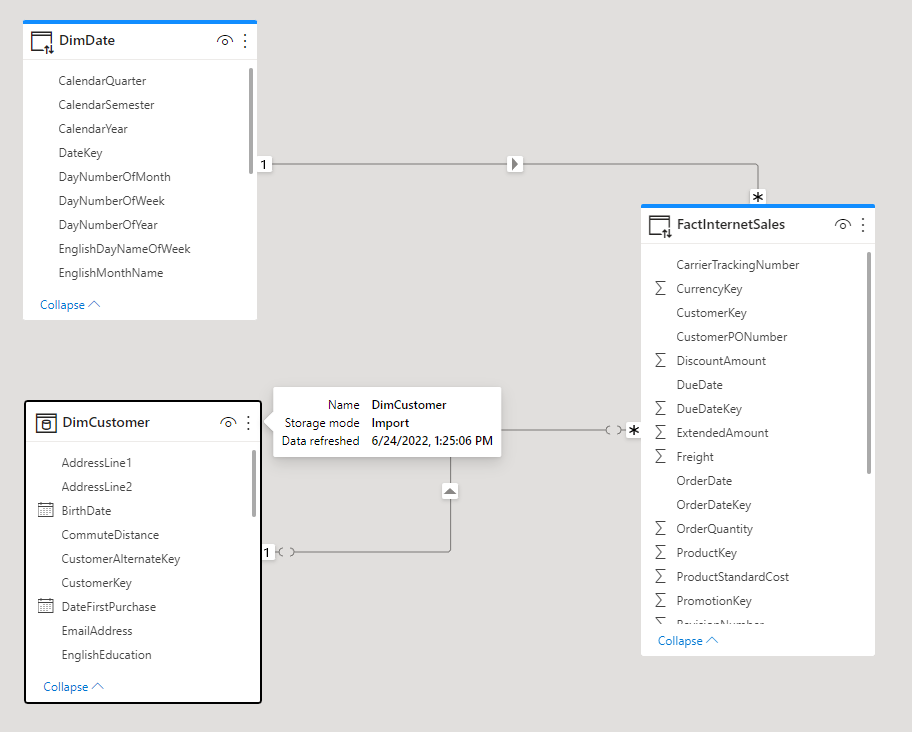
The Composite mode is a very powerful way of building Power BI files that uses part of the data using a DirectQuery connection and other parts of the data using an Import Data connection. Often even in large-scale data source scenarios, there are small tables for dimensions. Dimensions in such cases can be imported while the big fact tables are used as a DirectQuery. You can learn more about the Composite Mode in this post. In the screenshot below, the DimCustomer is an Import mode table, and the DimDate and FactInternetSales are using DirectQuery.
Limited Power Query
With DirectQuery, you can apply some data transformations in the Query Editor window. However, not all transformations are supported. To find out which transformations are supported and which are not, you have to check the data source first. Some of the data sources are not supporting any transformation at all, such as SAP Business Warehouse. Some of the transformations, such as the SQL Server database, support more transformations.
If you use a transformation that is not supported, you’ll get an error message that says “This step results in a query that is not supported in DirectQuery mode.”

Transformations in Power Query are limited in DirectQuery mode. Depends on the data source, some transformations or sometimes no transformations at all are supported.
As I mentioned earlier; when you use a DirectQuery connection, then you usually should think of another data transformation tool, such as SQL Server Integration Services, etc. to bring data transformed into a data warehouse before connecting Power BI to it.
Limited Modelling and DAX
DAX and Modelling are also limited in DirectQuery mode. The creation of calculated tables is allowed in Composite mode, and the default Date hierarchy is not available. Some of the DAX functions such as parent-child functions are not available too.
Some of the complex DAX measures might cause performance issues in the DirectQuery mode. It is better to start with simple measures such as simple aggregations first and test the performance, then gradually add more complex scenarios.
No Refresh Needed
One of the advantages of DirectQuery is that there is no need for data refresh to be scheduled. Because every time a user looks at the report, there is a query sent to the database, and the recent data will be visualized, then there is no need for a data refresh schedule.
For Dashboards when the automatic refresh happens, the DirectQuery connection will be refreshed every 15 minutes or more. For reports, data will be updated anytime a new query is sent to the database with refreshing the report or filtering or slicing and dicing.
Large Scale Dataset
The main benefit of DirectQuery is to use it over a massive amount of data. This feature is in fact, the main reason that you may need to consider DirectQuery. Because the data is not loaded into the memory, there is no limitation on the size of the data source. The only limitation is the limitation that you have in the data source itself. You can have petabytes of data with the DirectQuery connection. However, you need to consider performance tuning in the data source as mentioned before in this post.
No size limitation is the main and in many cases the only reason why some scenarios use DirectQuery. Because based on what you’ve learned in this post, DirectQuery is slower, and less flexible, with fewer features than Power Query, and DAX. Overall DirectQuery is the only option if the other two types of connections cannot be used.
These days, Specially after the Composite Mode became available in Power BI, it is very rare that a pure DirectQuery-only method is used in a Power BI dataset. The better approach is to have DirectQuery for large tables, Import Data for smaller tables, and create a Composite Mode.
Summary
Power BI supports three types of connection. In this post, you’ve learned about DirectQuery which is one of the connection types. DirectQuery is not storing a second copy of the data in memory. It will keep the data in the data source. With DirectQuery, anything you see in the report will be sent to the database through T-SQL scripts. If you have ten visualizations in your report, it means posting ten queries to the database and getting the result of that back.
DirectQuery supports a huge amount of data. Because the data is not stored in the memory, the only limitation on the data size is the limitation of the data source itself. You can easily have petabytes of data in a database and connect to it from Power BI. The limitation that we have in Import Data does not apply here, and you can have a large-scale dataset for connecting to it. Another advantage of DirectQuery is no need for a scheduled refresh. Because with this mode the data will be updated anytime the report is refreshed with queries sent to the database, there is no need for scheduling refresh.
DirectQuery has many limitations and downsides. With DirectQuery, the speed of Power BI reports is much slower. DirectQuery is limited in using modeling features of Power BI such as DAX, calculated tables, built-in date tables, and Power Query functionalities. DirectQuery is as a result less flexible with fewer features. Using DirectQuery means you get slower reports, with less functionality on the Power BI side.
DirectQuery because of the limitations mentioned above is only recommended if the other two types of connection (Import Data, or Live Connection) cannot be applied. In the next post, I’ll explain Live Connection. If you decided to use DirectQuery, it is then better to use another integration tool and do all the data transformation before loading data into the source database. Also, it is better to take care of all the calculations in the data source itself.
DirectQuery is only recommended if the other two types of connection (Import Data, or Live Connection) cannot be applied. If needed DirectQuery is better to be used with combination of Import Data through a Composite Mode.
Here is the list of pros and cons of the DirectQuery;
Advantages
- Large Scale Dataset; Size limitation only for the data source itself
- No need for data refresh
Disadvantages
- Power Query transformations are limited
- Modeling is limited
- DAX is limited
- Lower speed of the report
Video




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Hi,
Direct Query to an Oracle 11g is also possible.
Frank
Hi Frank.
Thanks for confirming that 🙂
Cheers
Reza
Direct query on Oracle with 12 million rows I tried. Power BI throws error. Row limitation is there max of 10m rows. Any work around..
Hi Sundar.
Row limitation is 1 million rows in DirectQuery.
but let me ask the question in this way; DirectQuery will send a query to the database everytime you visualize something. are you trying to visualize 12 million rows in a table? if that is the case, then Power BI should not be used for that. better to use SSRS then
Cheers
Reza
Hi Reza,
We have a power BI report which uses 7 million records.Then how is it possible if the limit is 1 million using direct query.
Hi Jagadish,
The limit of 1 million rows is when you query that amount of data from a visual. you can have a table with bilions of rows, that is not a problem at all. but if you have a table visual in your Power BI report which shows 2 millions rows of that (I doubt if you ever do that), then you cannot.
Cheers
Reza
Thank you for this post. One of the best explanation for the advantages and disadvantages of DirectQuery in PowerBI.
My power BI reports loads very slow,it takes around 1 to 3 minutes to load all visuals.power bi fetching data through direct query and data source is ssas tabular model.I did partitioning,created relationship on integer columns,removed unused measures,move data source to server having 32 gb ram to 128 gb ram but it doesnt add to performance.What else i can do?
SSAS tabular is NOT a DirectQuery connection, It is a Live Connection which is different.
methods that you have done (Partitioning as an example) does not affect the performance of the report, It just affects the timing of the processing SSAS Tabular model. For making your reports faster you have to take measures and modeling highly into consideration. You have to check and see which measures are heavy calculations and performance tune those.
Hi Reza,
Thank you for the post. I have some questions about this data connection type:
1. If I keep the page open in Power BI Service, will it be automatically refreshed? Or I have to initiate some interaction with the report to get it refreshed; for example, click on the options of a slicer.
2. The stakeholder requests to put “Last refresh datetime” on the page to remind them to do the refresh. Is a way to do it?
Thank you.
Hi Teresa
Report never refreshes automatically. You have to manually click on the refresh on it, or open the report page again.
Dashboard however on the other hand side, will refresh automatically. On DirectQuery data sources, it can be on a 15, 30, 45, or 60 minutes intervals.
for having the last refresh datetime with DirectQuery; one of the methods is to have this field coming as a query from the database, or even a DAX measure in the page
Cheers
Reza
Nice post! Very deeply post.
I am using AWS Redshift for Direct Query mode.