

Previously, I have written about using Power Query transformations and functions to create an Exception report for Power BI. However, the method I mentioned there, was only doing the exception handling based on one column. In this article, I’m explaining how to do exception reporting for all columns in the entire table. There are a little bit more steps and also learnings when you do the whole process for the entire table. To learn more about Power BI, read Power BI book from Rookie to Rock Star.
Prerequisite
It would be beneficial to read the first part of Exception Reporting in this article here.
You can download the dataset used for this example here.
Introduction
The Exception Reporting method that you learned in Part 1, was focusing on handling errors for one column. That method works best if you already know which column is causing the error. However, in many scenarios, you don’t really know which column caused (or will cause) the error. So, this article then aims for that scenario.
Important Note: Exception handling is a process that makes your Refresh time a bit longer. It is definitely faster to handle exceptions for one column, compared to doing it for all columns in the entire table. I strongly suggest that use the method mentioned in Part 1, if you already know the column that is prone to error in the table.
Starting from basics
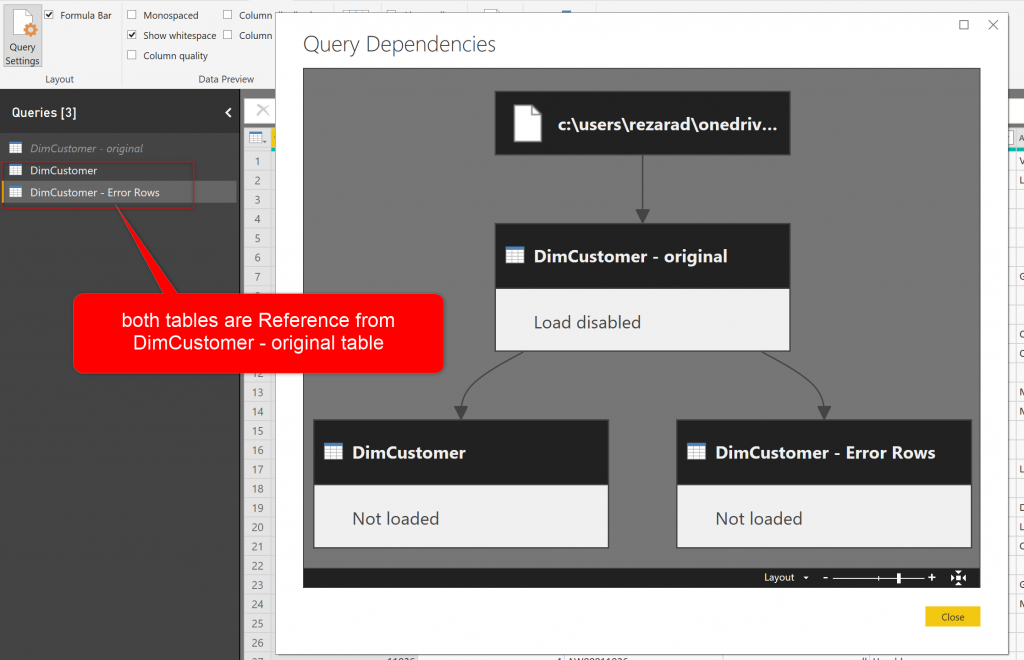
In the first part of this article, I mentioned that to have a proper error handling; you would need to have three tables; One table which is the original source, another table which is referenced from the original and error rows are removed. And the last table (which we call it error table) with error rows kept. Now let’s start with that plan.
If you haven’t done part 1, you can start by Get Data from the file mentioned above, then click on Edit to go to Power Query Editor, and then rename the DimCustomer, to DimCustomer – original. Disable the load for this table, by right-click and uncheck the Enable load.
DimCustomer – original is the table that is sourced from the data source, and has some data transformations which might cause an error. This table is not loading into Power BI (Enable load is unchecked). Start by creating two references from this table:
- DimCustomer (a table which will be used in normal reporting in Power BI)
- DimCustomer – Error rows (the table which will be used as the source of exception reporting).
Remove rows with Errors
The DimCustomer table is the table with no errors that we use in normal reporting. To remove errors rows, you need to select all columns in this table (Ctrl+A), and then select Remove Rows -> Remove Errors.

This action will remove errors. However, there is a problem! If you look at the M code generated in the formula bar; you will see that the code is like below:
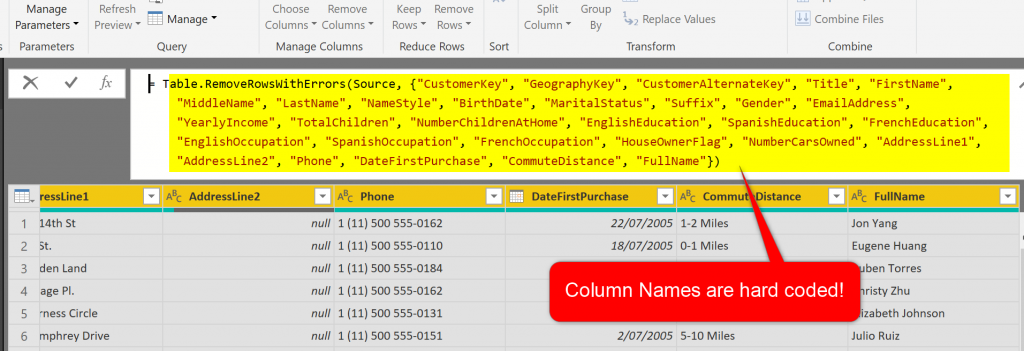
This means that if later on, another column is added to the table, and it contains error, this table won’t be the error-cleaned table anymore. We need a better way to do it dynamically. We need to get a list of columns from a table and use that as a source for the RemoveRowsWithErrors function.
Table.ColumnNames: List of all column names in a table
Table.ColumnNames is a function that gets the table name as the source and will give you the list of column names as the output. Table.ColumnNames is a function that can be used just like this:
<list output> = Table.ColumnNames(<table name>)
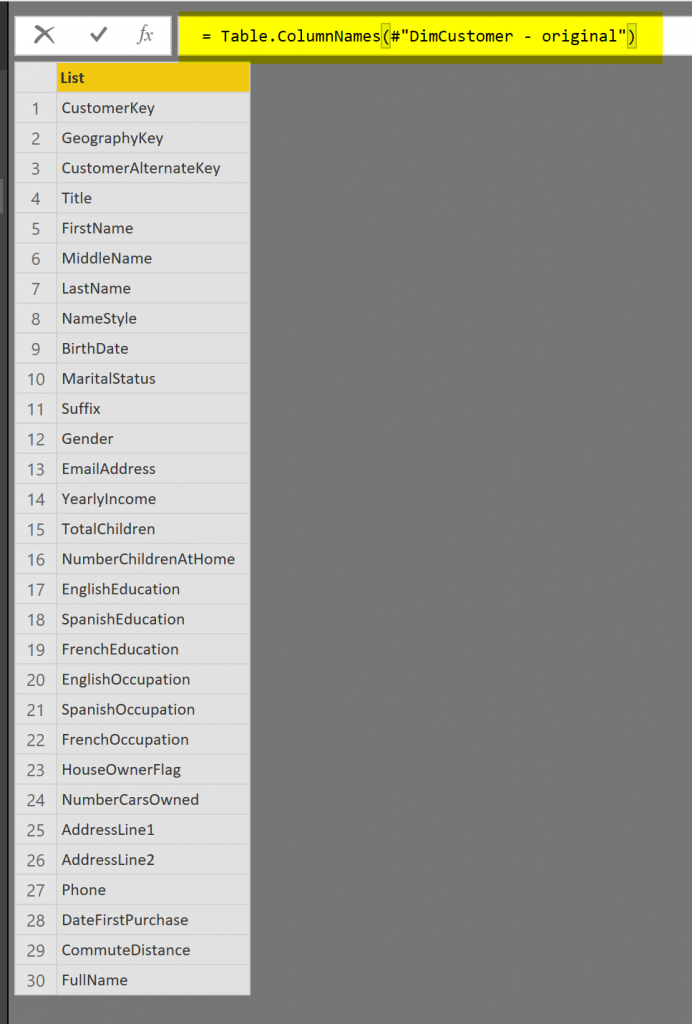
An example output of this function (ran in a blank Power Query script for the table above) is:
= Table.ColumnNames(#"DimCustomer - original")
Remove Rows with Errors with Dynamic Columns List
Now, all we need to do is to use the output of Table.ColumnNames as the input of Table.RemoveRowsWithErrors function. Highlighted in the part of the code that should be replaced with Table.ColumnNames;

And this is the new code;
= Table.RemoveRowsWithErrors(Source, Table.ColumnNames(Source))
As you notice, the table name is “Source” because it is coming from the previous step called as Source.
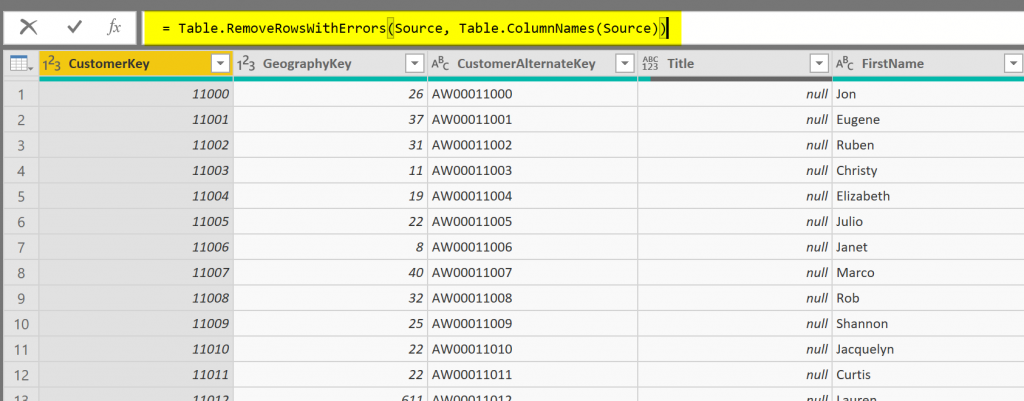
Great job! Now this table (DimCustomer) is the table without any errors. Even if the number of columns changes in the source table, it would be still a valid table. Let’s see what we can do with the other table.
Keep Rows with Errors
For DimCustomer – Error Rows table, we have the same scenario again. Usage of Keep rows with errors. It will hard code the column names, and you need to then replace it with the output of Table.ColumnNames as below;
= Table.SelectRowsWithErrors(Source, Table.ColumnNames(Source))
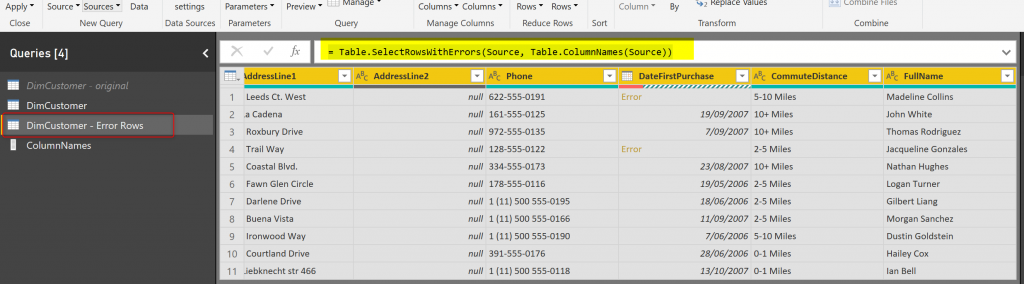
Now this table has all error rows, which might have occurred in any of the columns. Our next step is to find in each row; what is the column that caused an error. Because not all column’s caused an error in each row. To be able to find it and then point at it, we need a row identifier. A way to be able to distinguish that row later on. We need a Key Column for the table.
Note: Key Column can be multiple columns as well, but for simplicity, I keep it as one for this example.
Key Column: the row identifier
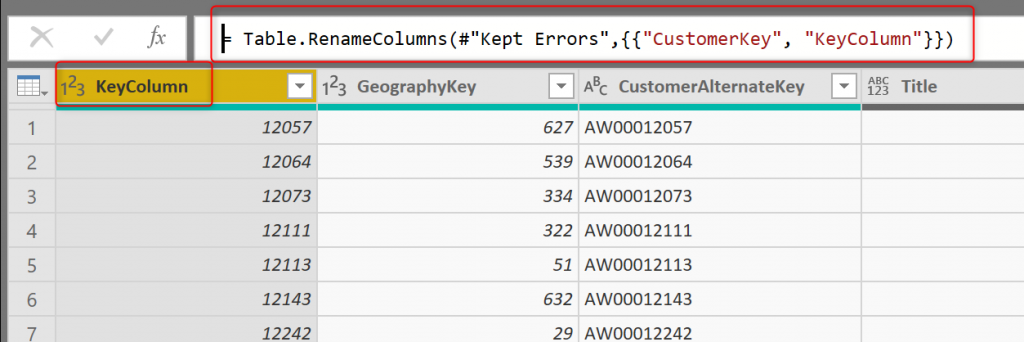
To be able to find the row that has the error, later on, we need to have a key column. And we need to make sure that the key column has no errors itself, otherwise, how you are going to find out which row has the issue. Let’s assume for this example, that the key column is CustomerKey. Let’s rename it to make it easier to use later on. You can simply rename the column with right-click or double click on the column name.
Unpivot: Columns as Rows
Now we need to have columns in a structure like below:

Instead of having columns, we are going to have rows, and then we can filter only for those that their value is an error. One of the best transformations for this job is Unpivot (read more about it here). However, unpivot would end up like this:
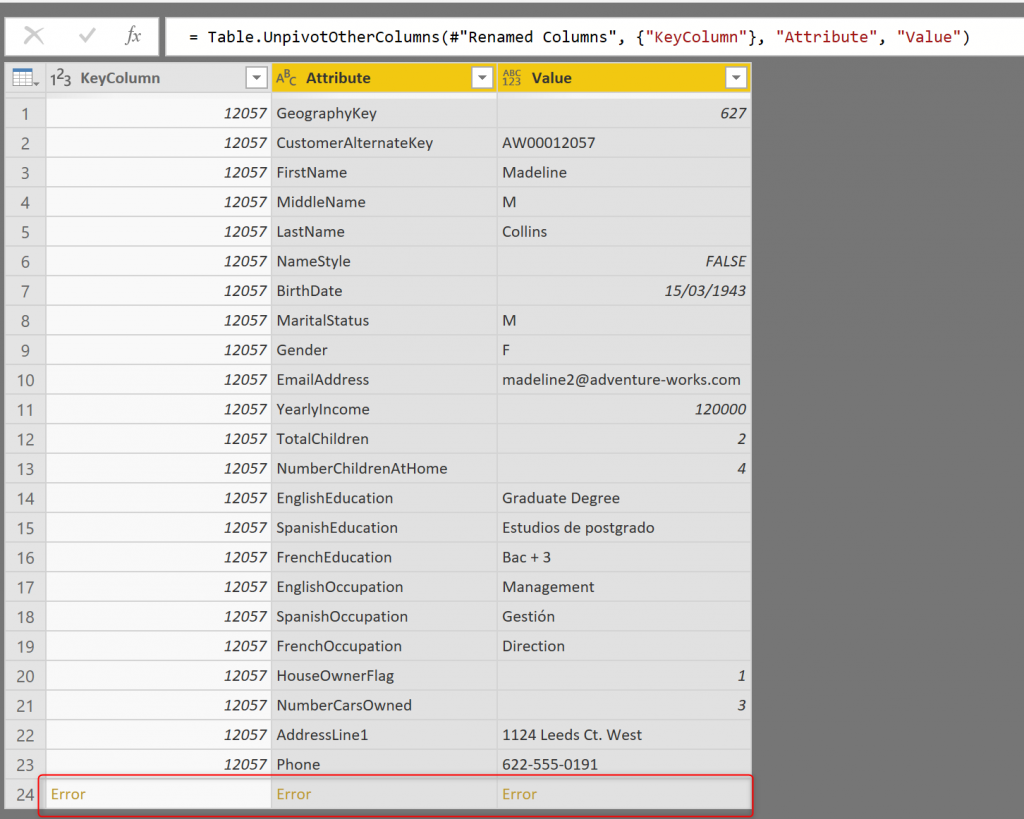
What is wrong? We have 11 rows in the error table, and 30 columns in each row (minus the key column is 29). It means this new table should have 11*29 rows, which is 319 rows. But as you can see, the table has 24 rows. The process stopped when it hits the first error.
Unpivot is not immune to errors, and if you have errors in your dataset, you have to clean them first before using this function. So we have to find another way which gives us the same output. We need to get the list of values in each row as a table, and then expand it. Let’s start with getting a list of values in each row.
If you did the Unpivot action mentioned in this step, please remove it. This explanation was just to show you why we cannot use it and have to use a method which is slightly different and includes more steps.
Current row indicator: _
If you never used the “_” character, it is one of the best times to learn about it. Underscore (_) character when used by itself (not as part of a text), means the current row! If you use it in a list that has only one value per row, it returns that value. If you use it in a table, it returns the current row in that table, and each row in a table is a record.
To see it by yourself and understand it better, let’s Add a Custom Column, and then as the expression just write one character: _
_
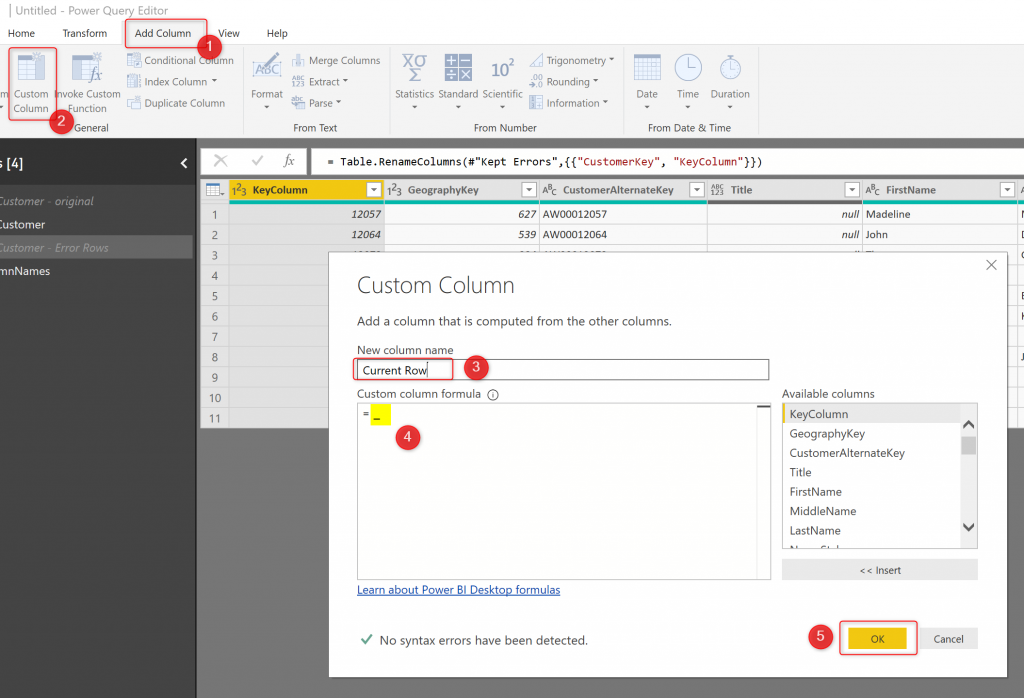
Your table will look like this: a new column is added at the end of the table, with one Record at each row. That record includes all values of that row itself.
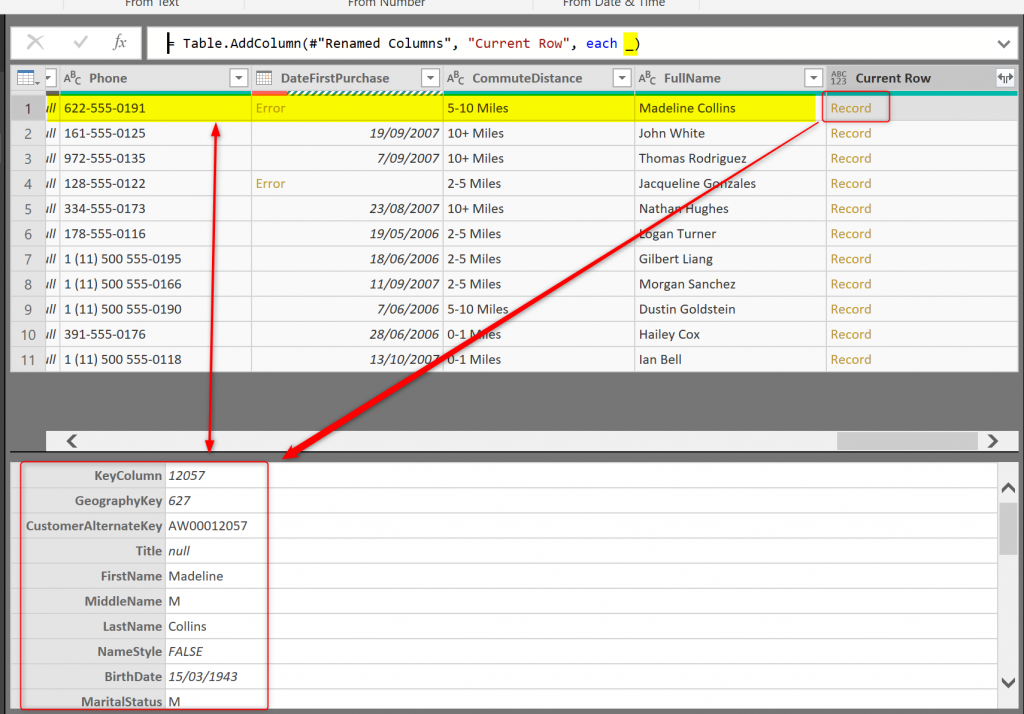
We got a method to fetch the content of a row as a single object, and all of that is with the magic of the current row indicator: _.
Now our next step is to expand it, however, not using the normal expand, because if you expand a record in a table, you will have columns of that record added to the table, which means we get back to the same place we have been before.
If you convert a record to a table, you will have two columns as the output; column names in the record, and column values. And then that is the structure that can be expanded without having all columns back in the place. So let’s convert that value to a table.
Convert the Current Record to a Table: Record.ToTable
Add another custom column, and this time write the expression below to convert that record to a table;
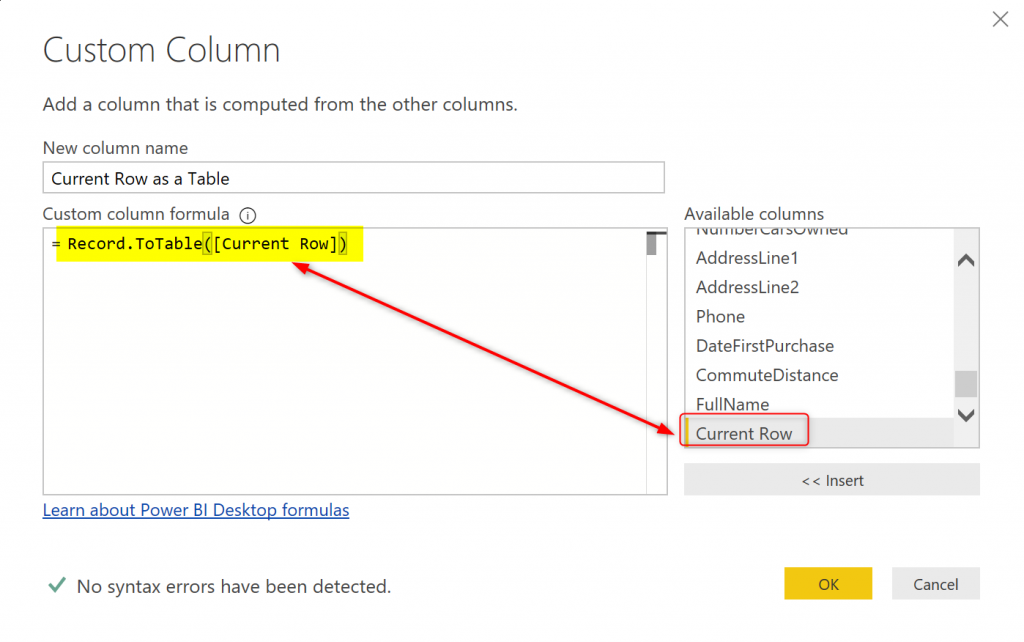
The expression is as below:
Record.ToTable([Current Row])
Now the table will have a column at the end, with a table in each row, and that table is the content of the current row (but as a table format);
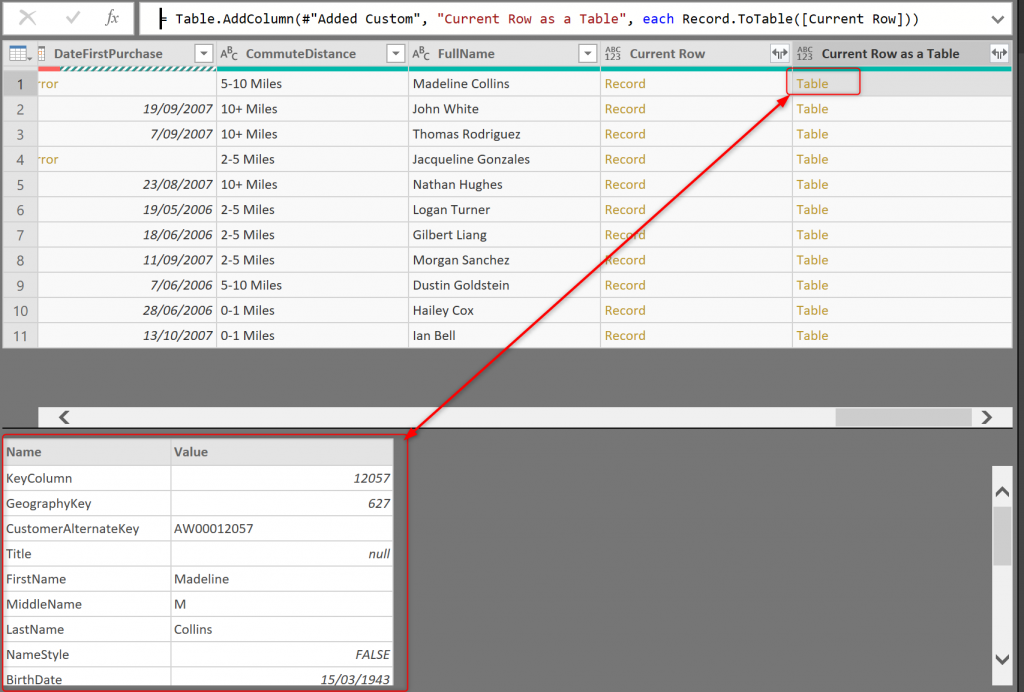
We could have done both this step and the step before using one action with Record.ToTable(_). However, I split it into two steps to make the concept of _ clear.
After having the nested table, we can remove all other columns and only keep the KeyColumn and the column that contain tables;
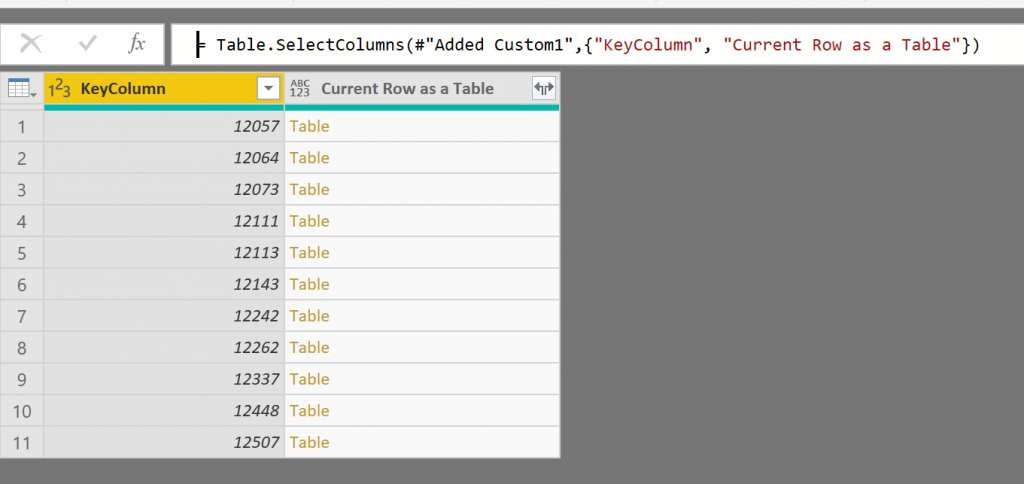
Expand
Our next step is to expand the underlying table;
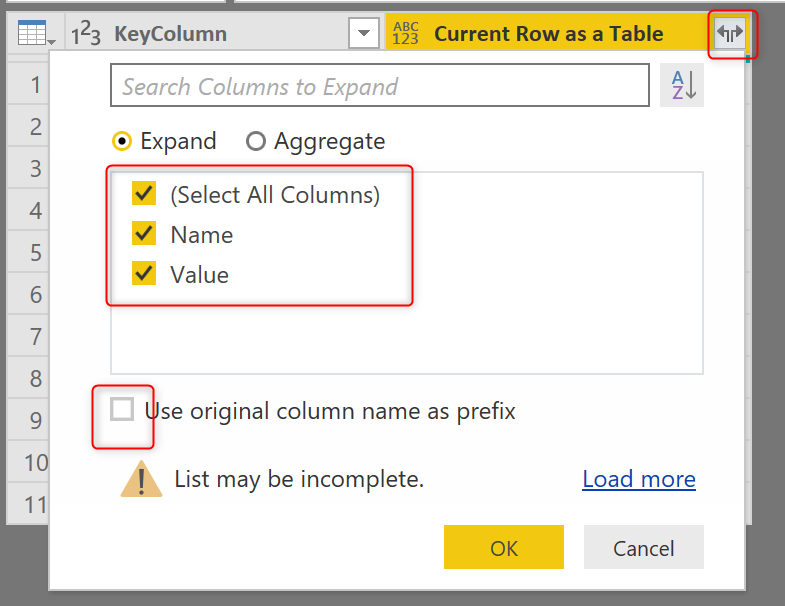
Underlying table only has the Name (column names), and Value (cell values), and here is the expanded output:
![]()
The first column in this table is the KeyColumn for each row. Now for each row in the previous table structure, we have multiple rows here in this new structure, one row per column as well, in each row, in addition to the KeyColumn, you can see the column name (Name), and the row value in that cell (Value). And you can see that that row value sometimes has an error.
Next Steps
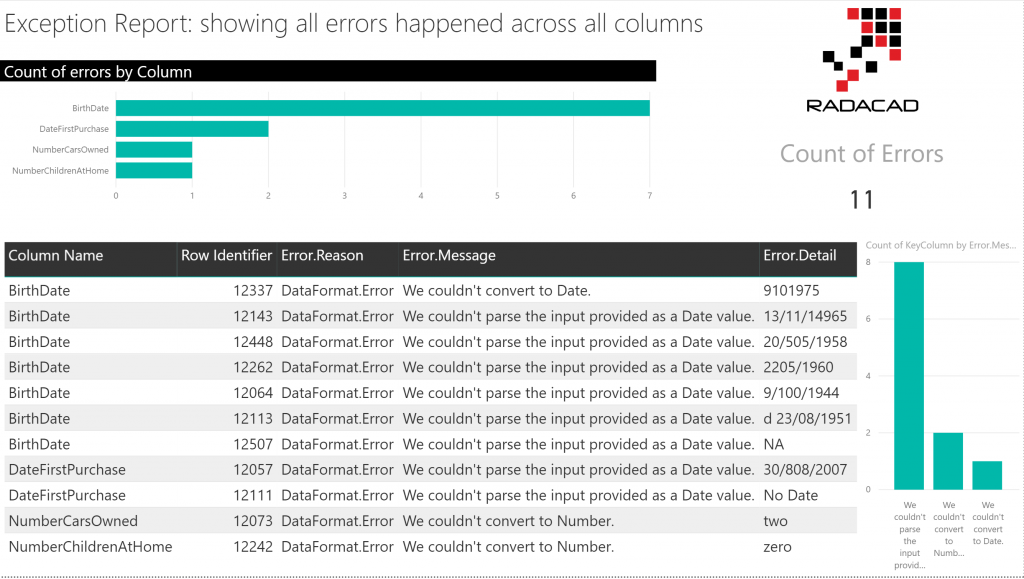
The steps still continue with some more transformations. However, as it would make this article a long post, I have written about it in the next post: section 2 of this article, which would which is part 3 of the Exception Reporting in Power BI. At the end of the process, we are going to have a report like this:




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
This is awesome! I’ve been using PBI for about 3 years and didn’t know about “_”, really informative article that I can definitely put to use!!
Thanks Dave for your kind words 🙂
Although the sigils and parenthetication are all different, anyone familiar with perl will recognise some of the concepts in M. Perl has a default operand of $_ (e.g. chomp; and chomp $_; are identical statements, and in a loop construct the iterator is $_ unless explicitly defined otherwise). The $_ variable’s proper name is “this”.
And of course, anyone familiar with Javascript will also recognise the term “this” from code like: function(){ $(this).doSomething(); } where it also means “the current thing in context”.
Microsoft have built some great stuff in Power BI and Power Query, but they haven’t invented everything 🙂
Great to know. I haven’t worked with Perl at all and did minor things with JS. Great to see where the structure is all coming from 🙂
Thank you Reza. This is very useful article. I am referring both of your articles to process XML data into columns. XML Data is coming from a XML Data type column in MSSQL. I am getting an error in the Error Rows data set as “Expression.Error: The parameter is expected to be of type Text.Type or Binary.Type”. It’s just displaying the error message but no data. Could you please suggest me how can I fix this issue.
Hi Ravi
Is this for one or two rows in the dataset or the entire rows for that column fails with the error? Do you have a sample of XML data in that cell to paste here so I can check?
Cheers
Reza