
suppose this scenario:
you have a source table and a destination table, you want to transfer rows from source table to destination table, so you can use simple data flow with OLE DB source and OLE DB Destination. but problem hits when destination table has few rows inside, and there is Unique Constraint in ID field of Destination table.
in this situation your data flow will fail, because when OLE DB Destination want to insert rows in destination table, it will got Unique Constraint error and it will raise Data Flow error, and this will prevent OLE DB Destination to insert any rows in table, even rows which hasn’t equivalent key in destination !
So, a work around needed here to avoid failing package and only move rows which hasn’t problem with unique constraint in destination table.
let me explain it with a sample here…
create source table with this script:
CREATE TABLE [dbo].[SourceFailureTable](
[ID] [int] IDENTITY(1,1) NOT NULL,
[name] [varchar](50) NULL,
CONSTRAINT [PK_SourceFailureTable] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
and fill it with this data: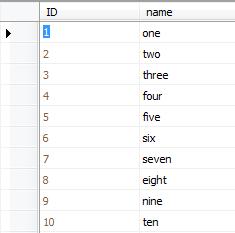
now create destination table with this structure:
CREATE TABLE [dbo].[DestinationFailureTable](
[ID] [int] NOT NULL,
[name] [varchar](50) NULL,
CONSTRAINT [PK_DestinationFailureTable] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF,
ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
Note that DestinationFialureTable, has a Primary Key on ID filed, primary key is basically a Unique Constraint. so this constriant will check IDs to be unique , and if an insertion tends to insert not unique value in ID field this will cause Unique Constraint Error.
fill Destination with these three fields:
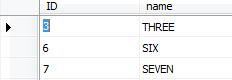
we want to import rows from SourceFailureTable to DestinationFailureTable.
Create simple Data flow task, with an OLE DB Source, connected to SourceFailureTable. and an OLE DB Destination connected to DestinationFailureTable. map the columns too.
now every time you run this package you will got error:
error description:
"Violation of PRIMARY KEY constraint ‘PK_DestinationFailureTable’. Cannot insert duplicate key in object ‘dbo.DestinationFailureTable’."
and none of ten rows in Source table moved to destination table. even rows with IDs like 1 , 2, 4 ,.. which
not exists in the destination table.
So, What we can do?
right click on OLE DB Destination, select properties window. find AccessMode in properties, you can see that the AccessMode value is OpenRowSet using FastLoad. this will cause that all records from input insert with a fast load transaction at one time. so this will cause error.
Change AccessMode to OpenRowSet . this will try to insert row by row.
Note that this is not good option when you insert large amount of records because insertion with fast load has better performance, but in this sample I just want to show you how to handle failed rows in insert.
after chaning AccessMode to OpenRowSet , run package again, you will see the error happens again with no luck. but difference is here in the destination table:
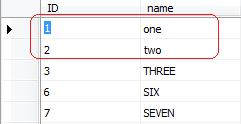
in the destination table two new rows inserted , rows with ID 1 and 2. but no more rows. the meaning of this behaviour is that OLE DB Destinaion tried to insert row by row into the DestinationFailureTable, first two rows inserted successfully. but for third row it got unique constraint error again and cause package to fails. and failing the package stops other rows transformation.
So you should handle rows which cause Error. this is the time when Failure Error Output comes to help.
first delete rows with ID 1 and 2 from DestinationFailureTable manually.
and then add another table named FailedRows with this structure:
CREATE TABLE [dbo].[FailedRows](
[ID] [int] NULL,
[name] [varchar](50) NULL
)
we want to move rows which cause error to this table.
now add another OLE DB Destination in data flow , right after DestinationFailureTable . and connect RED ARROW to it. when you connect this arrow, a Configure Error Output window will appear. look at this screenshot:
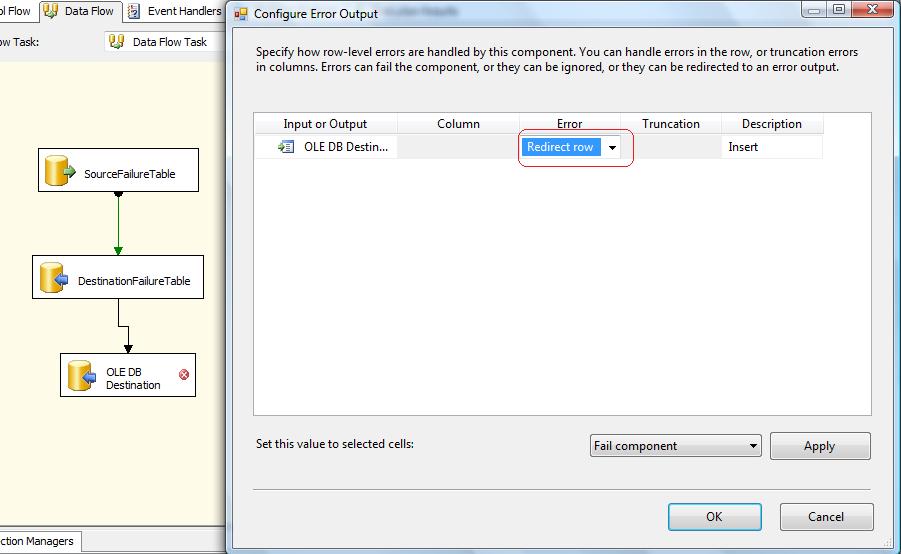
there are three options for Error property in this window:
Ignore Failure will ignore any errors during insertion of records to destination
Redirect Row will redirect any rows which cause error during insertion to destination
Fail Component will cause to fail component when insertion hits any error
by default this option set to Fail Component. so when you got an error during insertion the whole OLE DB Destination will fail.
Set the Error as Redirect row. this will cause every rows which cause error ( means BAD rows ) to redirect to new OLE DB Destination.
now hit ok. and double click on new OLE DB Destination let’s name it FailedRows. connect this to failed rows. and map the columns like below:
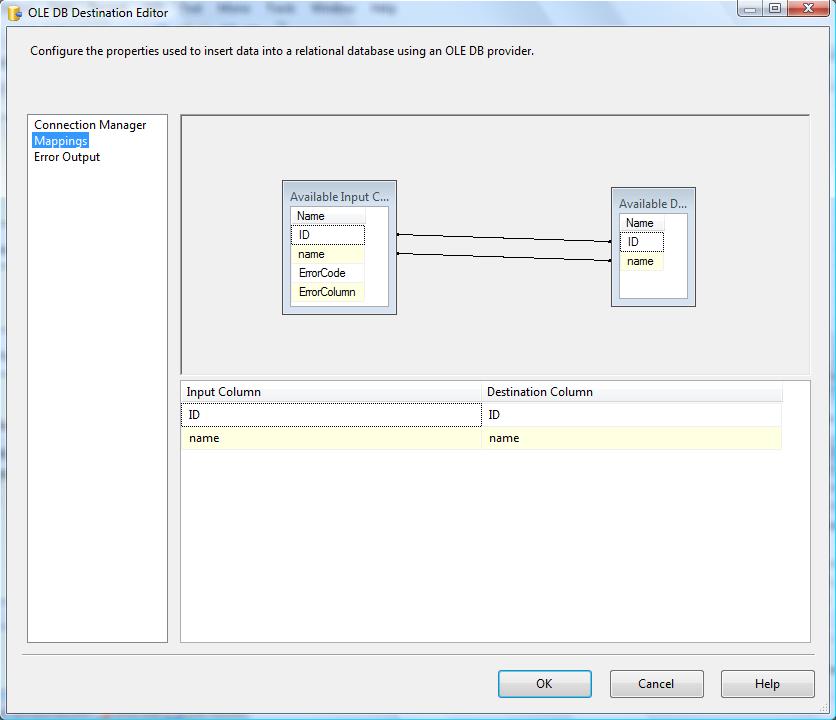
Note that there are two new columns in mapping page, ErrorCode and ErrorColumn. these are auto generated rows by Failure Error Output and will show code and column number of error. we don’t need them in this sample. so just map ID and name.
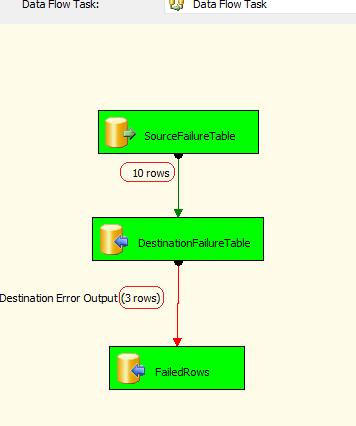
now run the package. you will see that there are 10 rows transfered from SourceFailureTable to DestinationFailureTable, but there are only 3 rows transfered to FailedRows. this means that there are 3 rows exists in DestiantionFailureTable which prevent equivalent values in SourceFailureTable to be inserted . so these rows transfered to FailedRows Table.
this is full schema of package:
and look at results in DestinationFailureTable:
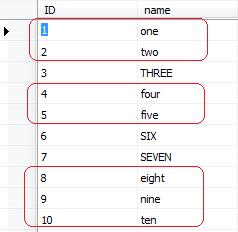
there are 7 new rows in this table.
and this is results in FailedRows Table:
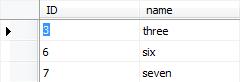
there are 3 rows which cause unique constraint failure transfered to this table.
This was a sample of how to use failure error output in SSIS. hope to solve your issues in this area.




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.