

Market Basket analysis (Associative rules), has been used for finding the purchasing customer behavior in shop stores to show the related item that have been sold together. This approach is not just used for marketing related products, but also for finding rules in health care, policies, events management and so forth.
In this Post I will explain how Market Basket Analysis can be used, how to write it in R and come up with good rules.
In next post I will show how to write Associative Rules in Power BI using R scripts.
What is Market Basket Analysis (Concepts)?
This analysis examine the customer purchased behavior. For instance, it able to say that customers often purchase shampoo and conditioner together. From perspective of the marketing, maybe promoting on Shampoo lead customers to purchase conditioner as well. From perspective of the sales, by putting Shampoo beside Conditioner in store shelf, there is a high chance that people purchase both.
Association rules is another name for Market Basket analysis. Association rules are of the form if X then Y. For example: 60% of those who buy life insurance also buy health insurance. In another example, 80% of those who buy books on-line also buy music on-line. Also, 50% of those who have high blood pressure and are overweight have high cholesterol [2]. Other examples such as;
- Searching for interesting and frequently occurring patterns of DNA and protein sequences in cancer data.
- Finding patterns of purchases or medical claims that occur in combination with fraudulent credit card or insurance use.
- Identifying combinations of behavior that precede customers dropping their cellular phone service or upgrading their cable television package.
You will see these rules are not just about the shopping, but also can be applied in health care, insurance, and so forth.
Measuring rule interest – support and confidence
To create appropriate rules we should, it is important to identify the support and confidence measure. Support measure is: The support of an item set or rule measures how frequently it occurs in the data[2].
For instance, imagine we have below transaction items from a shopping store for last hours,
Customer 1: Salt, pepper, Blue cheese
Customer 2: Blue Cheese, Pasta, Pepper, tomato sauce
Customer 3: Salt, Blue Cheese, Pepperoni, Bacon, egg
Customer 4: water, Pepper, Egg, Salt
we want to know how many times customer purchase pepper and salt together
the support will be : from out four main transactions (4 customers), 2 of them purchased salt and pepper together. so the support will be 2 divided by 4 (all number of transaction.
2/4 (0.50).
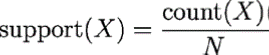
x: frequently item occurs
N: total Transaction
Another important measure is about the rule’s confidence that is a measurement of its predictive power or accuracy.
for example we want to know what is the probability that people purchase Salt then they purchase Pepper or wise versa.
Confidence (Salt–>Pepper), we have to calculate the frequency of purchasing Salt (Support (Salt))
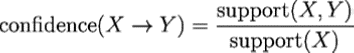
then it we calculate the purchase frequency(Support) of both Salt and Pepper (we already calculated it ).
then The Support (Salt, Peppers) should be divided by Support(Salt):
the Support for Purchasing Salt is 3 out of 4 (0.75)
Support for Purchasing Salt and Pepper is 0.5
by dividing these two number (0.5 Divide to 0.75) we will have: 0.6
So we can say in 60% of time (based on our dataset), if Customer purchase Sale, they will Purchase Pepper.
so we have a rule that “if Customer purchase Salt–>then with 60% of time they will purchase peppers”
However, this percentage is not valid for “Purchasing Pepper then Salt”
to calculate this, we should first calculate the Support for Pepper which is 0.75
then, Divide the Support (Pepper and Sale) to Support (Pepper)=1
So we have below Rules:
“People who purchase Pepper–> will purchase Salt in 100% of time”
Market Basket Analysis in R
for doing the market basket analysis we follow below diagram:
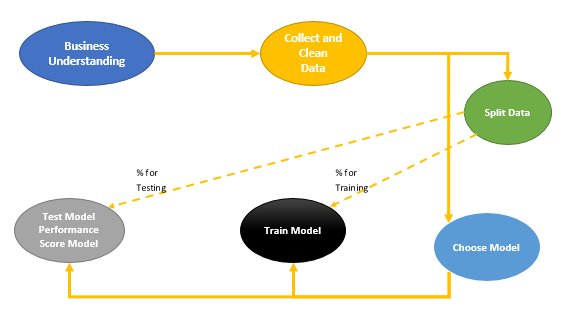
First step- is to identity the business problem: in our case is identify the most shopping list items that have been purchased together by our customers.
Second Step- Gather data and find relevant attributes. we have a data set about 169 customers who purchased some item from grocery stores. The collected data should be formatted.
Third Step- is about selection of the machine learning algorithm regards the business problems and available data. In this model because we are going find the rules in customer shopping behavior that help us to marketing more on that items. Hence, we choose Associative Rules.
After selection of algorithm, we have to pass some percentage of data (more than 70%) for learning. algorithm will learns from current Data. The remaining part of data have been used for testing the accuracy of algorithms.
Step 1- Get Data, Clean Data and Explore Data
We have some data about the Groceries transaction in a shopping store
the first step to do machine learning in R is to import the data set into R.
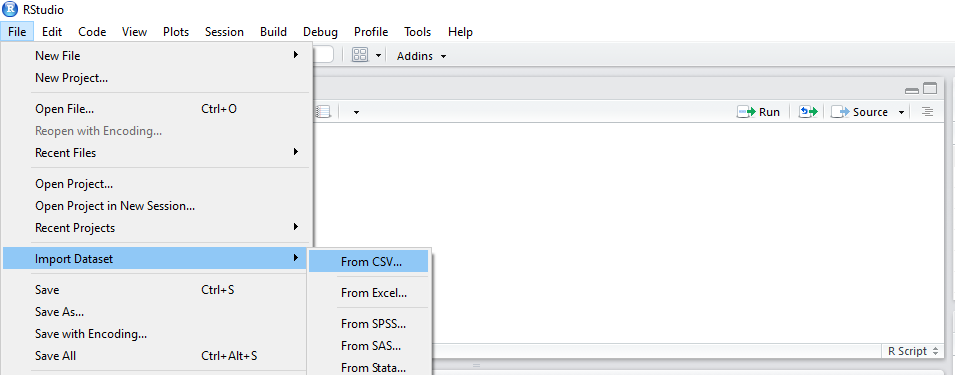
Now we should brows our CSV file.
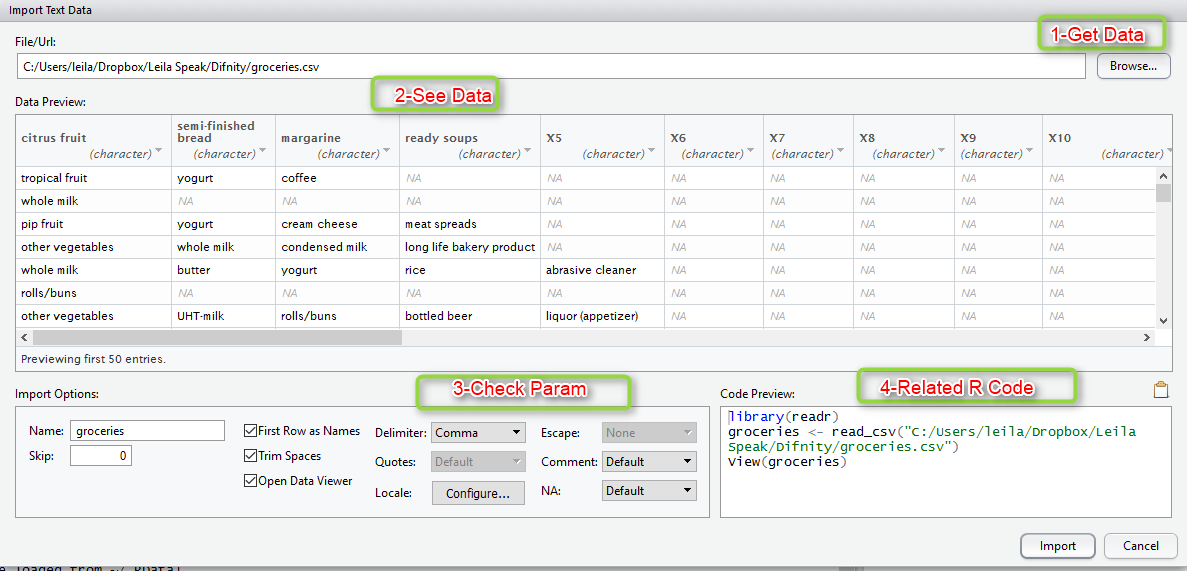
The first five rows of the raw grocery.csv file are as follows:
1-citrus fruit,semi-finished bread,margarine,ready soups
2-tropical fruit,yogurt,coffee
3-whole milk
4-pip fruit,yogurt,cream cheese,meat spreads
5- other vegetables,whole milk,condensed milk,long life bakery product
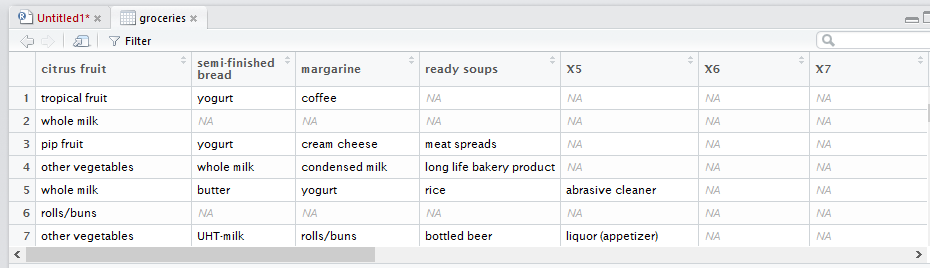
After importing Data, we will see that the imported dataset is not in form of tables, there is no column name
the first step is to create a sparse matrix from data in R (See the Sparse Matrix explanation in https://en.wikipedia.org/wiki/Sparse_matrix).
each row in the sparse matrix indicates a transaction. However, the sparse matrix has
a column (that is, feature) for every item that could possibly appear in someone’s
shopping bag. Since there are 169 different items in our grocery store data, our sparse
matrix will contain 169 columns [2].
to create a data set that able to do associative rules, we have install “arules”.
the below codes help us to that :
install.packages("arules")
library(arules)
groceries <- read.transactions("File address", sep = ",")
So to see the summary of data we run Summary(groceries)

Now we are going to inspect the first five rows in groceries data frame. using “inspect” function to see the first customer’s transactions:

Now we want to draw a bar chart that depict the proportion of transactions containing certain items.
itemFrequencyPlot(groceries, support = 0.1)
itemfrequencyPlot is a function that draw a bar chrt based on the item frequency in transaction list. the first parameter is our dataset, the second on is support which is a numeric value. in this example we set the support as 0.1, which means only display items which have a support of at least 0.1.
The result is like below:
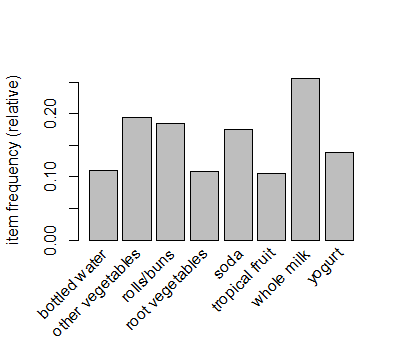
Also if we interested to just see the top 20 items that have been purchased more, we can used the same function but with different inputs as below:
itemFrequencyPlot(groceries, topN =20)
the topN arguments is set to 20 that means just main 20 items.

as you can see in above diagram, whole milk have been purchased more, then Vegetables and so forth.
Step 2- Create Market Basket Analysis Model
We are going to use apriori algorithm in R.
install.packages("apriori")
now we able to call the
groceryrules <- apriori(groceries, parameter = list(support = 0.006, confidence = 0.25, minlen = 2))
we call function apriori()

it gets groceries data set as first input, the list of parameters (such as minimum supports which is 0.06%, the confidence that is 25% and the minimum length of the rule 2) as second inputs.
the result of running this code will be
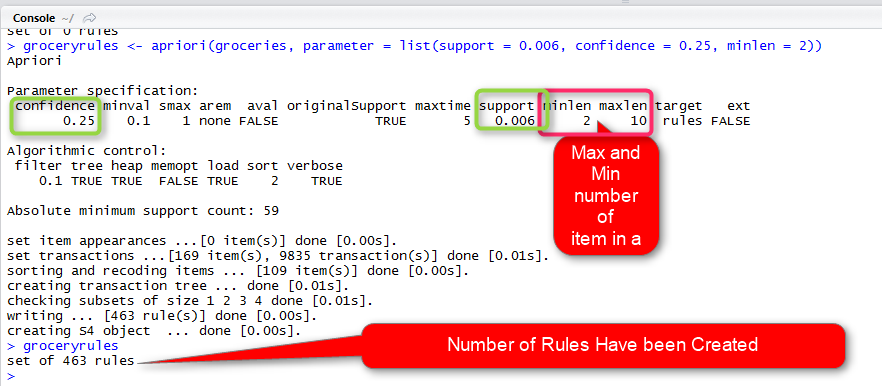
in above picture, we got about 463 rules

by applying summary function we will have summary of Support, Confidence and Lift.
Lift is another measure that shows the importance of the a rule, that means how much we should pay attention to a rule.
Now, we are going to fetch the 20 most important rules by using inspect() function
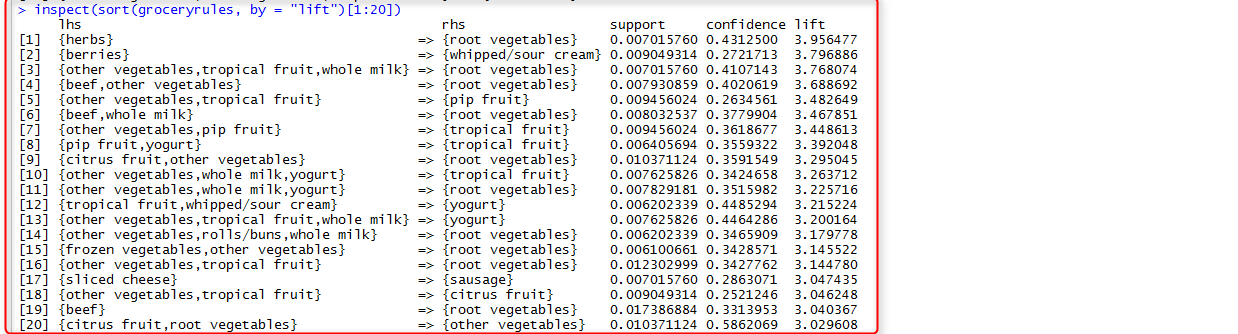
we employ inspect function to fetch the 20 most important rules. as you can see the most important rule is about people who purchasing Herbs—>will purchase Root Vegetable
as any machine Learning algorithm, the first step is to Train data.
[1]. http://www.ms.unimelb.edu.au/~odj/Teaching/dm/1%20Association%20Rules%2008.pdf
[2].Machine Learning with R,Brett Lantz, Packt Publishing,2015.
Stay Tuned for the Next Part.




Thank you very much for sharing this great article, just perfect.
Wonderful. Eagerly awiting part 2
Part 2 http://radacad.com/make-business-decisions-market-basket-analysis-part-2 🙂