
For this blog I thought I would share a handy trick for optimising Power BI using a data modelling solution that is often forgotten or overlooked. It involves focusing on certain columns based on the degree of uniqueness they contain and converting or removing all together from a data model. I will explain how and why this works, show the speed, and size numbers along the way.
To start with I generated a single 4 column table with 10 million rows in a local instance of SQL Server as follows :
The table is representative of a typical transactional dataset but I have also included an ID column which is also common in many data sources.
The details of the data are:
- id : unique whole number between 1 and 10 million. Starts from 1 and each row increments by 1.
- trandate : DateTime data down to the millisecond and spans a time period of 273 days.
- category : carries a single letter of the alphabet between A and J so hold each row can have one of 10 possible values
- value : a random whole number between 1 and 100
The size of this data when exported to CSV format is 360MB which reduced down to 79MB when zipped.
Step 1
I created a new Power BI Desktop file and imported the data into Power BI to establish my baseline benchmark.
The native query generated by the Query Editor was
select
[$Table].[id] as [id],
[$Table].[trandate] as [trandate],
[$Table].[category] as [category],
[$Table].[value] as [value]
from [dbo].[transactions] as [$Table]This took approximately 55 seconds to load to Power BI.
The ID column carries 10 million unique values as expected. The trandate has 9,642,071 unique values so there was a small amount of duplication but is mostly unique. The category column has only 10 unique values and the value column had only 100 unique values.
The image below shows the status of the highlighted trandate column along the bottom showing the number of total rows and the number of distinct values for the selected column.
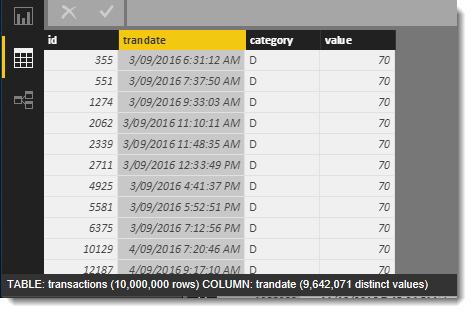
Once saved, the Power BI file size was 289MB! Is this good for 10 million rows? It’s certainly better than the 360MB CSV file but not by much. Certainly not close to the 10:1 compression claimed to be achievable using the SSAS Tabular engine used by Power BI.
I think we can do better than that….
Time to optimise.
In-memory tabular models compress the underlying data to unique values during the load. This is important to understand and key to taking full advantage of this trick.
The following set of data has 6 rows on the left that Power BI will reduce to just 3 on the right. For each of the three rows on the right, the model will maintain a set of summarisation counters that all start at 0. Just imagine these counters as extra columns along the row. As data is loaded the number of rows will only increase when new values are discovered, otherwise the counters on the existing rows will increase as appropriate. The counters will be counting the number of rows, or accumulating sum of the value.
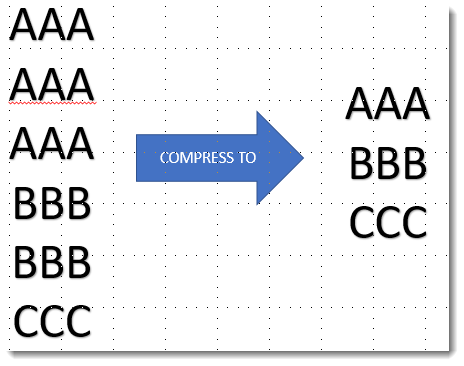
This compression works well for columns with a small number of values repeated across a large number of rows. However a column with data that is highly unique, such as our ID column which 100% unique, no compression can take place and these are the columns we want to target.
The memory values for our memory model looks like this;
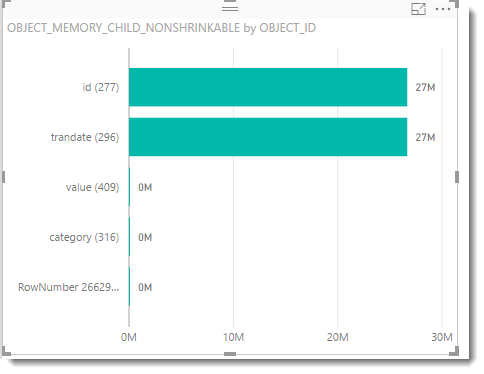
Note that the highly unique columns of id and trandate are significantly larger than the other columns (category and value).
So what might otherwise look like a harmless or possibly helpful column, can actually have detrimental effect on the size of our data model.
Unless we know we need to display or filter on specific ID values, we will remove it from our model.
Step 1. remove the ID column
ID columns are super handy for data-sets supporting applications but aren’t nearly as useful in a well designed BI model. Some might say they are next to useless.
Removing the ID column in the query editor generates the following native query
select [trandate],
[category],
[value]
from [dbo].[transactions] as [$Table]Refreshing was slightly quicker at 49 seconds but the size of the newly saved PBIX file is now only 137MB, dropping from 289Mb. Not a bad start.
The memory picture now looks like this, with no id column;

Importantly, all measures based on Count/Min/Max/Average etc still work as before. All we have lost is the ability to display/filter the value in the ID column.
Step 2. Strip Hours, Minutes and Seconds
Here is where we get our other big win. The chances are, we only want to report my by year, month or day and not down to the detail of hours, minutes and seconds.
The next step is to convert my highly specific trandate column to a date and no longer show the hours, minutes and seconds. The Query Editor now sends the following native query to the DB.
select
convert(date, [_].[trandate]) as [trandate],
[_].[category] as [category],
[_].[value] as [value]
from
(
select [trandate],
[category],
[value]
from [dbo].[transactions] as [$Table]
) as [_]
| trandate before | trandate after (no hours, mins or seconds) |
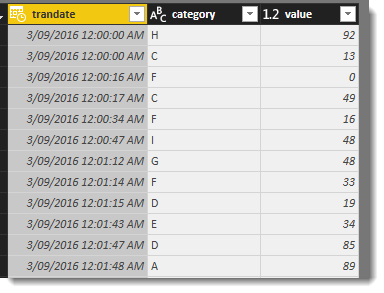 |
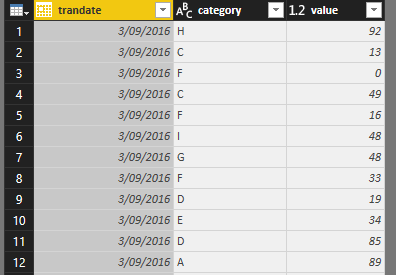 |
Now we only have just 275 unique values in the trandate column down from nearly 10 million unique values. The data load time reduced to 31 seconds and the PBIX file size is just 8.8MB (down from 279MB!).
How does this work? The numbers below show how many buckets the data model needs to manage both before and after the change. Power BI now needs to do a lot less work in the smaller model but can still report Row-count, SUM, MAX, MIN & AVG type measures.
| Trandate | Categories | Data Model Rows | |||
| Before Change | 9,642,071 | x | 10 | = | 96,420,719 |
| After change | 275 | x | 10 | = | 2,750 |

Lets add hours.
Suppose we do want to report data down to an hourly basis. Rather than include the hour as part of our trandate column, lets create another column to hold the hour of the day from the trandate as a whole number between 0 and 23.
The native query now looks like this (isn’t query folding fantastic!)
select
convert(date, [_].[trandate]) as [trandate],
[_].[category] as [category],
[_].[value] as [value],
datepart("hh", [_].[trandate]) as [Hour]
from
(
select [trandate],
[category],
[value]
from [dbo].[transactions] as [$Table]
) as [_]The load time increased as expected to 36 seconds and so did the PBIX file but only to 9.1MB from 8.8MB. Remember this is for 10 million rows.
This technique can also be applied if you want to add minutes and seconds to your data model without increasing your file-size or load times. Just add columns for minutes and seconds.
Splitting the data might be obvious for Datetime columns, but you can also apply the technique using numbers. The value 123,456 could for example be split into two or more columns. One column carrying 123 and the 2nd carrying 456. If you have a very large dataset, this can pay dividends and a little DAX magic can still make your measures show what you expect.
The numbers in summary
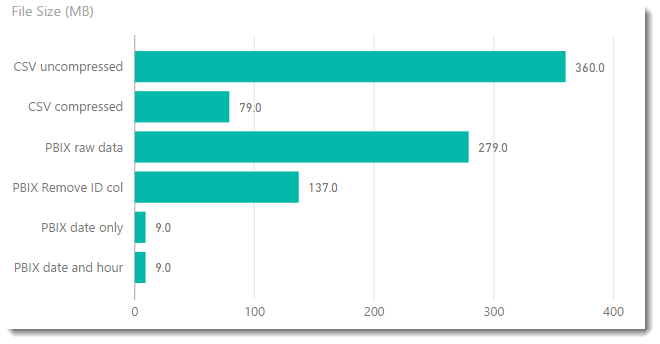
The first chart shows the load time in seconds of the various steps. The main reason why the ‘PBIX Date only’ step is faster is because when loading the data model, there is processing overhead each time the model detects a new value it hasn’t seen before. All the models below load 10 million rows. Note the x-axis on this chart does not start at zero (#badcharts).

The more important chart shows how the file size changed through the process. We started with a CSV equivalent dataset that was 360MB and by applying this easy technique we ended up with data model of around 9MB which is a compression ratio of 40:1. I wouldn’t expect every dataset to produce these savings and I deliberately configured my dataset in a way that would highlight the difference, but it still gives a good idea on what is possible.
Finally
For one last test I pushed the logic up to the SQL DB using the following query which makes the database perform the grouping upstream of Power BI. The query applies the technique of dropping the ID column and splitting the DateTime into two up in the data source.
SELECT
CAST(Trandate AS Date) AS [Trandate] ,
DATEPART(HH,Trandate) AS [Hour],
category ,
COUNT(*) AS [Count of Rows],
SUM(Value) AS [Sum of Value]
FROM Transactions
GROUP BY
CAST(Trandate AS Date),
DATEPART(HH,Trandate),
categoryThe result was a 65,445 row dataset that executed and loaded in just 7 seconds. The PBIX filesize was only 780KB. I can still report most of the same measures using this final approach that I could with my original 51 second, 289MB PBIX file. This, if anything highlights the advantage of having a database engine as your source over a CSV file.
Why should I care?
Smaller models make for faster models. Computations on the optimised model have less ground to cover when calculating formulas and should result in a better end user experience.
Publish and save times are also snappier for the author when dealing with a 9MB file compared with a 289MB file, especially across a network.




Excellent and clear explanation! Thanks a lot!!!
Very interesting post. Sorry if this is a basic question but how do you create those Graphs that show the space taken up by each column?
Hi Ian,
I use Power BI to generate the graphs. I create a separate instance of Power BI Desktop which I use to connect to my main instance. Once I create the connection, I can issue all sorts of DMV queries to get underlying information on the model (memory objects, formulas etc). Maybe I should do a blog on how. 🙂
That would be great 🙂 I am not able to connect my second power bi desktop to my pbix file, which connects to a sql database. I you could point me in the right direction it would be much appreciated 🙂
I will write something up in the next few days. In the meantime, download the excellent (and free) DAX-Studio which will allow you to connect to an instance of Power BI Desktop. I will post step by step details when I get a chance. 🙂
Very clear information, thank you for that!
It`s not the focus of the blogpost, but could Power BI also show the milliseconds from the initial “Trandate”-Column? Probably the milliseconds exist in the Power BI engine, due to the high unique values ratio of that ratio. But is it possible to show the milliseconds (since there is no datatime-format including milliseconds) and/or do calculations with that?
Hi Robert,
In this blog I strip the milliseconds from the raw data so it’s not available to Power BI anywhere. But if the milliseconds were important, I’d create a column just for that and write some fancy DAX to access it just for the measures that need it.
What is something you might need the milliseconds for in Power BI?
Phil
I have a lot of ids that are represented by dates with milliseconds are use to join my tables with multi million (even billions) of records. I cant create joins as PBI says that the values aren’t unique but its seems to be believing there are duplicates once milliseconds are stripped. How to go around that?