
Here is a technique you might consider if you need to split text down to individual words. This could be used to help count, rank or otherwise aggregate the words in some longer text. The approach detailed here uses spaces as a delimiter and will not be tripped up if multiple spaces are used between words.
There is no SPLIT function in DAX, so this approach uses the MID function to help find words.
The PBIX file used for the blog can be downloaded here.
[Updated 14th Oct, 2018]
A slightly updated version that uses UNICHAR/UNICODE to preserve the case (“A” versus “a”) of each letter can be downloaded here. The reason for this is DAX stores a dictionary of unique values for every column. It is the first instance of any value that is added to the dictionary and assigned a new ID. Subsequent values that are considered the same “A” and “a” are considered the same are assigned the same ID. Using the UNICHAR/UNICODE version helps preserve the original case of each letter.
Output words to a Table
The first example takes a simple sentence and extracts each word in the sentence to its own row.
The first part of the DAX for the calculated table is as follows:
Output to a Table =
VAR Sentence = "The quick brown fox jumps over a lazy dog"
VAR SentenceCleaned = " " & Sentence & " "
VAR LengthOfSentence = LEN(SentenceCleaned)
VAR PivotedSentence =
ADDCOLUMNS(
GENERATESERIES(1,LengthOfSentence) ,
"Letter" ,
MID(Sentence,[Value],1)
)
The initial variable called Sentence stores the text to be broken apart. Notice I have deliberately injected multiple spaced between some of the words. Feel free to replace this with your own text.
I then add a space to the start and end of the text to make sure the first/last words can be extracted. The LengthOfSentence counts the number of individual characters in the text. This is then used in the next step to create a pivoted version of the text that contains a row for every character.
The data stored in the PivotedSentence table expression will now look like this:

Next, I make use of the number in the [Value] column to add a column that will represent the upper and lower bounds of each word using the space as the delimiter.
var Boundaries =
ADDCOLUMNS(
PivotedSentence ,
"PrevSpace", MAXX(FILTER(PivotedSentence ,''[Value] < EARLIER([Value]) && [Letter] = " "),[Value]) + 1,
"NextSpace", MINX(FILTER(PivotedSentence ,''[Value] > EARLIER([Value]) && [Letter] = " "),[Value]) - 1
)
This will add two columns that carry the character position for the start/end of each word. You’ll notice I have highlighted the rows belonging to the word “quick”. The number 6 in the [PrevSpace] column means this word begins at position 6 in the text, while the 10 in the [NextSpace] column represents the end of the word. Every letter in the word carries the same value in these columns.
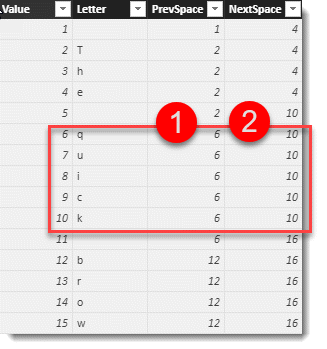
The TableOfWords variable creates a single column table with the unique values of the [PrevSpace] column – after filtering out any row with a space character. The IN command could have additional items added to the filter.
VAR TableOfWords =
SELECTCOLUMNS(
SUMMARIZE(
FILTER(Boundaries,NOT [Letter] IN {" "}) ,
[PrevSpace]
),"Word Position",[PrevSpace]
)
For this example, the table expression in the TableOfWords variable will look like this:
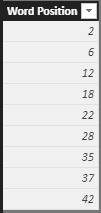
The rows in this table expression could now be counted if the objective is simply to produce a word count. I will show that code further down in a calculated column.
The next variable adds a column to the table expression that unpivots the letters in the Boundaries table expression using the CONCATENATEX function filtered down to only the letters that belong to the same word.
VAR TableOfWords2 =
ADDCOLUMNS(
TableOfWords,
"Word",
CONCATENATEX(
FILTER(
Boundaries,[PrevSpace]=[Word Position]),
[Letter],
,
[Value]
)
)
Now we have a table expression showing the split words as follows:
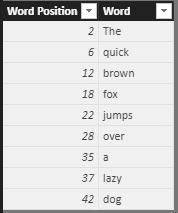
The RANKX function used the number in [Word Position] column to add a useful column that could be used to help extract the “first 5 words” or “Last N words” in some text.
VAR RankedWords =
ADDCOLUMNS(
TableOfWords2 ,
"Word Number" ,
RANKX(TableOfWords2,[Word Position],,ASC)
)
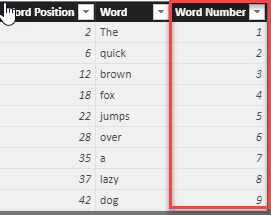
The full calculation is here :
Output to a Table =
VAR Sentence = "The quick brown fox jumps over a lazy dog"
VAR SentenceCleaned = " " & Sentence & " "
VAR LengthOfSentence = LEN(SentenceCleaned)
VAR PivotedSentence =
ADDCOLUMNS(
GENERATESERIES(1,LengthOfSentence) ,
"Letter" ,
MID(SentenceCleaned,[Value],1)
)
var Boundaries =
ADDCOLUMNS(
PivotedSentence ,
"PrevSpace", MAXX(FILTER(PivotedSentence ,''[Value] < EARLIER([Value]) && [Letter] = " "),[Value]) + 1,
"NextSpace", MINX(FILTER(PivotedSentence ,''[Value] > EARLIER([Value]) && [Letter] = " "),[Value]) - 1
)
VAR TableOfWords =
SELECTCOLUMNS(
SUMMARIZE(
FILTER(Boundaries,NOT [Letter] IN {" "}) ,
[PrevSpace]
),"Word Position",[PrevSpace]
)
VAR TableOfWords2 =
ADDCOLUMNS(
TableOfWords,
"Word",
CONCATENATEX(
FILTER(
Boundaries,[PrevSpace]=[Word Position]),
[Letter],
,
[Value]
)
)
VAR RankedWords =
ADDCOLUMNS(
TableOfWords2 ,
"Word Number" ,
RANKX(TableOfWords2,[Word Position],,ASC)
)
RETURN
RankedWords
Add word count calculated column
In the same PBIX file, I have a ‘Dimension Stock Item’ table that has a text description for each item. A slightly modified version of the above calculation is as follows:
Word Count =
VAR Sentence = 'Dimension Stock Item'[Stock Item]
VAR SentenceCleaned = " " & Sentence & " "
VAR LengthOfSentence = LEN(SentenceCleaned)
VAR PivotedSentence =
ADDCOLUMNS(
GENERATESERIES(1,LengthOfSentence) ,
"Letter" ,
MID(Sentence,[Value],1)
)
var Boundaries =
ADDCOLUMNS(
PivotedSentence,
"PrevSpace", MAXX(FILTER(PivotedSentence,''[Value] < EARLIER([Value]) && [Letter] = " "),[Value]) + 1,
"NextSpace", MINX(FILTER(PivotedSentence,''[Value] > EARLIER([Value]) && [Letter] = " "),[Value]) - 1
)
VAR TableOfWords =
SELECTCOLUMNS(
SUMMARIZE(
FILTER(Boundaries,NOT [Letter] IN {" "}) ,
[PrevSpace]
),"Word Position",[PrevSpace]
)
RETURN
COUNTROWS(TableOfWords)
The approach is the same and still pivots the text into a table expression with a single row per character. Boundaries are established for each word, but there is no need to unpivot as a word count can be obtained by doing a COUNTROWS using the TableOfWords table expression.




I am following your example with a different phrase, and found something weird. My phrase has words which starts with the same letter as the initial letter of the phrase.
“The lazy fox thinks twice”. The list of words will bring back Think and Twice with uppercase letter 🙁
I could not find out why.
Aha, I know why. DAX is not case sensitive and will store an uppercase “A” the same way as a lower case “a”. To get around this, you would need to convert to unicode first at the PivotedSentence variable. I will amend this later today. 🙂
Please download this PBIX file to get a version that uses the UNICHAR/UNICODE functions to fix this behaviour.
https://1drv.ms/u/s!AtDlC2rep7a-qkU1b2GBDA_pNQrB
Philip, for some reason
“A quick brown fox jumps over a lazy dog”
still returns:
A
quick
brown
fox
jumps
over
A
lazy
dog
I have no idea why the second single “a” gets capitalized although the Letter is 97. Can you reproduce this? Is it a bug?
Hi there,
Did you try the updated PBIX file from here? It includes some additional steps to store the unicode value for each character, rather than the text form.
https://onedrive.live.com/?cid=beb6a7de6a0be5d0&id=BEB6A7DE6A0BE5D0%215445&authkey=!ADVvYYEMD-k1CsE
Hello Seamark, great technique to split words and get more measures about each its.
The link for download is not working, it has reloaded the same page.
thanks a lot
regards
Heron Carlos
I have fixed the link now. Sorry about that. There are two versions you can download. They are both very similar.
Nice article.
In the past I used trying substitute, pathitem for the words. Also, I used R script. I used for word cloud.
If possible take a 10mb or 100mb text and list the performance also.