

Text classification is the fourth model in AI builder. But what is text classification and how we can use it for our data?
Text classification or text tagging or text categorization is about organizing and grouping text based on their concepts. We are able to group the text and put a predefined tags/ label to them.
this helps us to able to manage texts.
this can be used to detect the type of email we have the simple approach is to label them based on SPAM or Inbox.
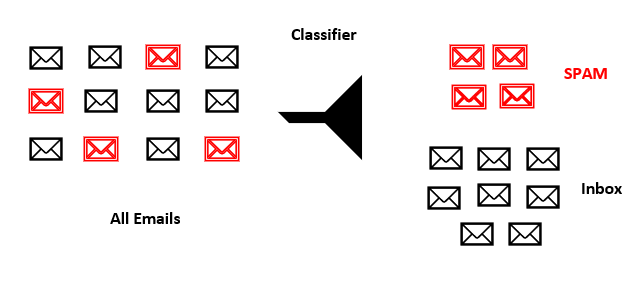
In my scenario, for example, I can categorise the email to three main categories
Conference and Meetup and training, Consulting and customer, and general email
another example of text classification is about the insurance companies like categories the claim statements to
Car and Vehicle, companies and labour, House and content.
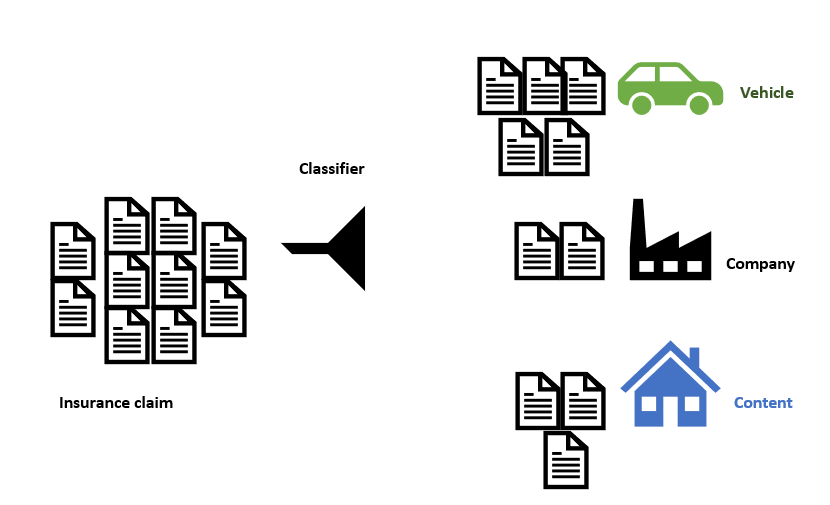
This service in AI Builder can be a good choice for these problems.
In this example, we are going to classify the comment of people who visit a health centre with label the comments as Care, Staff, Facilities, Check-in,
Required Data
Make sure you access to Common Data Service, then you need to upload a file that contains the text and the related tags for each text
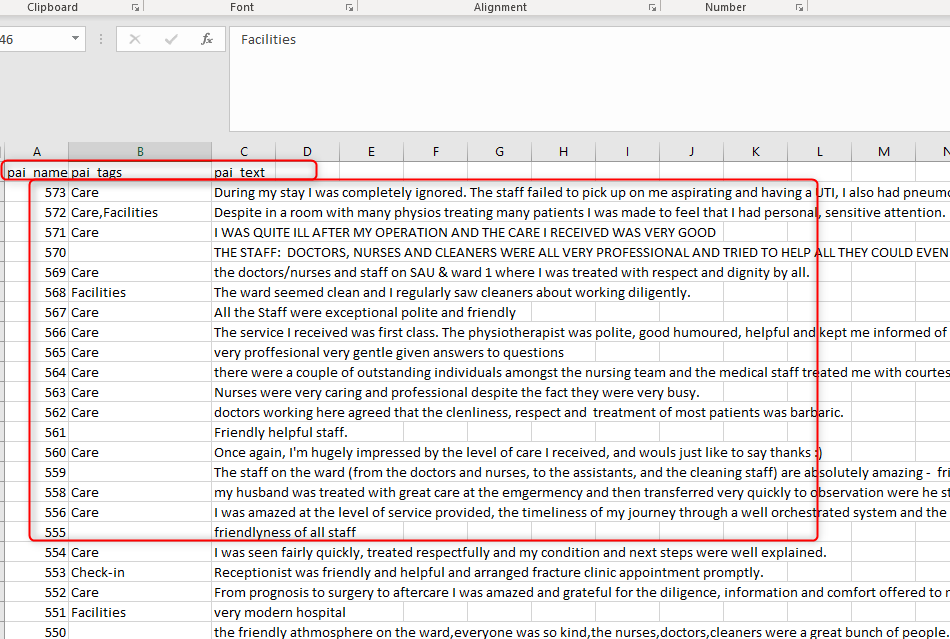
In this stage, I uploaded the text to my blob storage in Azure and copy the address.
you can access the file via
https://github.com/microsoft/PowerApps-Samples/tree/master/ai-builder/labs
Next Login to Power Apps, in the environment that already AI builder, has been set up.
Next, click on the Data and Get Data
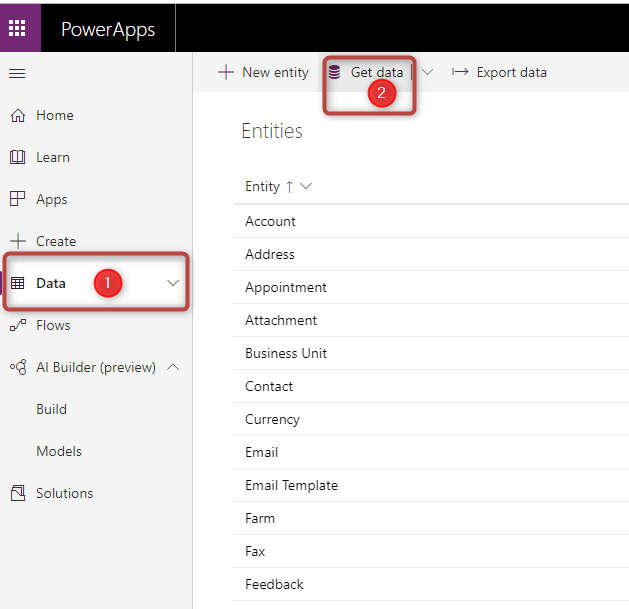
Then you need to connect to the data source
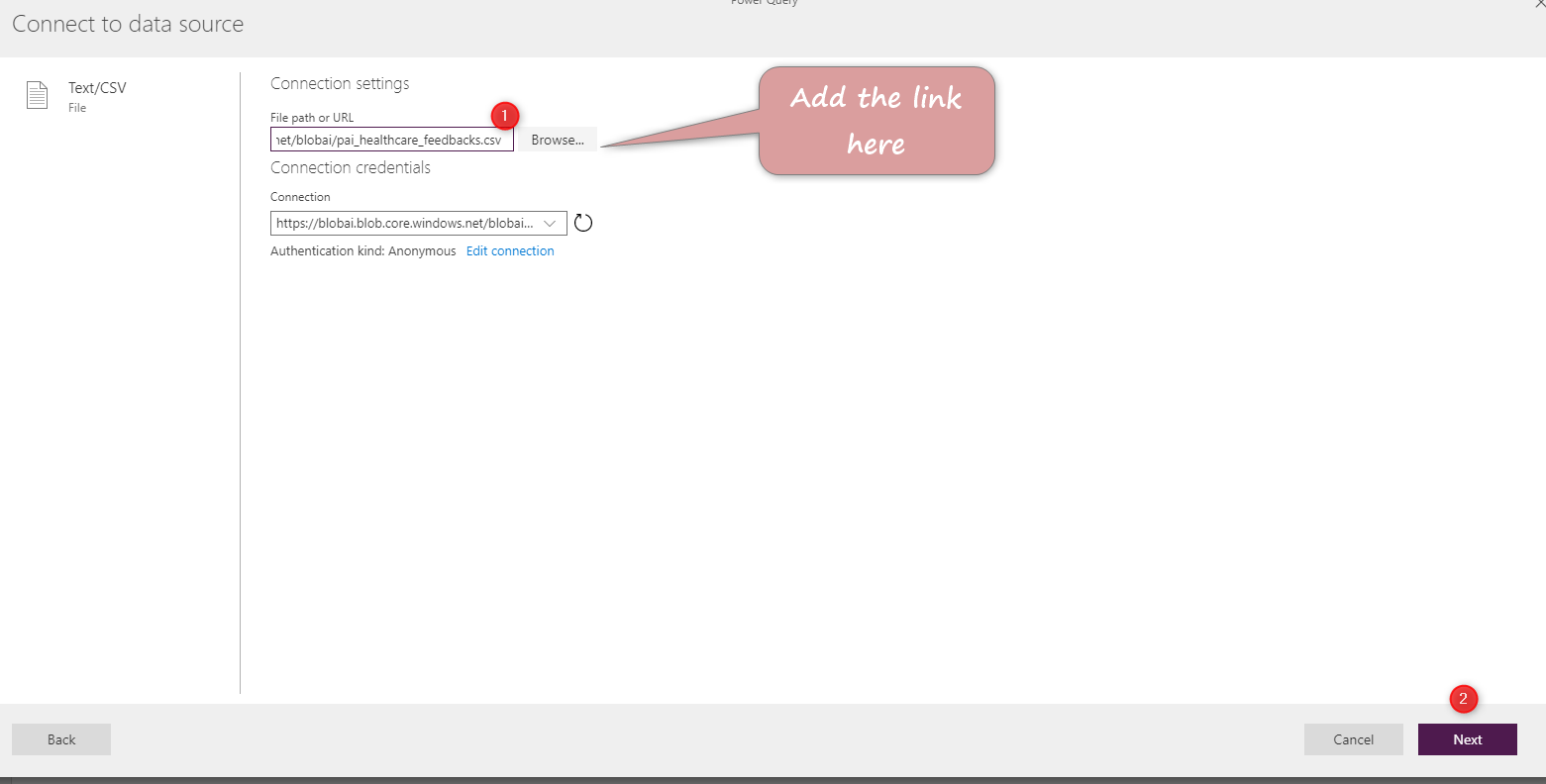
For this practice, I remove the first column, then remove the nulls value.

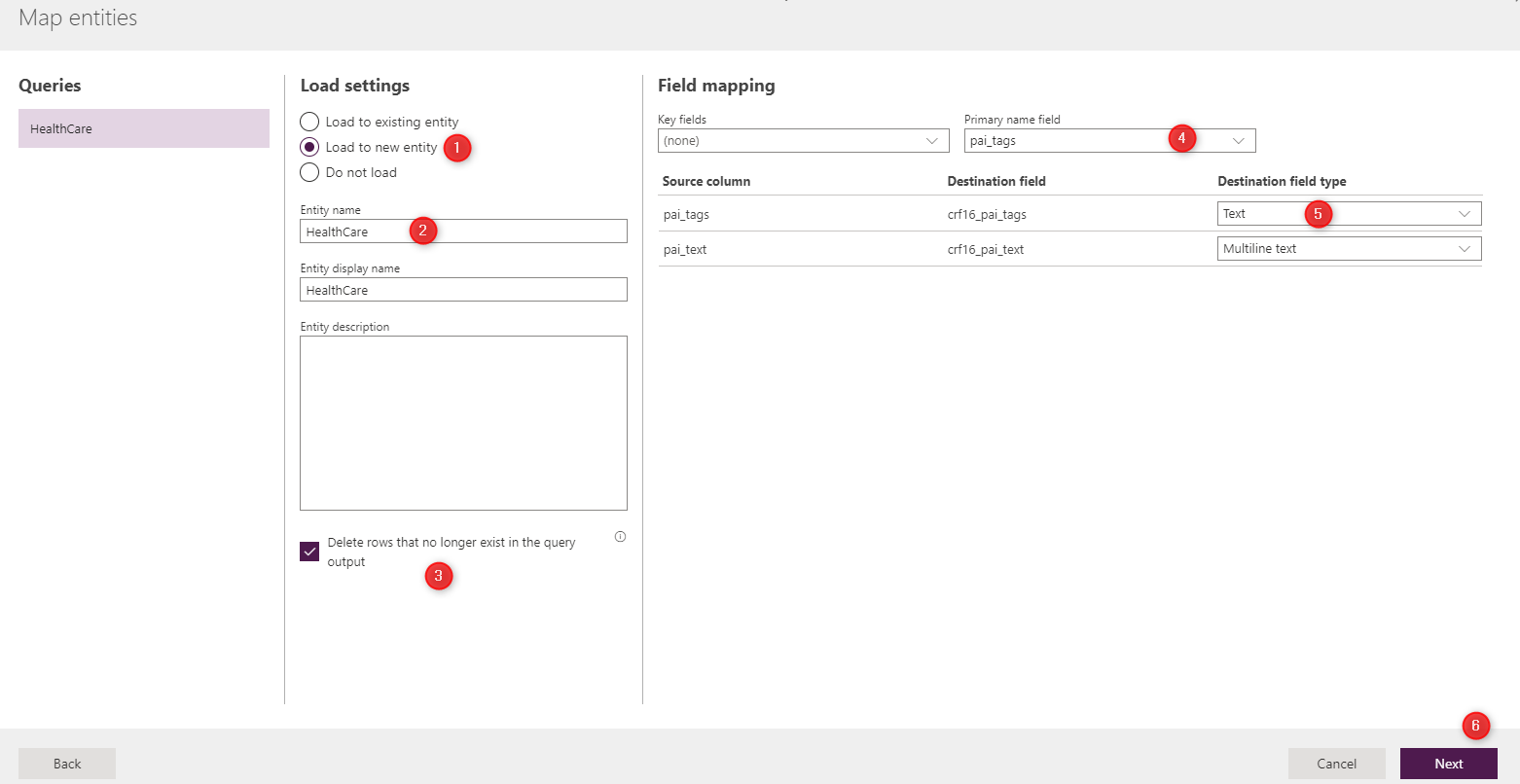
Also, you need to Map entities as below
it will take couple of minutes to load data in Common Data Service, then you can see the data
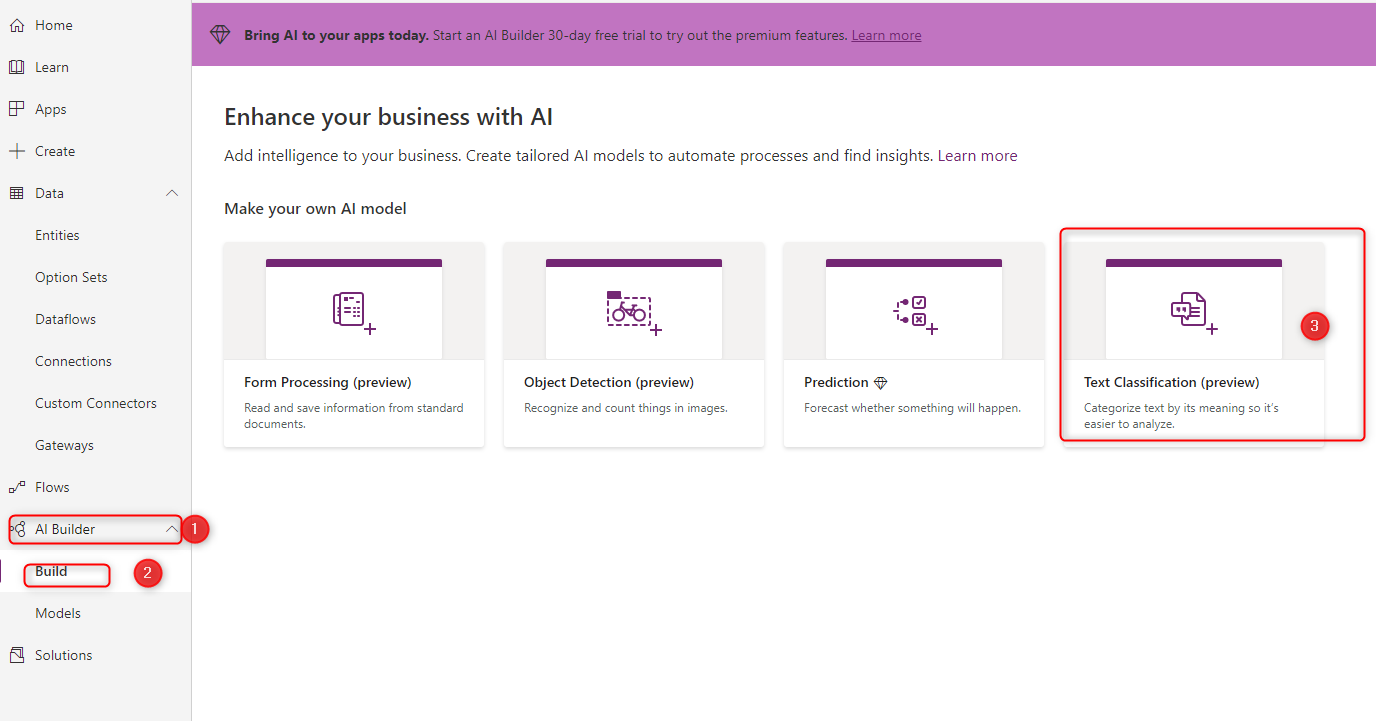
Then, you need to choose the Text Classification from the AI Builder, Build Model.
Put a Name for the model, and you will see a reminder about preparing a dataset with Text and related Tags ( we already upload it)
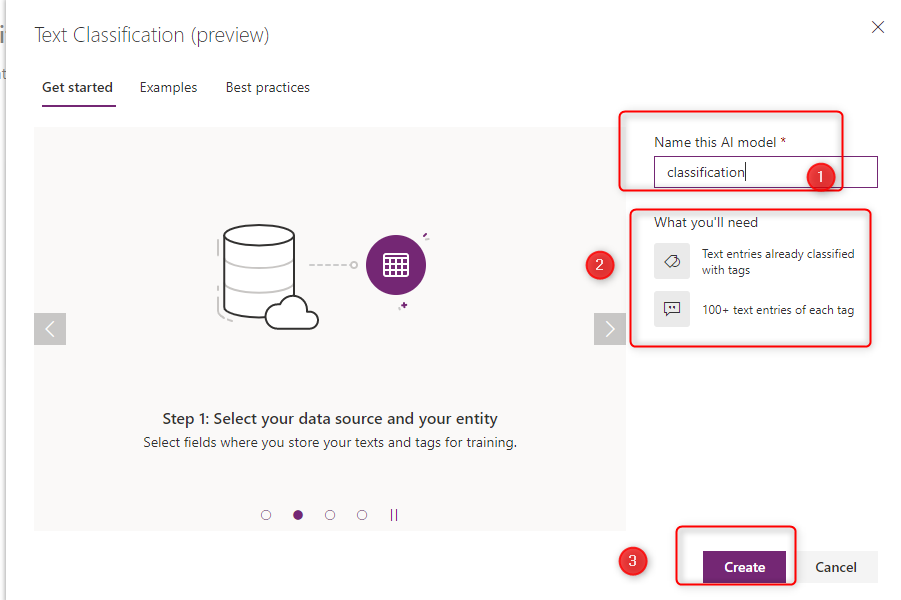
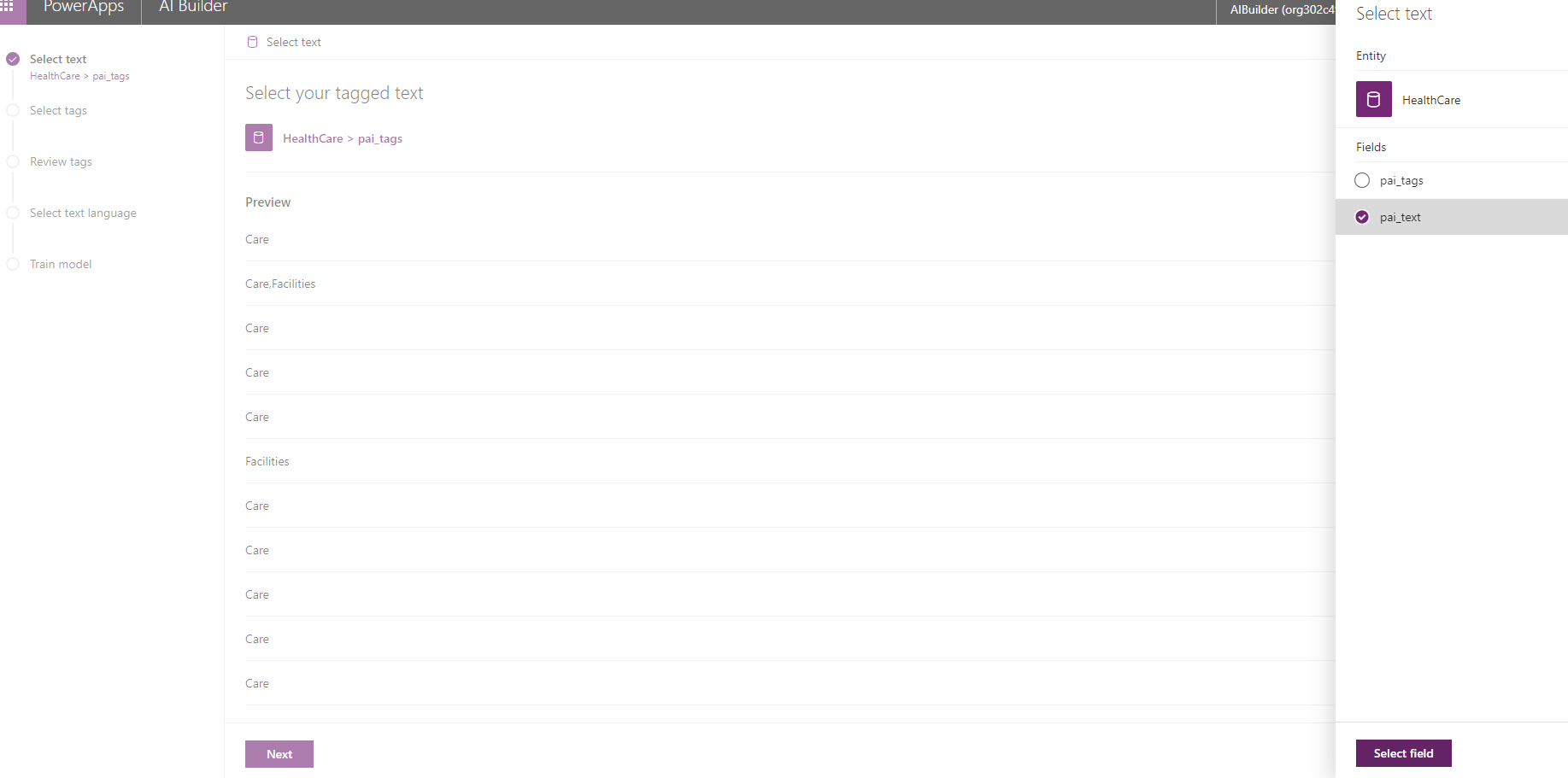
As you can see in the below picture, there are five steps, the first is about selecting the related Text field.
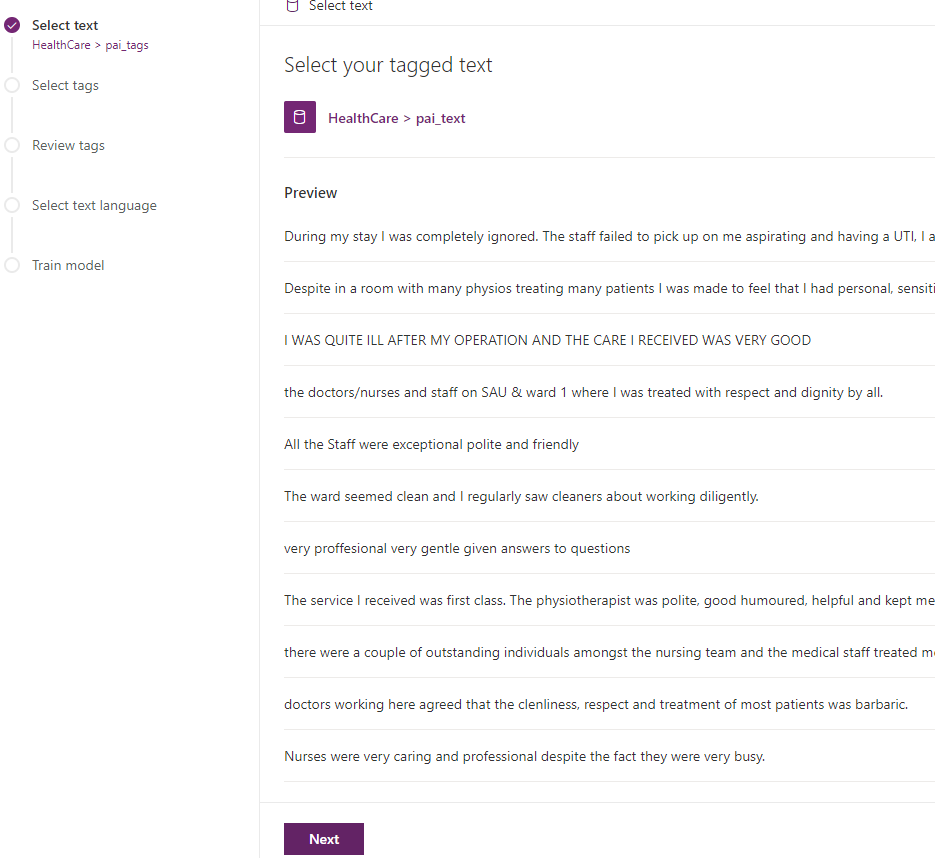
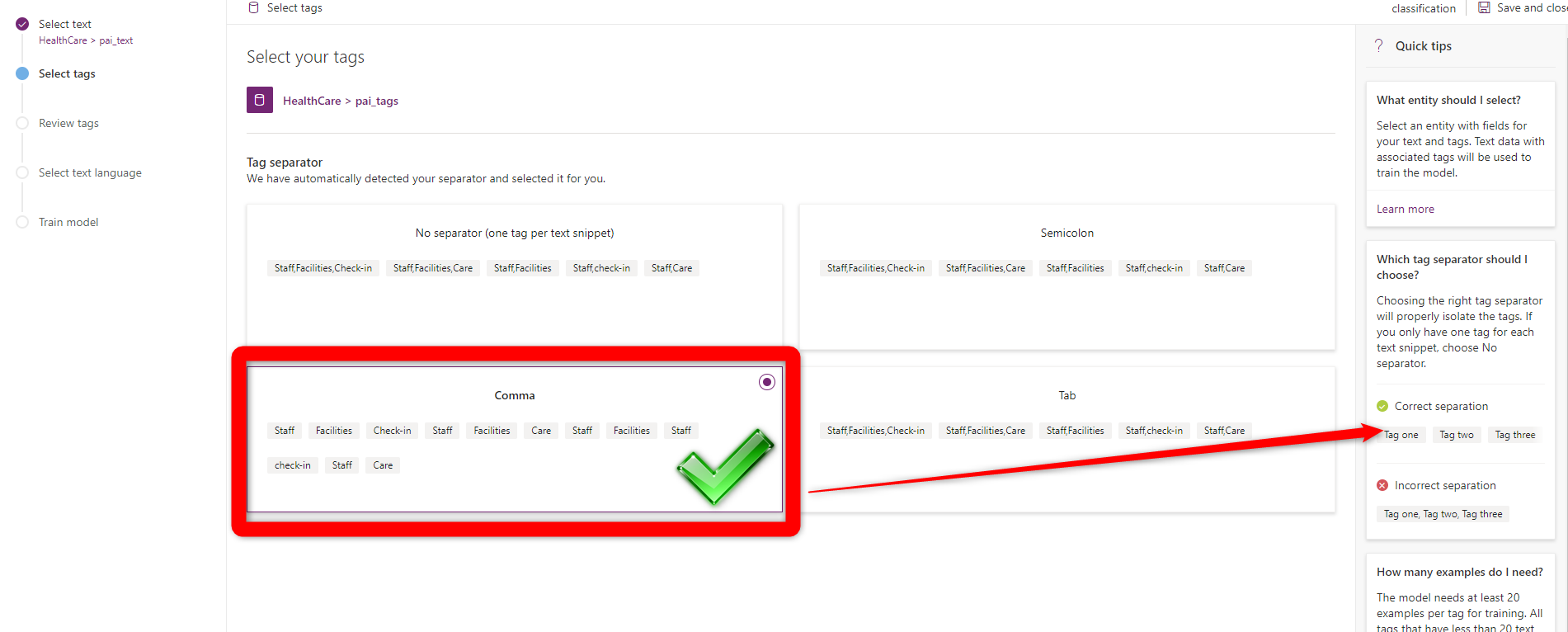
In the next step, you need to specify the tags, by default the AI Builder identify the separator of the tags and choose the one that is more related.
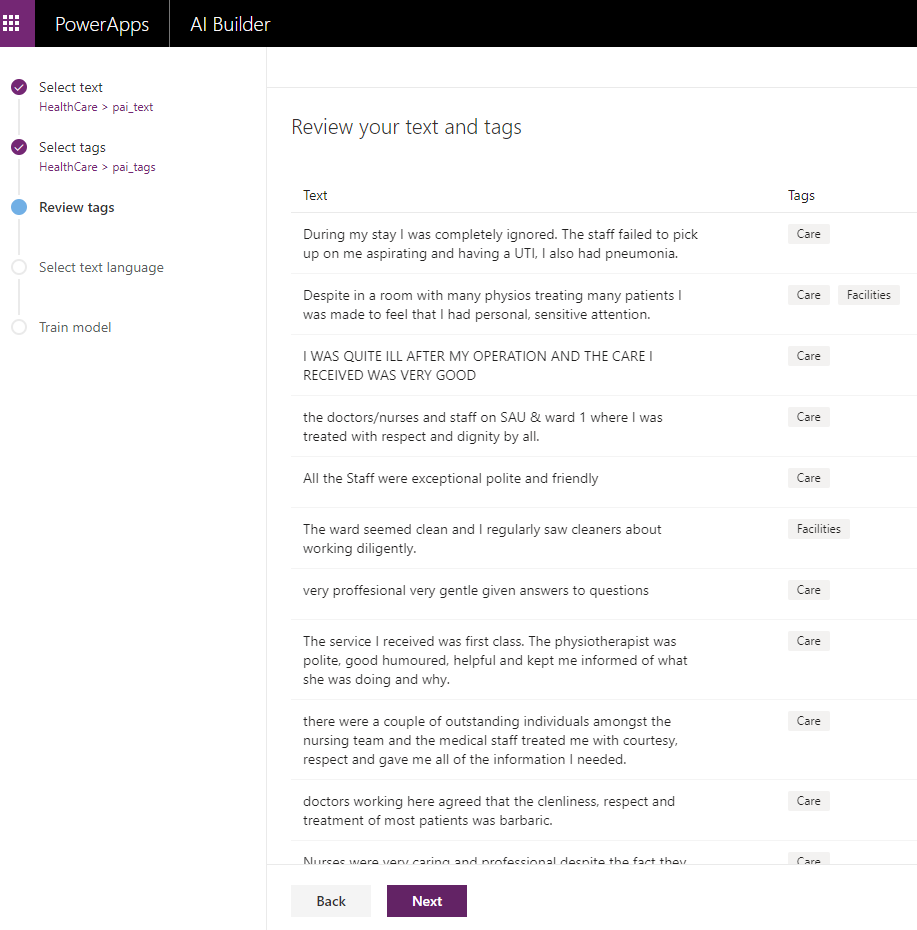
In the third step, you can review the tags and the related text.
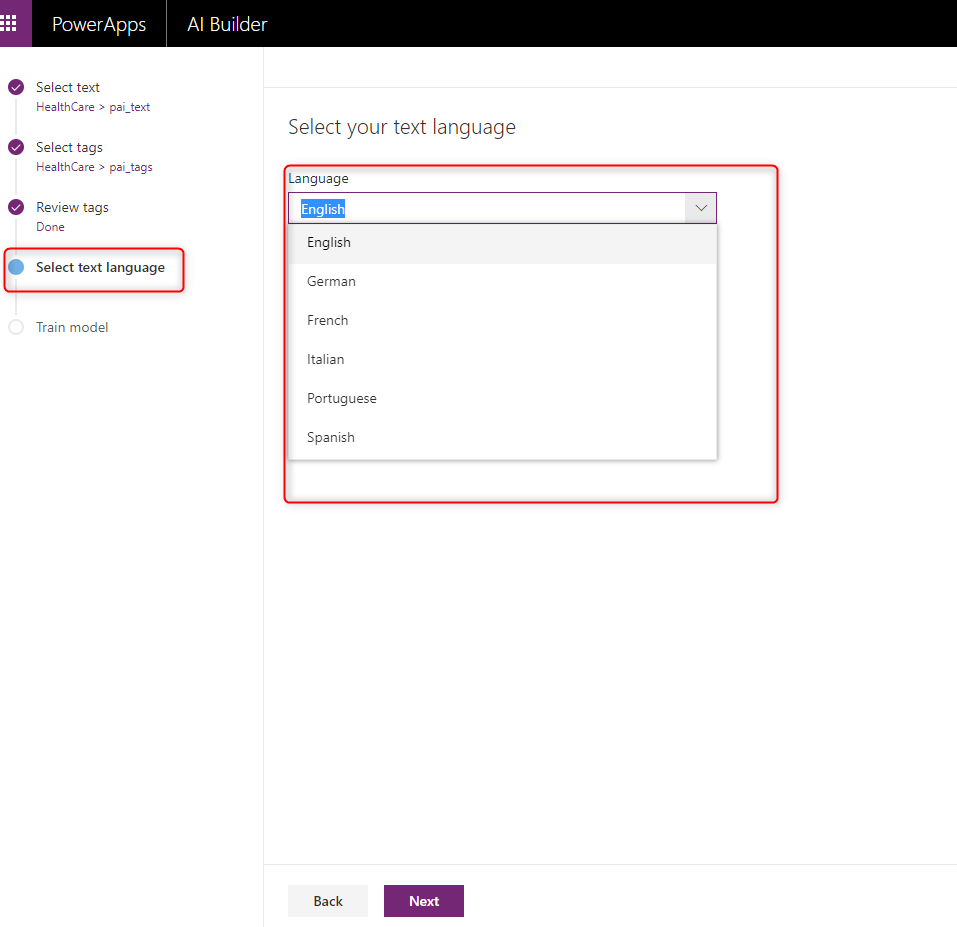
Finally, before training model, you can specify the language of the text, as you can see in the below picture, English, German, French, Spanish, Italian, and Portuguese are supported now.
Next, you can train the model, that will take a couple of minutes, finally you able to see the performance and you can test it to see how much you can rely on it, moreover, you can publish it. By publishing it you can use it in Microsoft Flow or on available data in Common Data Service.

In this post, I just test the model and in the next one, I will show how to use this model to classify data.




