
In previous Posts Part 1, Part 2 and Part3 I have explain some about the azure Ml environment, how to import data into it and finally how to do data transformation using Azure ML component.
In this post and the next one I am going to show how to do a Machine Learning in Azure ML using different components via a scenario.
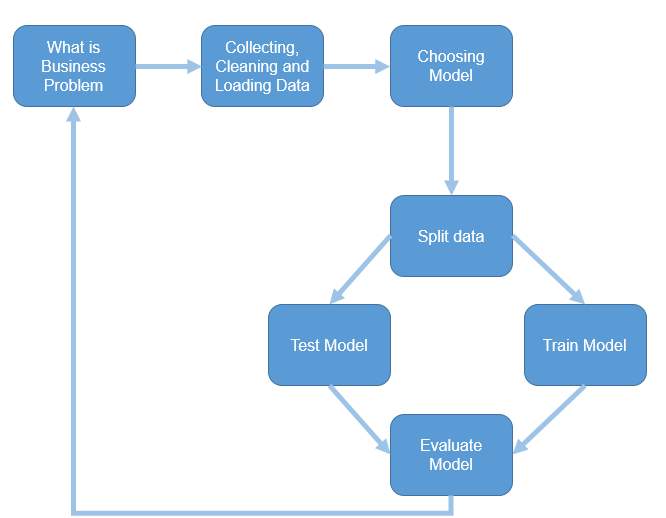
First based on the Machine Learning Process (see below image), the first step is to identify the business problems
What is Business Problem ?
I am going to predict whether a customer will be Benign or Malignant. I have a dataset that shows the laboratory results of cancer cells, also the patients ID , and the final doctor’s diagnosis as “B” and “M”.
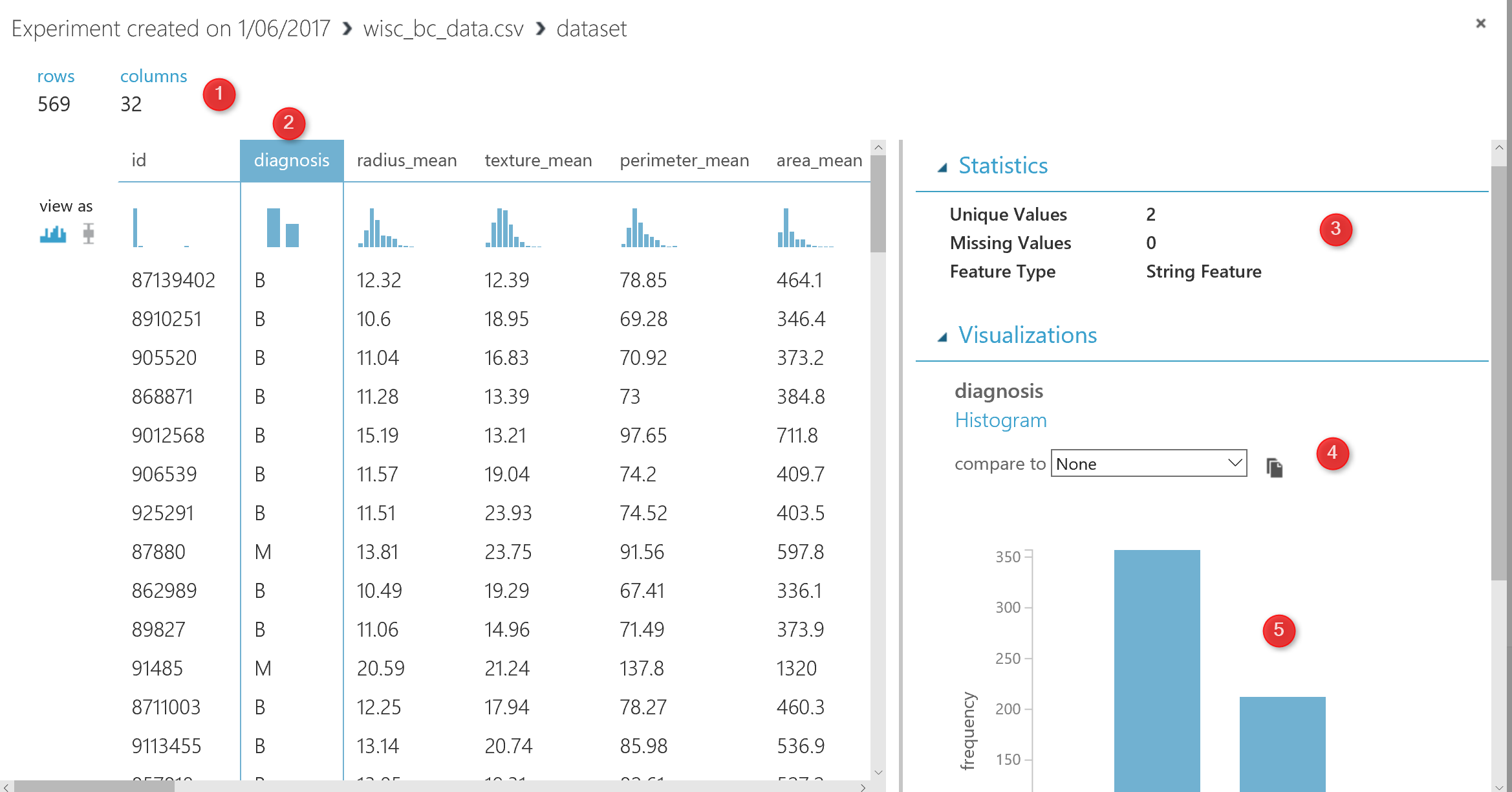
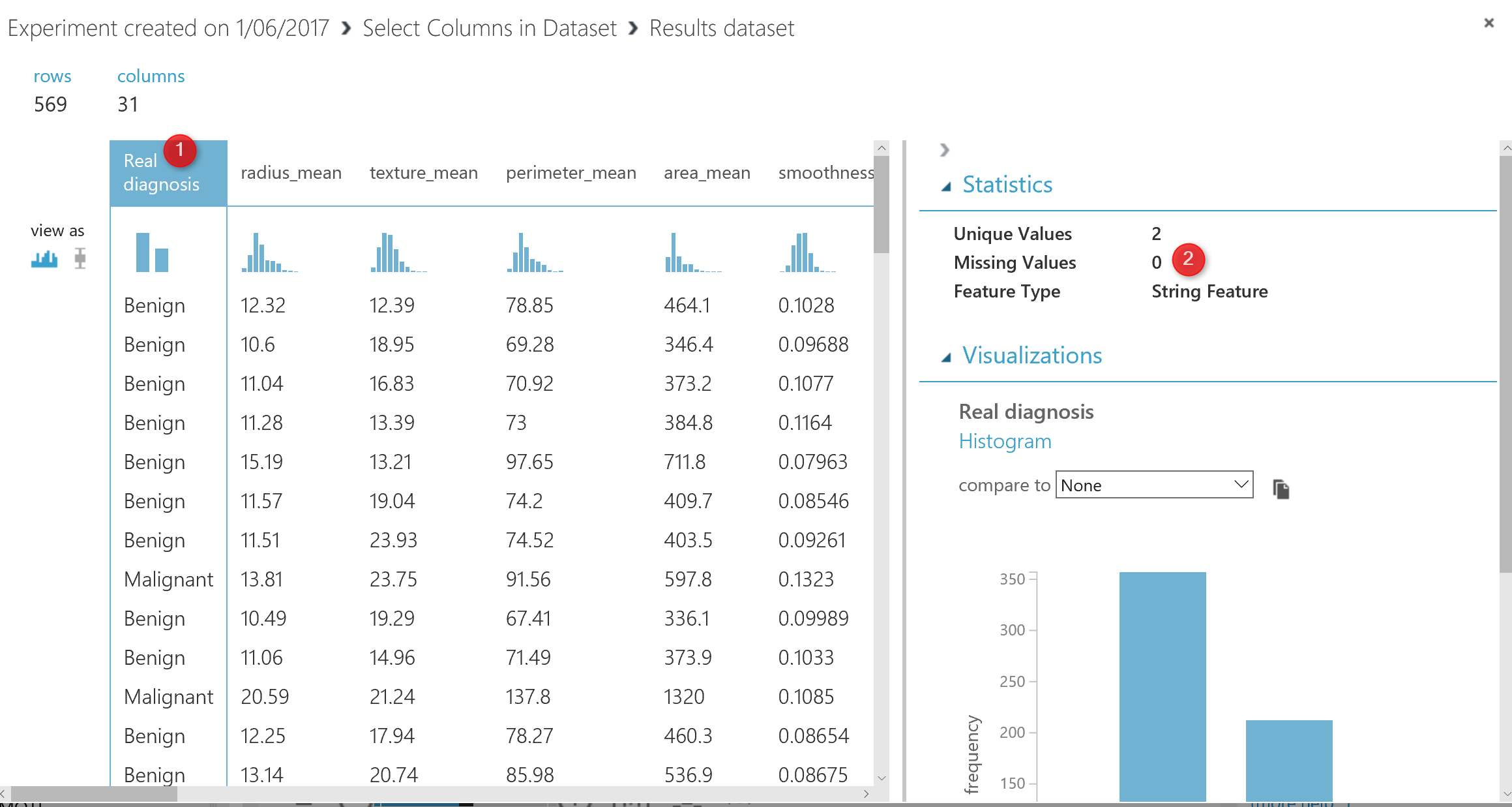
I have imported the data as a “CSV” file, the CSV file has 569 records and 32 columns (see below picture). In the right side of the picture, you will see a menu that shows the statistics about the data (number 3). Moreover, in the number 4 and 5, you able to see the chart that shows the histogram of the diagnosis column data.

I am going to change the data description of the diagnosis. I want to replace “B” with “Benign” and “M” with “Malignant“. This can be done using “SQL Transformation“. SQL Transformation component can be access under the “Data Transformation” component. Just drag and drop it to the experiment area, then connect it to the dataset as number 2 in the below picture. To write SQL code just click on the component, then write a normal SQL Statement to transfer data as below
“select case diagnosis WHEN ‘B’ then ‘Benign’ else
‘Malignant’ end as [Real diagnosis], * from t1 ;”
The code will replace the value of column “diagnosis”. as you can see in the above code, the data has been selected from “t1” table. So what is “T1” table , As you can see in the below picture (number 2). SQL transformation component has three main input nodes. The first node is called “t1” as we connect the dataset to it. so if you connect you dataset to the second node then in SQL scripts you should select your data from “t2”

The next step for Data cleaning is to remove the columns that we think does not have impact on the prediction.
Select Column Data
I am going to remove the “Patient ID” from dataset using “Select Columns in Dataset” to select the columns that I need.
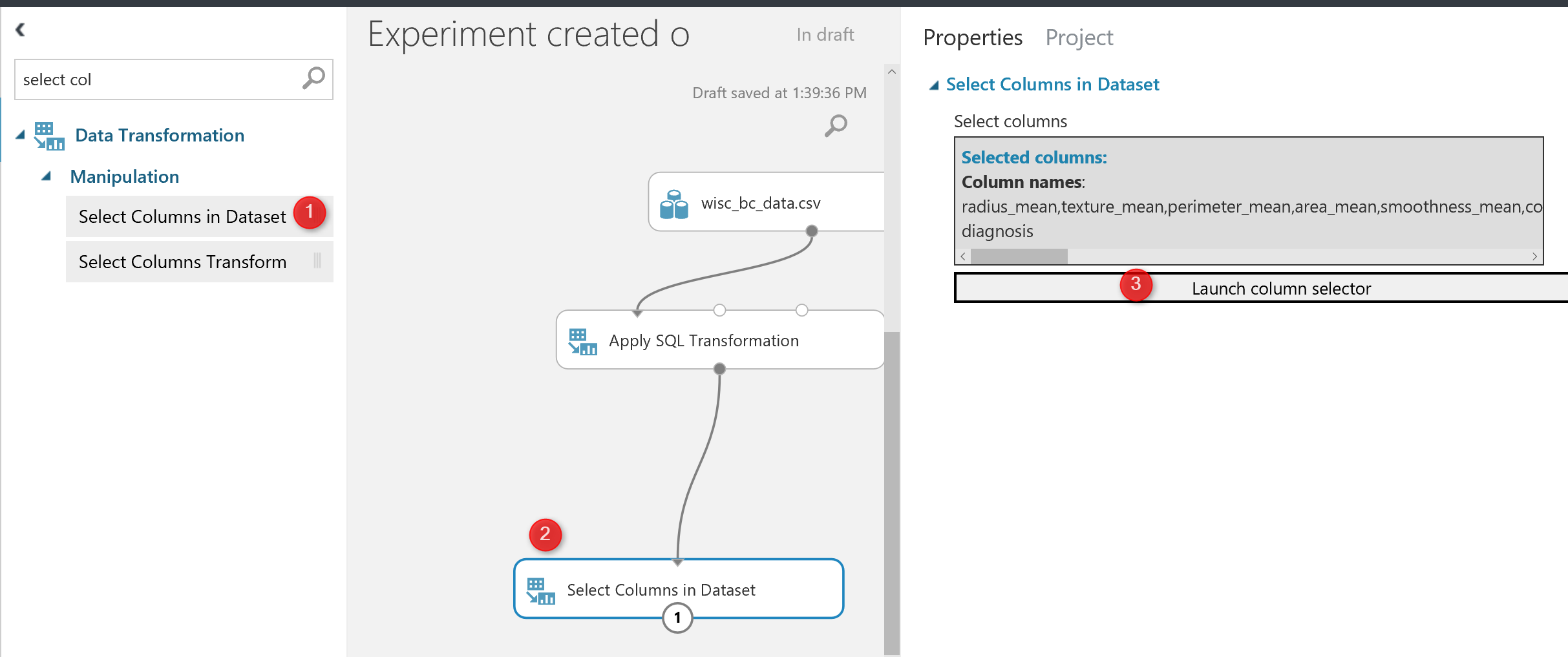
after run the code, we will see the below results, so the “ID” columns has been r3emoved and we have now 31 columns instead.
There are some possibility to have “Missing Values“. Missing value may impacts on the pr3ediction results, so always recommend to remove them. There is a component in Azure ML called “Clean Missing Values” as shown below. This component able to remove data that does not have at value. (see below picture).

The next step for data cleaning is to change the data structure, the diagnosis data column was “string ” type ( see the below picture ), before adding the edit meta data component, the diagnosis column was “String Feature”.

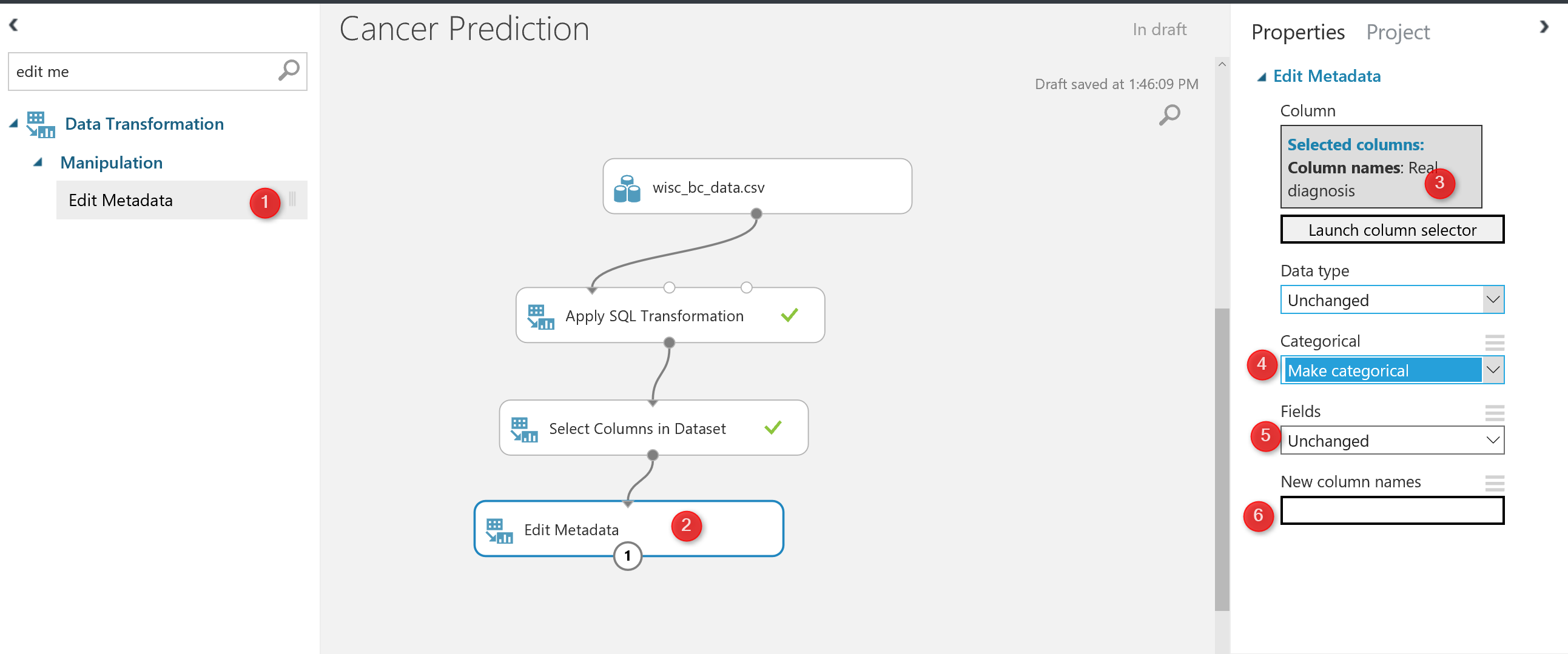
for doing the prediction, we are going to use “Two-Class” algorithms that need a “categorical ” data, hence we need to change the diagnosis data type.to change the data type in Azure Ml we have a component that helps us name “Edit Metadata”.
as you can see in above picture, I have drag and drop this component into the experiment area, then in number 3, I specify the column that I need to change the data structure. Following, in number 4, I change the column to categorical data.
you also able to change the name of the column in Edit meta data component as shown in number 6.
Now I am going to run the code. However I just want to see the final result of adding “Edit Metadata”.
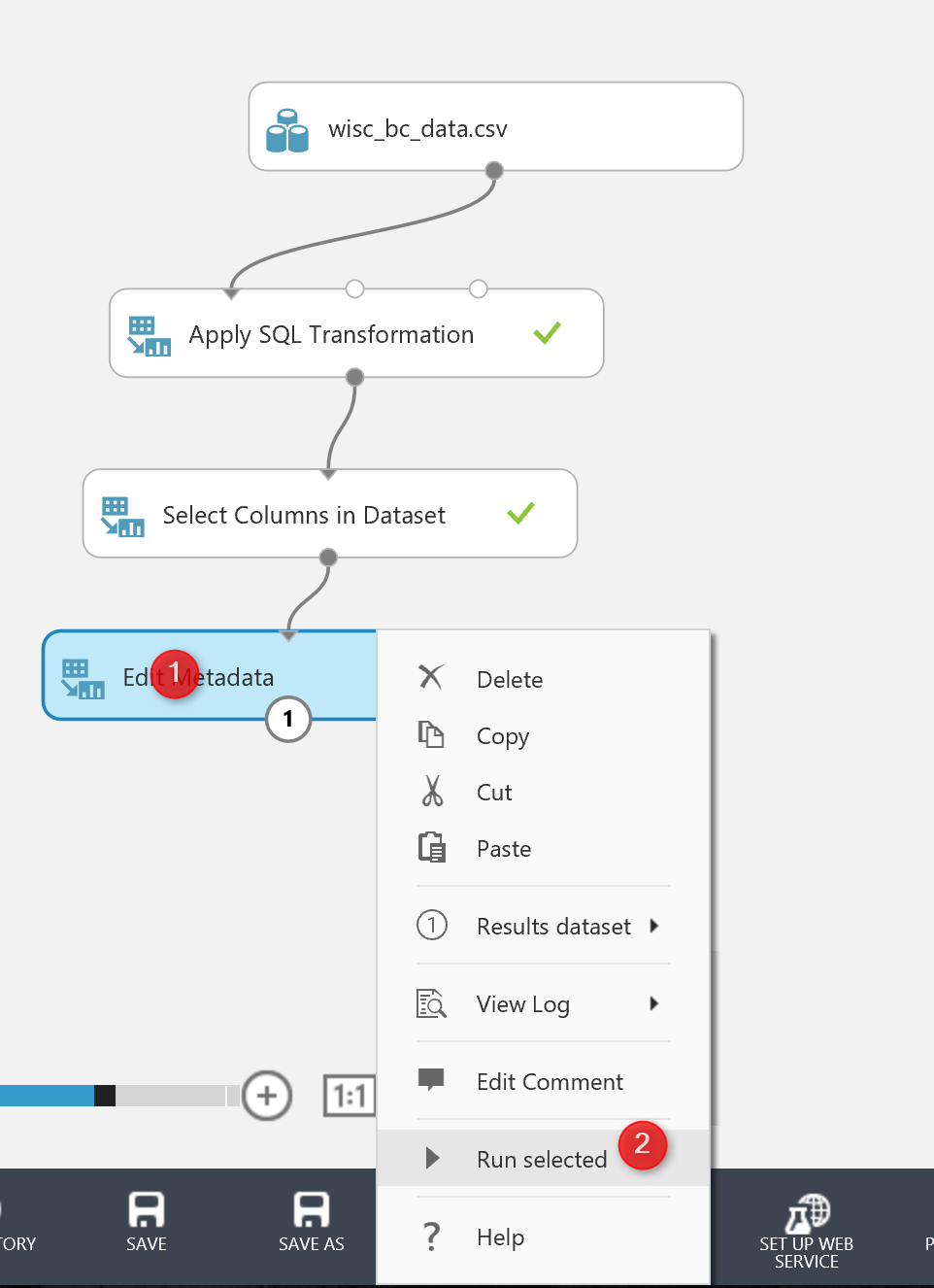
There is a possibility to run just one node at the time in Azure Ml to make experiment creation faster.
For instance, after adding the “Edit Metadata” I just right click on the node and I have selected the ” Run selected node”.
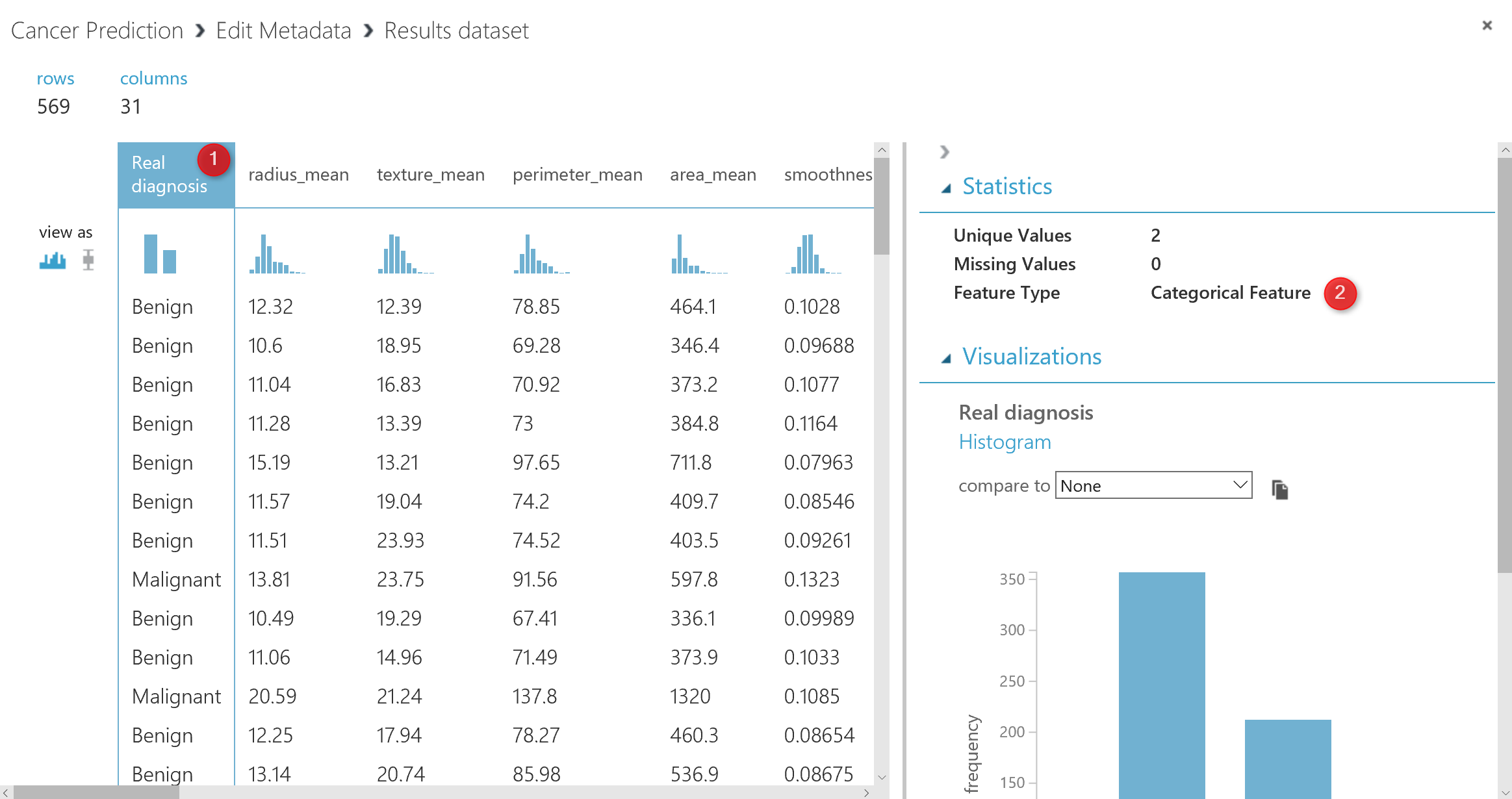
Now If I visualized the data at the node” Edit Meta Data” you will see that the diagnosis column has a ” categorical Feature” data type which good for doing the prediction.
there are still some steps for doing the data cleaning and feature election, that I will explain in the next posts.
to sum up, in this post, I have explain how to work with “SQL Transformation” Component, “Select specific columns” for remove a attributes. How to remove missing value using “Clean Missing Data” component. Also edit meta data to change the name and type of columns.
I next post I will explain how to normalize these data, how to find which attributes has more impacts on the “diagnosis ” columns prediction, also how to split data , train model, score morel, evaluate model.




Thanks a lot for this ML series!! This is really helping me!
Happy to Hear That!
Thank you so much. These posts really do help me.