

In the area of performance tuning a Power BI model many things has to be considered, most of them around consumption of the CPU and RAM. One of the most basic but important consideration is minimizing the usage of memory. By default all queries from Query Editor will be loaded into the memory of Power BI Model. In this post I’ll show you an example to disable the load for some queries, especially queries that used as intermediate transformation to produce the final query for the model. This is a very basic tip but very important when your model grows big. If you want to learn more about Power BI read the Power BI online book from Rookie to Rock Star.
Prerequisite
For running examples of this book you need to download the ZIP file here;
Load Mechanism for Power Query
By Default all queries in Power Query will be loaded into the Power BI model. This behavior might be a desired behavior if you are connecting to a proper star schema modeled data warehouse, because normally you don’t need to make many changes in the structure of queries. However this brings some issues if you are connected to a transactional data store, some files, web source, and many other non-star schema modeled data sources. Normally when you get data from a data source, you apply transformations for rows and columns, and merge queries or append them, and you might end up to have 5 tables out of 10 queries as final queries. By default when you close and apply your query editor window all queries will be loaded into the model no matter if you want to use them in your final model or not.
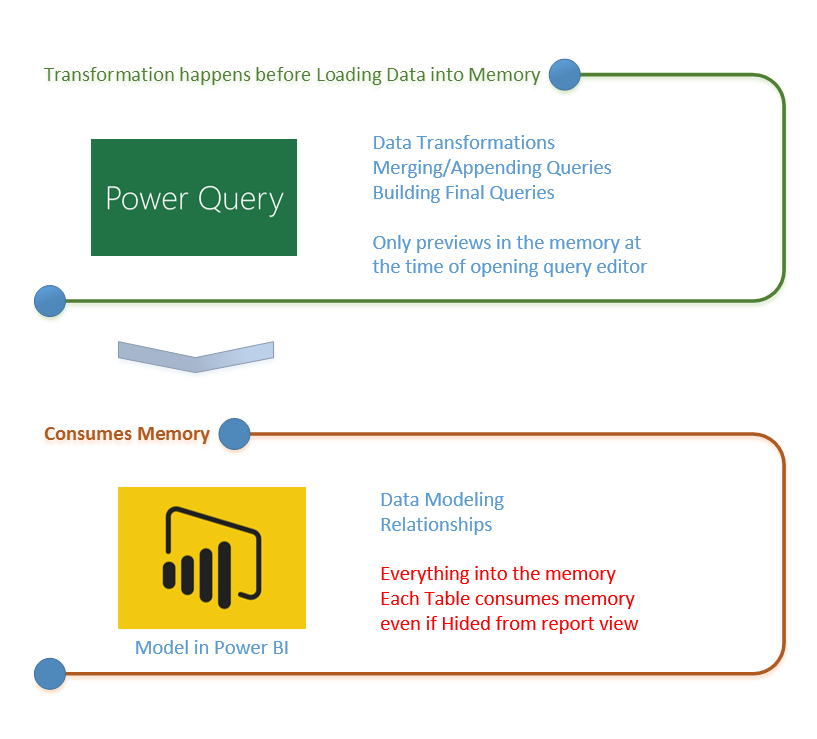
For every query that loads into model memory will be consumed. and Memory is our asset in the Model, less memory consumption leads to better performance in most of the cases. I have seen lots of models that people Hide the unwanted query from the model, This approach doesn’t help to the performance because hided query will still consume the memory. The best approach is to disable loading before closing query editor. Disabling Load doesn’t mean the query won’t be refreshed, it only means the query won’t be loaded into the memory. When you click on Refresh model in Power BI, or when a scheduled refresh happens even queries marked as Disable Load will be refreshed, but their data will be used as intermediate source for other queries instead of loading directly into the model. This is a very basic performance tuning tip, but very important when your Power BI model grows bigger and bigger. Let’s look at this through an example.
Example Scenario
In this example Scenario I want to get list of all files from a directory. There are two types of CSV files in the directory, some Students files, and some course files, both are CSV files, but different structured. Also there might be some other files in the directory, such as Word files or HTML files which I don’t want to process.

Aim is to load data rows of all students and courses as two separate tables into the model. Instead of fetching files from the folder twice, we use one query to fetch the files, and then use it as a reference for other queries. The referenced query itself doesn’t needs to be loaded into the model. Let’s build the solution and see how it works in action.
Build the Transformations
Get Data from Folder
Open a new Power BI file, and stat by Getting Data from Folder
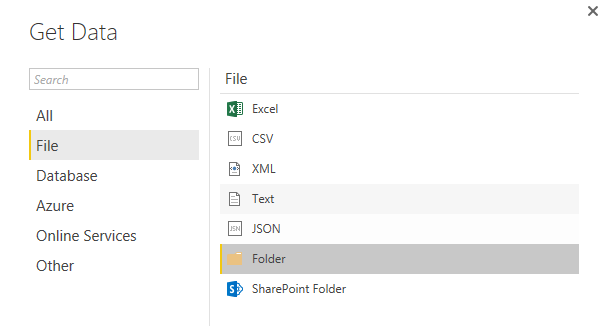
Enter the path of folder that contains all files (Files in this folder can be downloaded from ZIP file up in the prerequisite section of this post)

Click on Edit in the preview showed in the navigator window to open the folder content in Query Editor. As you see there are number of different files in the folder.
Filter the Extension to only .csv. Note that both Course and Student files are .CSV files which is what we need.
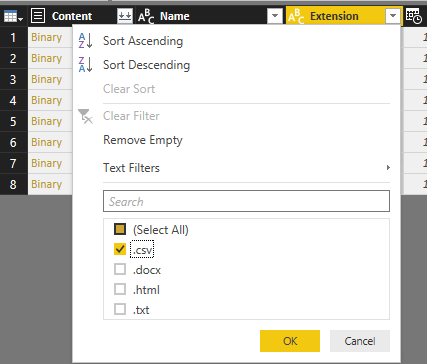
Now the subset includes Course files and Students files which are different in the structure. We have to apply transformations on each set individually. 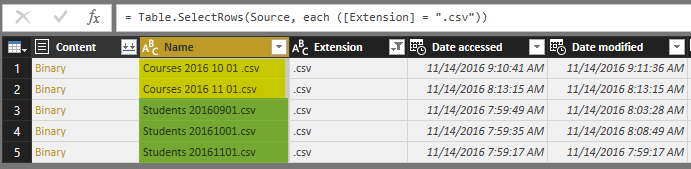
Students Query
Because I don’t want to repeat the process of getting all files from a folder, and I want to split the data into two data sets; one for Students and another one for Courses. I’ll generate a REFERENCE from the main query. Right click on the query (which called CSVs in my example), and select Reference.
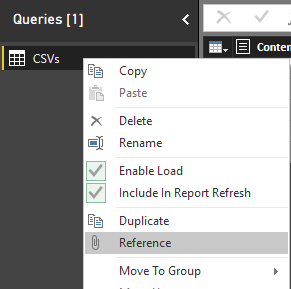
This will generate a new query named as CSVs (2). This new query is NOT A COPY of first query. This is only a reference from first query. which means if the first query changes, the source for this query will also change. Rename this new query to be Student. Filter the Name column to everything starting (or begins with) “Student”.
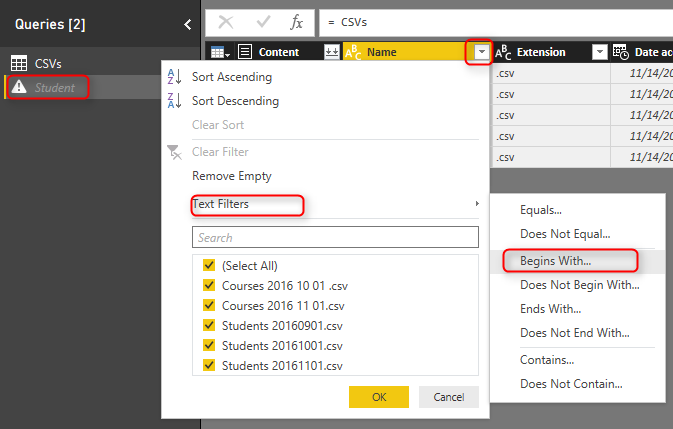
The reason that I don’t type in in the search box and use Text Filters specifically is that the search box will filter the data statistically based on values that exists in the current data set. If in the future new values (file names) comes in the folder this won’t consider that. However the Text Filter will apply on any data set because it will be filtered dynamically. (I’ll write a post later to explain that in details). In the Filter Rows window type in Student as filter for begins with.
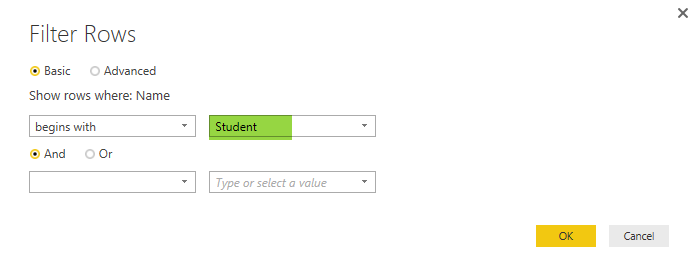
Now you will see only Students files.

Click on the Combine Binaries icon on the header of Content column to combine all CSV files into one.
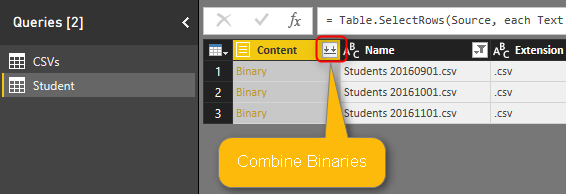
After combining binaries, Power Query will also import the CSV into the table and do automatic data type conversion. You can see all three steps in the Query Editor.
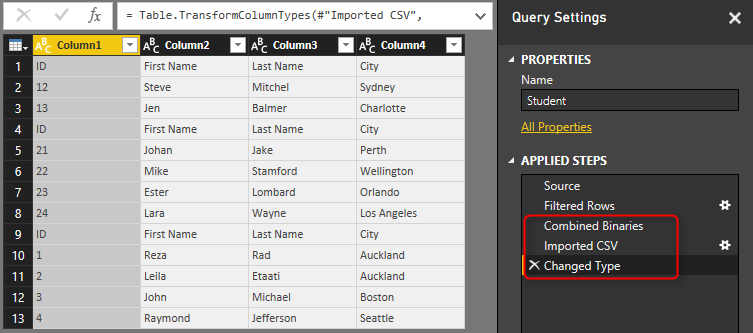
The data table needs couple of changes before be ready. First; set the column names. The first row has column names. so use the menu option of “Use First Row As Headers” to promote the first row to be column headers.
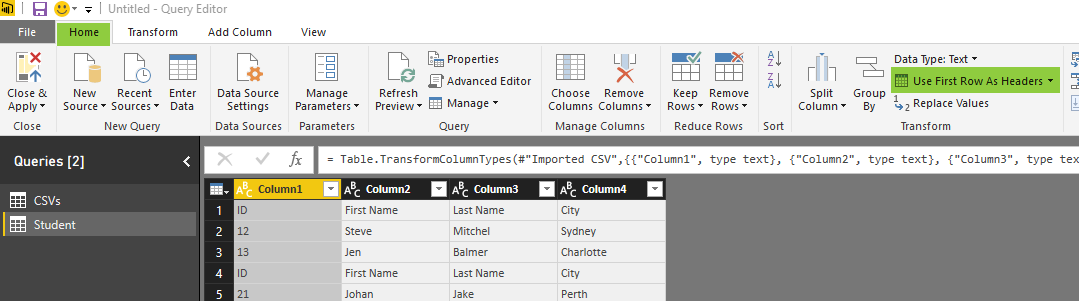
This simply brings column headers;
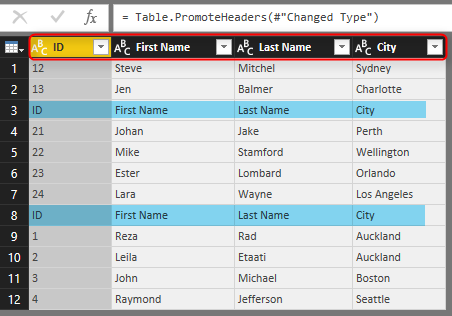
Also you need to remove all extra header rows from the combined data set. There are some rows with “ID,First Name, Last Name, and City” as their values which should be removed from the data set. You can simply remove them with a Text Filter of Does Not Equal to on the ID column. values should not be equal to “ID” because every row with “ID” in the first column’s value is a header row and should be removed.
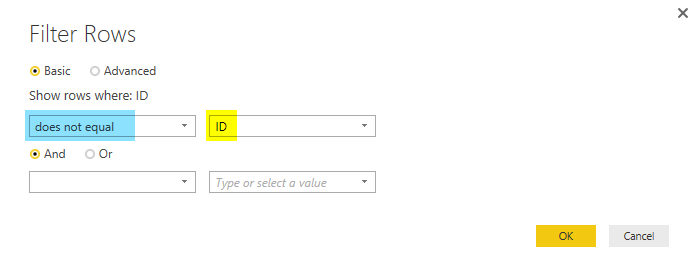
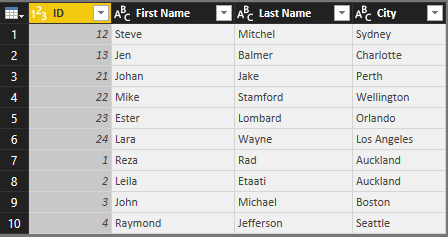
Now you have you cleaned data set for Students. Note that I have also applied a data type conversion for column ID to type whole number;
Courses Query
The other entity is Course which we need to create as a reference from the CSVs query. Create another reference from CSVs, and name it Course. 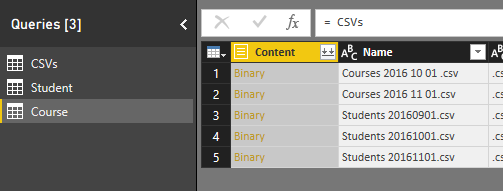
Create a Text Filter for Begins with on the Name Column with the value of: “Course”
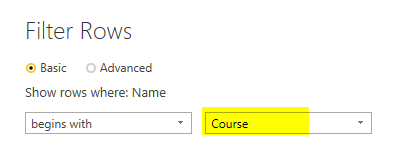
And the you’ll have only Course files. Combine Binaries on that.
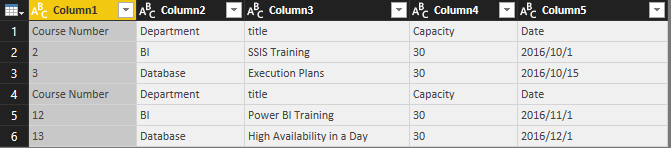
Same as Student query, apply transformations in this order;
- Promote headers with “Use First Row As Headers”
- Create a Text Filter on the Course Number Column that values does not equal to “Course Number”.
- Apply data type conversion on Course Number and Capacity to Whole Number and Date to Date.
Here is the final data set for course;

Default Behavior: Enable Load
Now to see the problem, without any changes in the default load behavior, Close the Query Editor and Apply changes.
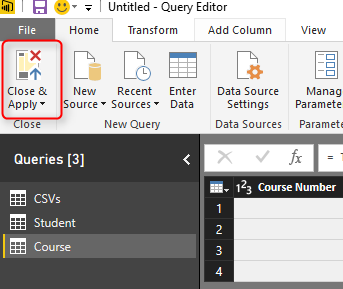
You will see that after the refresh, three queries loads in the model; Student, Course, and CSVs.

Student and Course are expected tables in the model. However CSVs is not useful. we already fetched everything we wanted from the query, and this is used as an intermediate query for loading Student and Course. Having CSVs as a separate table in our model has two problems;

- one extra table; confusion for users
- extra memory consumption
The main issue is the memory consumption for this extra table. and normally memory consumption will reduce the performance and brings heavier load to the model. In this example CSVs table only has few rows. but this is just a sample data, in real world examples you might have intermediate tables with millions of rows. You need to remove every unused table from the Power BI model to enhance the memory consumption.
What about Hiding from Report?
The first issue “Confusion for users” can be solved by hiding the table from report view. You can do that in Relationship tab of the model, right click on the CSVs table, and click on Hide from report view. This method HIDEs the table from report view. However the table still exists, and it consumes memory! It is just hidden. Hiding a table from report view is good for tables that you need for the modeling. For example a relationship table (that creates many to many relationship) should be kept in the model but be hidden. because it creates the relationship, but it is not useful for the report viewer. Any other tables that is not used for relationship and is not used for reporting should be removed before loading into the model.
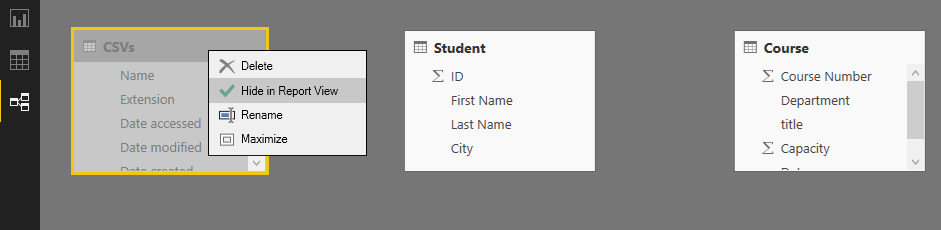
Disable Load to Save Memory
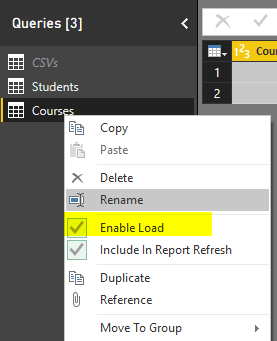
Go back to Query Editor, and right click on CSVs query. You will see that by default every query is checked as Enable Load.

Click on the Enable Load to disable it. You will see a message saying that any visuals attached to this query will not work after this change. Which is totally fine, because this query is not used (and won’t be) for any visualization. The message is: “Disabling load will remove the table from the report, and any visuals that use its columns will be broken.”
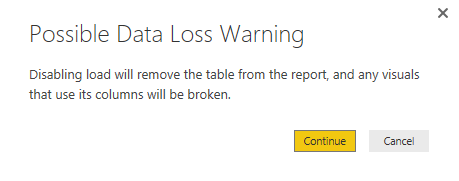
Click on Continue, and you will see the load is disabled for the query now. the query name will be also in Italic font illustrating that it won’t be loaded into the model. Note that query will be refreshed and if new files comes to the directory it will pass it on to Course and Student queries. It just won’t be loaded into the model itself.
You can also see in the View tab of Query Editor, on the Query Dependencies that this query is the source of the other two queries. and in that view it also shows which query is load disabled.
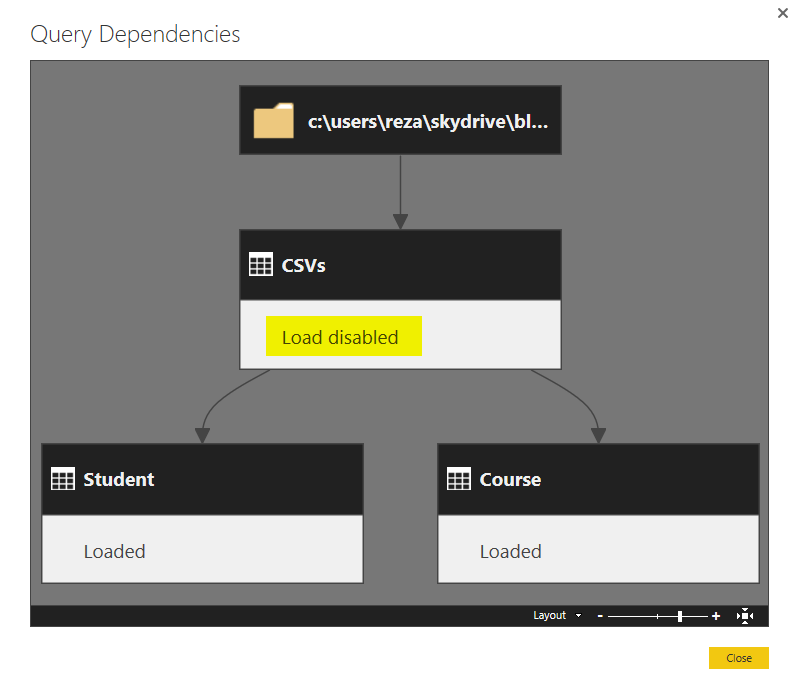
Now close and apply the Query Editor. This time you see that CSVs query won’t be loaded into the model. Your relationship tab and the report tab only contains two tables; Course, and Student.
Summary
In summary you’ve seen how an easy tip can save the memory and enhance the performance of Power BI model. Always remember that Query Editor is your ETL (Extract, Transform, Load) engine. It will apply all transformations before loading the data into the model, but once it finished the transformation all queries will be loaded into the model and they take memory. By default all queries are Enabled to Load into the model. Simply change that for queries that is not required in the model.
Video




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Hi Reza,
With Direct Query, when you disable load, you get a warning: Possible Data Loss Warning and it says it will remove the table from the report (which it then does). So this excellent tip is for the Import model only, I suspect.
Hi Angus.
Any table/query that you disable its load, will NOT be loaded into Power BI. Table will be removed from the report. This is for intermediate tables that you don’t need them in report, and they consume extra memory
Cheers
Reza
Nice and super tips thanks for sharing
Hi Reeza,
I am inheriting a rather large, cumbersome, but highly important file. What is the best way to tell which tables/queries this could be applied to?
Thanks!
Hi Vic
Any tables that you do not need in the reporting can be a good candidate for this option. you should only Enable Load tables that you really want to use them in the reporting. no matter how big they are.
Cheers
Reza
I wish there is a way where in I have 2 queries which just give me data for some older periods and that data just stay in Power BI and doesn’t refresh every day with my scheduled refresh.
My use case is that I have data for lets say 3 years – 2016, 2017 and 2018.
I will have 3 queries – 1 for each of the years. Then, I want that 2016 and 2017 do not refresh every day, it just stays in my Power BI data model and once I refresh 2018 query, we append all the data together (using append queries).
Any such thing possible?
Hi Vicky
It is possible that way, but there is an easier way for it; Incremental Refresh.
You can choose the period you want the data to be refreshed, and the period you want to keep the historical data. the only thing is that this is a premium function at the moment.
Cheers
Reza
This is very useful!!! Thanks for sharing!
Hi Raza,
To get the full performance of Power Pivot, what should I consider to buy or upgrade a PC.
RAM, CPU clock or number of Core.
Please suggest.
Thank you,
Hi.
Most of the performance issues are because of the data model. I’d say, first, you need to improve the model.
If still slow, after good modeling, then upgrade of the system helps. you would need a system with good CPU and Memory. CPU and Memory are both important. CPU for calculating measures, and Memory for the in-memory storage.
Cheers
Reza
Hi Reza, great article for a PBI beginner, thank you!
Follow up question, I’m currently running PBI Version 2.70.5494.562 64-bit (June 2019). I’ve loaded a Lead table and a Contact table into PBI, combined them into a “Peoples” table, and then disabled load for the Lead + Contact Tables. I need to QC the results, and would like to Enable Load again on the Lead + Contact table. Upon doing so via Power Query Editor, I get the “Possible Data Loss” Warning, even when trying to ENABLE the load. Is it possible that I need to “Enable Load” in another location? Am I missing a step? Is this a bug?
Any feedback would be much appreciated!
Tyler
Hi Tyler
The “Possible data loss” is just a warning to let you know that if you disable load of a table, then if you used it in a visualization, you might lose that visualization’s data.
Cheers
Reza
This may solve my issue. I have a query with facts/dimensions which I need to break up into a star schema. I created dependencies but I couldn’t delete the original table. I’ll check out the load switch.
I have a huge table and have two reference table created with filtering on both part. If I disable load to my reference table and enable load to main table. will any changes coming to main table will be passed to reference tables??
The referencing of one table from another doesn’t necessarily means that first table will be cached so the result of the second table loads faster.
If you want a behavior like that, I suggest looking into Computed Entity in dataflow which does that.
Very good and detailed tip and explanation. Appreciate your great effort Reza.