
Have you ever thought does your Power Query Transformations happens in the data source side (server side), or on the local memory (client side)? When you use a relational data source, query can be run on the data source, but it depends on transformations. Some transformations can be translated to query language of the data source, some not. as an example; recently (I believe from last few releases) Power BI Desktop added a feature called Merge Columns. Merge Columns concatenate columns to each other to either create a new column, or replace them with the new concatenated result. Previously you could do the concatenation with adding concatenation simply with & character, what you’ve done was adding a new custom column, and writing M expression to concatenate columns. Now with the new Merge Column this are much easier, you select columns and apply Merge Columns. This easiness does come with a price, a high price I’d say, price of reducing the performance of Power Query and as a result Power BI! Merge Columns doesn’t support query folding and it means it will affect performance badly. In this post I’ll show you how this cause the performance issue, and how it can be solved. Note that Merge Columns is an example here ,this situation might happens with some other transformations as well. If you like to learn more about Power BI; read the Power BI online book from Rookie to Rock Star.
Query Folding
I can’t start talking about the issue without explaining what Query Folding is, so let’s start with that. Query Folding means translating Power Query (M) transformations into native query language of the data source (for example T-SQL). In other words; when you run Power Query script on top of a SQL Server database, query folding will translate the M script into T-SQL statements, and fetch the final results.
Here is an example of M Script:
let
Source = Sql.Databases("."),
AdventureWorks2012 = Source{[Name="AdventureWorks2012"]}[Data],
Sales_SalesOrderHeader = AdventureWorks2012{[Schema="Sales",Item="SalesOrderHeader"]}[Data],
#"Added Conditional Column" = Table.AddColumn(Sales_SalesOrderHeader, "Custom", each if [SubTotal] >= 100 then "0" else "1" )
in
#"Added Conditional Column"
And here is the folded version of that translated to native T-SQL query:
select [_].[SalesOrderID] as [SalesOrderID],
[_].[RevisionNumber] as [RevisionNumber],
[_].[OrderDate] as [OrderDate],
[_].[DueDate] as [DueDate],
[_].[ShipDate] as [ShipDate],
[_].[Status] as [Status],
[_].[OnlineOrderFlag] as [OnlineOrderFlag],
[_].[SalesOrderNumber] as [SalesOrderNumber],
[_].[PurchaseOrderNumber] as [PurchaseOrderNumber],
[_].[AccountNumber] as [AccountNumber],
[_].[CustomerID] as [CustomerID],
[_].[SalesPersonID] as [SalesPersonID],
[_].[TerritoryID] as [TerritoryID],
[_].[BillToAddressID] as [BillToAddressID],
[_].[ShipToAddressID] as [ShipToAddressID],
[_].[ShipMethodID] as [ShipMethodID],
[_].[CreditCardID] as [CreditCardID],
[_].[CreditCardApprovalCode] as [CreditCardApprovalCode],
[_].[CurrencyRateID] as [CurrencyRateID],
[_].[SubTotal] as [SubTotal],
[_].[TaxAmt] as [TaxAmt],
[_].[Freight] as [Freight],
[_].[TotalDue] as [TotalDue],
[_].[Comment] as [Comment],
[_].[rowguid] as [rowguid],
[_].[ModifiedDate] as [ModifiedDate],
case
when [_].[SubTotal] >= 100
then '0'
else '1'
end as [Custom]
from
(
select [$Table].[SalesOrderID] as [SalesOrderID],
[$Table].[RevisionNumber] as [RevisionNumber],
[$Table].[OrderDate] as [OrderDate],
[$Table].[DueDate] as [DueDate],
[$Table].[ShipDate] as [ShipDate],
[$Table].[Status] as [Status],
[$Table].[OnlineOrderFlag] as [OnlineOrderFlag],
[$Table].[SalesOrderNumber] as [SalesOrderNumber],
[$Table].[PurchaseOrderNumber] as [PurchaseOrderNumber],
[$Table].[AccountNumber] as [AccountNumber],
[$Table].[CustomerID] as [CustomerID],
[$Table].[SalesPersonID] as [SalesPersonID],
[$Table].[TerritoryID] as [TerritoryID],
[$Table].[BillToAddressID] as [BillToAddressID],
[$Table].[ShipToAddressID] as [ShipToAddressID],
[$Table].[ShipMethodID] as [ShipMethodID],
[$Table].[CreditCardID] as [CreditCardID],
[$Table].[CreditCardApprovalCode] as [CreditCardApprovalCode],
[$Table].[CurrencyRateID] as [CurrencyRateID],
[$Table].[SubTotal] as [SubTotal],
[$Table].[TaxAmt] as [TaxAmt],
[$Table].[Freight] as [Freight],
[$Table].[TotalDue] as [TotalDue],
[$Table].[Comment] as [Comment],
convert(nvarchar(max), [$Table].[rowguid]) as [rowguid],
[$Table].[ModifiedDate] as [ModifiedDate]
from [Sales].[SalesOrderHeader] as [$Table]
) as [_]
You can see as an example how the conditional column script in M translated to Case statement in T-SQL.
Is Query Folding Good or Bad?
Good obviously. Why? because performance is much higher to run transformations on billions of records in the data source, rather than bringing millions of records into cache and applying some transformations on it.
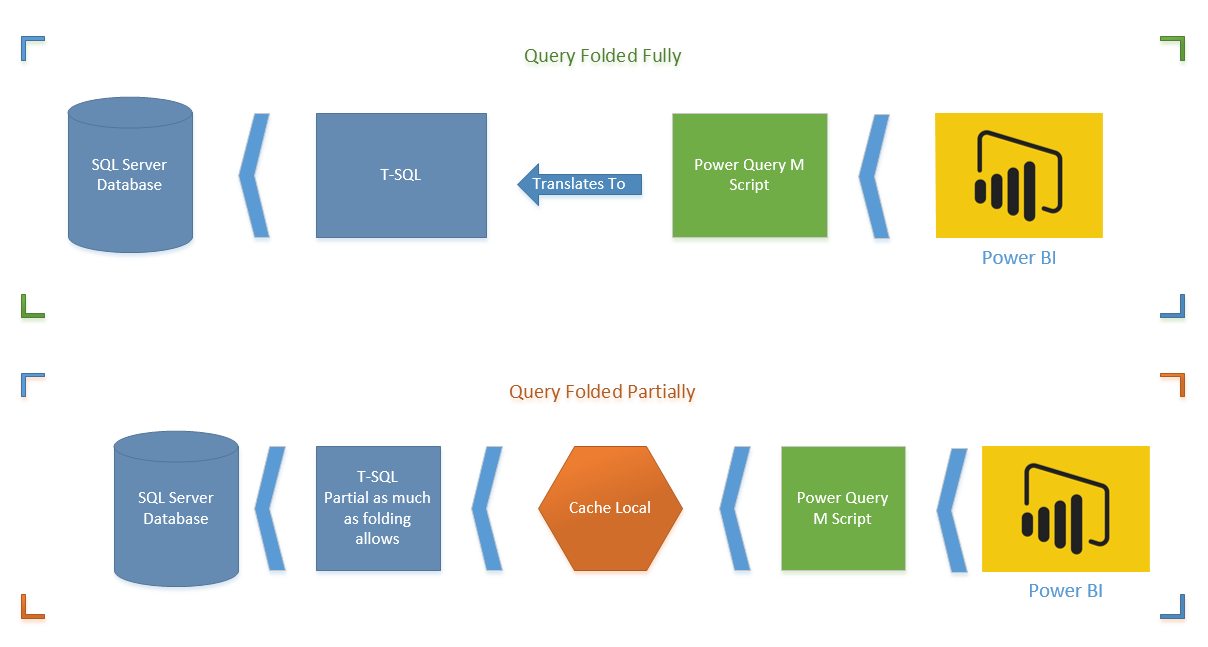
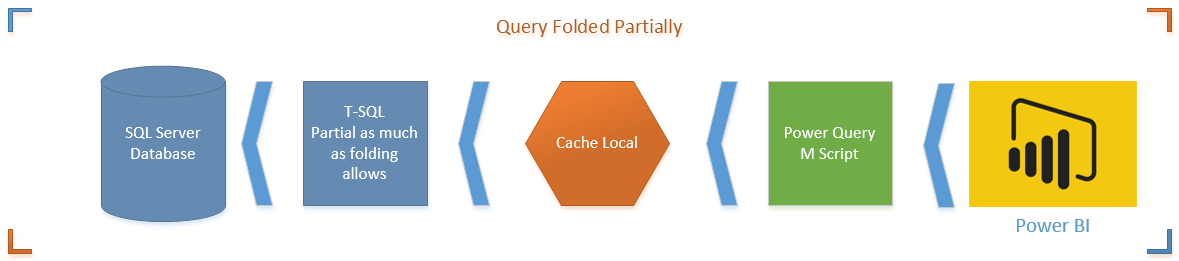
The first diagram shows a M script fully folded (translated to T-SQL). This is the best situation. Server side operation apply all transformations on the data set and returns only desired result set.
The second diagram shows Query Folding partially supported (only up to specific step). In this case T-SQL brings the data before that step. and data will be loaded in the local cache, and rest of transformations happens on M engine side. You have to avoid this option as much as possible.
Can I see the Native Query?
The question that might comes into your mind right now is that; Can I see the Native Query that M script translates to it? The answer is Yes. If Query Folding is supported on a step, you can right click on that step and click on View Native Query.

So Why Not Query Folding?
Query Folding is enabled by default. However in some cases it is not supported. For example if you are doing some transformations on a SQL Server table in Power Query and then join it with a web query query folding stops from the time you bring the external data source. That means transformations will happen on the data of SQL Server table. then before joining to web query it will be fetched into cache and then rest of steps happens by M engine. You would need to bring data from different data sources in Power BI, and this is the ability that Power Query gives to you. So sometimes you have to step beyond query folding, and there might be no better way of doing that.
There are also some Transformations in Power Query that Query Folding doesn’t support them. Example? Merge Columns! Fortunately there are workarounds for this situation. Let’s dig into this more in details.
Example: Merge Columns
Merge Columns concatenates columns to each other in the order of selection of columns. You can also specify the delimiter character(s). So simply if you want to create a full name from first name and last name, you can select them in right order, and from either Transform tab, or Add Column tab choose Merge Columns. Let’s see this through an example;
Prerequisite for running the example
You need to have AdvanetureWorksDW database installed on SQL Server. or alternatively you can use any table in SQL Server that has two string columns which can be concatenated.
Merge Column Transformation
Create a new Power BI file in Power BI Desktop, and Get Data from SQL Server with Import Data Mode. Get Data from DimCustomer table only, and click on Edit. When in Query Editor. Select First Name, Middle Name, and Last Name in the correct order, and then from Add Column Select Merge Columns.
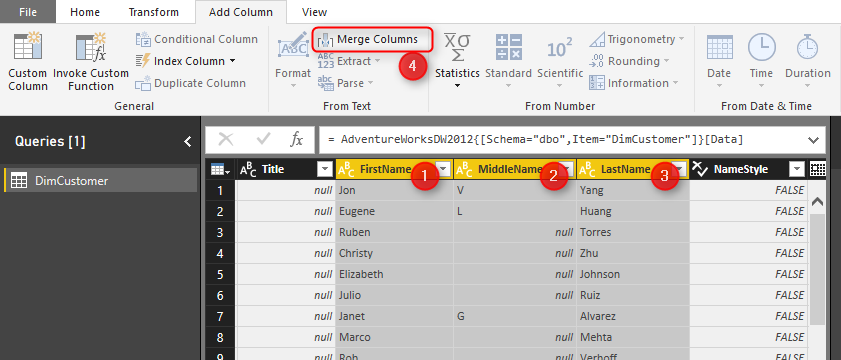
In the Merge Columns Specify the Separator to be space, and name the new column to be Full Name.
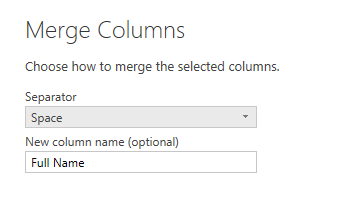
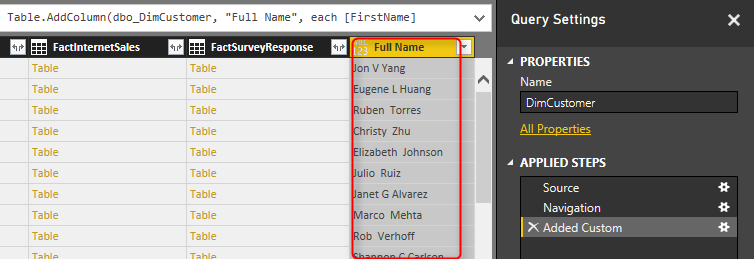
You will see the new column generates simply and adds to the end of all columns. You also may notice that Merge Columns uses Text.Combine Power Query function to concatenate columns to each other.
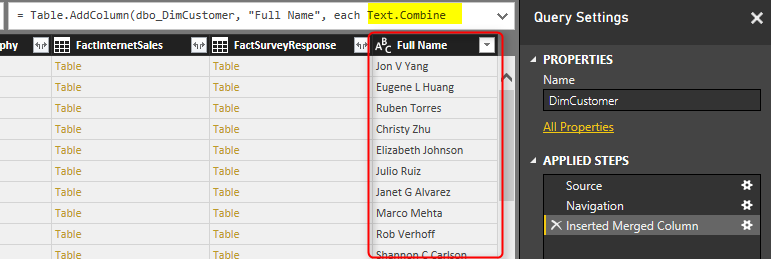
Now to see the problem with Query Folding, right click on Inserted Merge Column step in Applied Steps section. You will see that View Native Query is disabled.
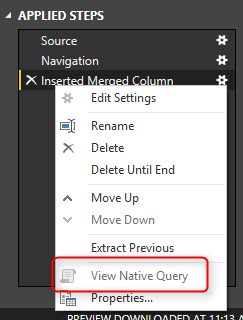
Rule of thumb is that: When View Native Query is not enabled, that step won’t be folded! that means the data will be loaded into cache up the step before this step. and then rest of the operation will happen locally. To understand how it works, right click on the step before which was Navigation. You will see the View Native Query. Click on that, and you can see the T-SQL query for that which is as below;
select [$Table].[CustomerKey] as [CustomerKey],
[$Table].[GeographyKey] as [GeographyKey],
[$Table].[CustomerAlternateKey] as [CustomerAlternateKey],
[$Table].[Title] as [Title],
[$Table].[FirstName] as [FirstName],
[$Table].[MiddleName] as [MiddleName],
[$Table].[LastName] as [LastName],
[$Table].[NameStyle] as [NameStyle],
[$Table].[BirthDate] as [BirthDate],
[$Table].[MaritalStatus] as [MaritalStatus],
[$Table].[Suffix] as [Suffix],
[$Table].[Gender] as [Gender],
[$Table].[EmailAddress] as [EmailAddress],
[$Table].[YearlyIncome] as [YearlyIncome],
[$Table].[TotalChildren] as [TotalChildren],
[$Table].[NumberChildrenAtHome] as [NumberChildrenAtHome],
[$Table].[EnglishEducation] as [EnglishEducation],
[$Table].[SpanishEducation] as [SpanishEducation],
[$Table].[FrenchEducation] as [FrenchEducation],
[$Table].[EnglishOccupation] as [EnglishOccupation],
[$Table].[SpanishOccupation] as [SpanishOccupation],
[$Table].[FrenchOccupation] as [FrenchOccupation],
[$Table].[HouseOwnerFlag] as [HouseOwnerFlag],
[$Table].[NumberCarsOwned] as [NumberCarsOwned],
[$Table].[AddressLine1] as [AddressLine1],
[$Table].[AddressLine2] as [AddressLine2],
[$Table].[Phone] as [Phone],
[$Table].[DateFirstPurchase] as [DateFirstPurchase],
[$Table].[CommuteDistance] as [CommuteDistance],
[$Table].[FullName] as [FullName]
from [dbo].[DimCustomer] as [$Table]
You can see that this is simple query from DimCustomer Table. What will happen here in this scenario is that Power Query cannot translate Text.Combine to T-SQL Query. So data up to step before will be loaded into the cache. It means the query for step before (which is above query) will run on the database server, the result will come to the cache, and then Text.Combine will happen on the local memory in cache. Here is a diagram of how it works;
In this example the data set is so small, but if data set be big, then not folding cause performance issues. It is taking much longer to load the whole data set into cache and then apply transformations, rather than doing transformations in the data source, and just loading the result into Power BI.
Solution: Simple Concatenate with Add Column
Now remove the step for Inserted Merged Column, and go to Add Column Tab, and select Custom Column

In the Add Custom Column write below expression to generate Full Name;
= [FirstName] & " " & (if [MiddleName]=null then "" else [MiddleName]) & " " &[LastName]

This expression used the concatenation character which is &. and also checked if Middle Name is null or not. Result in Power Query side is the same, and it generates the Full Name column like the previous example;
However it is different for Query Folding. Right Click on the Added Custom step, and you will see the Native Query this time.
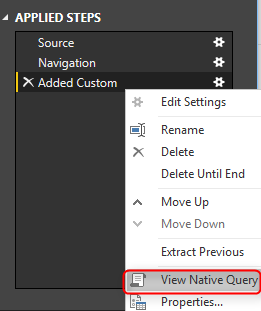
Query is simply the same with a new concatenated column added.
select [_].[CustomerKey] as [CustomerKey],
[_].[GeographyKey] as [GeographyKey],
[_].[CustomerAlternateKey] as [CustomerAlternateKey],
[_].[Title] as [Title],
[_].[FirstName] as [FirstName],
[_].[MiddleName] as [MiddleName],
[_].[LastName] as [LastName],
[_].[NameStyle] as [NameStyle],
[_].[BirthDate] as [BirthDate],
[_].[MaritalStatus] as [MaritalStatus],
[_].[Suffix] as [Suffix],
[_].[Gender] as [Gender],
[_].[EmailAddress] as [EmailAddress],
[_].[YearlyIncome] as [YearlyIncome],
[_].[TotalChildren] as [TotalChildren],
[_].[NumberChildrenAtHome] as [NumberChildrenAtHome],
[_].[EnglishEducation] as [EnglishEducation],
[_].[SpanishEducation] as [SpanishEducation],
[_].[FrenchEducation] as [FrenchEducation],
[_].[EnglishOccupation] as [EnglishOccupation],
[_].[SpanishOccupation] as [SpanishOccupation],
[_].[FrenchOccupation] as [FrenchOccupation],
[_].[HouseOwnerFlag] as [HouseOwnerFlag],
[_].[NumberCarsOwned] as [NumberCarsOwned],
[_].[AddressLine1] as [AddressLine1],
[_].[AddressLine2] as [AddressLine2],
[_].[Phone] as [Phone],
[_].[DateFirstPurchase] as [DateFirstPurchase],
[_].[CommuteDistance] as [CommuteDistance],
[_].[FullName] as [FullName],
((([_].[FirstName] + ' ') + (case
when [_].[MiddleName] is null
then ''
else [_].[MiddleName]
end)) + ' ') + [_].[LastName] as [Full Name]
from [dbo].[DimCustomer] as [_]
This time there won’t be an intermediate cache. transformation happens in the data source with the T-SQL query, and result will be loaded into Power BI.
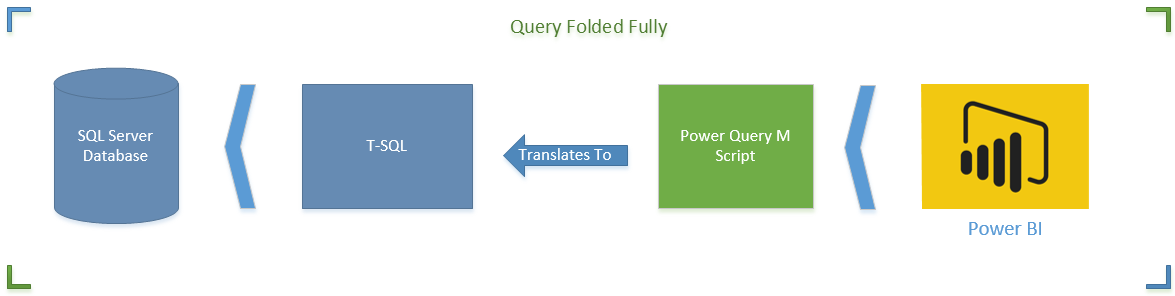
How Do I know Which Transformations Folds?
Great Question. It is important to understand which step/transformation folds and which doesn’t. To understand that simply right click on every step and see if the View Native Query is enabled or not. If it is enabled Query Folding is supported for that step, otherwise not. Also Note that Query Folding is not supported for data sources such as web query, or CSV or things like that. Query Folding at the moment is only supported for data stores that supports a native query language. For Web, Folder, CSV… there is no native query language, so you don’t need to be worry about Query Folding.
*Important Note: At the time of writing this post Merge Columns doesn’t support Query Folding. I have reported this to Power Query Team, and they are working on it, to solve the issue. The Merge Columns is very likely to support query folding very soon as the result of bug fix. However there are always some other transformations that doesn’t support query folding. This post is written to give you an understanding what kind of issue might happen, and how to resolve it.
My advise to you as a performance best practice is that when working with a relational data source (such as SQL Server). always check the query folding. Sometimes it is not supported, so use another approach for the transformation. Don’t fall into the black hole of not folding, otherwise your query might take ages to run.




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Hi Reza,
Great article on Query Folding. In a scenario that I use SQL Server as a data source with the Import option and my Power Query transformation doesn’t support Query Folding, the performance is impacted only during data import and data refresh, right?
Hi Cristhian,
Thanks for your kind words.
It will impact your development time and also the data refresh. Development time because query results first loads into your local cache and then other steps applies on top of it. and at the Refresh time as well as you mentioned. It won’t be like measure that affect performance with each slicer or filter selection, however because it consumes some more memory in overall you will see some performance decrease with large data sets.
Excellent explanation!
I have a report that contains a parameter which updates a SQL where clause containing a filter on a business key.
Once the parameter is set, the report works very well, with the underlying SQL returning results in less than a second.
It takes a long time to evaluate when the parameter is changed, ~ 2 minutes. Once the evaluation is done, the report returns its results with the new parameter quickly.
Is there an approach that makes the evaluation step either go away and/or quicker
Hi Brent
You cannot turn off the evaluation at the moment, however, there are a few things (In the Power BI Desktop -> Options and Settings -> Options, that help, such as:
Turning off the Automatically detecting relationship
Turning off the Auto Time Intelligence
CHeers
Reza