

I have previously written about What dataflow is and scenarios of using it. I also wrote an article about Computed Entity and the important role of that for performance and data lineage. However, a Computed entity is a premium-only feature. There are sometimes that you don’t really need premium functions of Power BI, and only the need to use a computed entity might be restrictive then. You want to reference another entity, and then you need a Computed entity as an example. In this article, I show you some workarounds that you can use to get the work done, without the need for a Computed entity, and even use it with normal Power BI Pro accounts. If you want to learn more about Power BI, read Power BI book from Rookie to Rock Star.
Prerequisite
If you are new to Dataflows, I recommend reading these articles beforehand;
Part 1: What are the Use Cases of Dataflow for You in Power BI?
Part 2: Getting Starting with Dataflow in Power BI
Part 3: What is the Common Data Model and Why Should I Care?
Part 4: Linked Entity and Computed Entity; Part 4 of Dataflows in Power BI
Problem Definition
A computed entity will be generated whenever you create a reference from another query. In most of the cases, you create a reference from other queries before combining them together, such as Append or Merge. However, there are many other scenarios that you might want to reference other queries. If you like to learn more about what the reference is, read my article here about the difference between the reference and duplicate in Power Query.
As an example of a scenario that you end up with using Computed Entity, Here is an example:
When Computed Entity is not needed
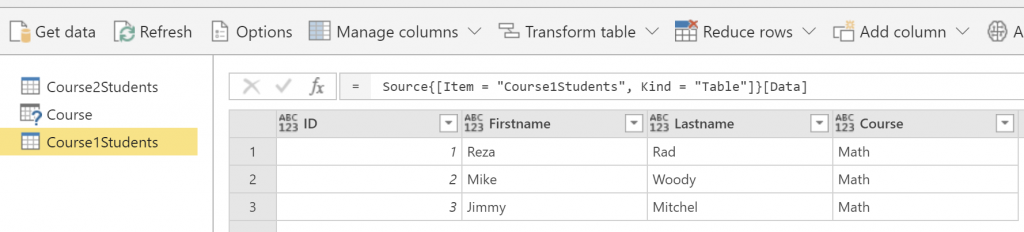
Imagine that we have two tables, and we want to combine them using the Append option. Our tables are as below;
Course1Students
Course2Students
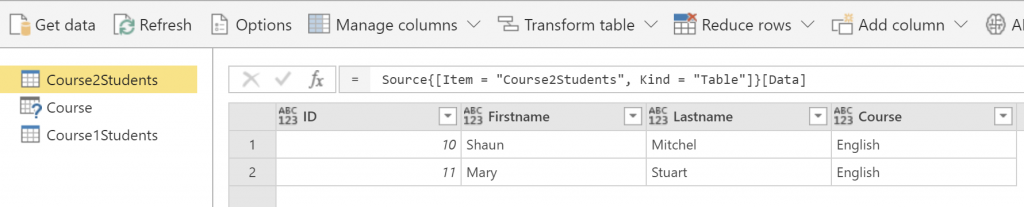
Now, let’s say you want to combine rows of these two tables together in one table called Course Students. You can do this with Append action (I previously explained what is Append and the difference of that vs. Merge), You can start with one table, then using Combine, and Append Queries, then select the second table;
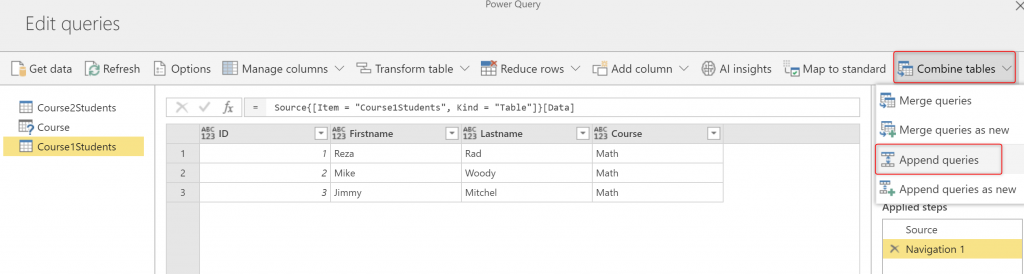
This method works fine. Now your Course1Students would be a table including all rows from both tables;
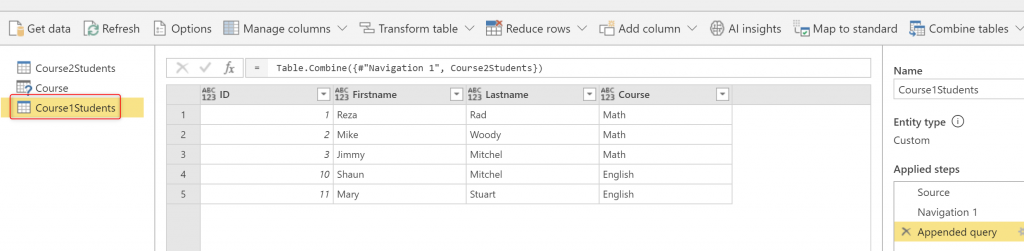
When Computed Entity might be needed
The above scenario, however, is not the case all the time. Sometimes, you do need to keep the original queries, and also create a new query which is the result of Append. If you want to do that, you can do it either using Append Queries as New;
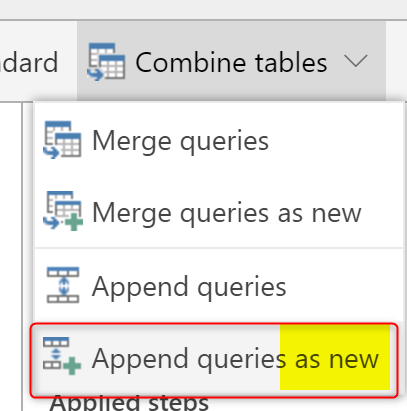
or creating a Reference from a query, and then doing append from there.
Any of the actions above will cause the creation of a Computed Entity;
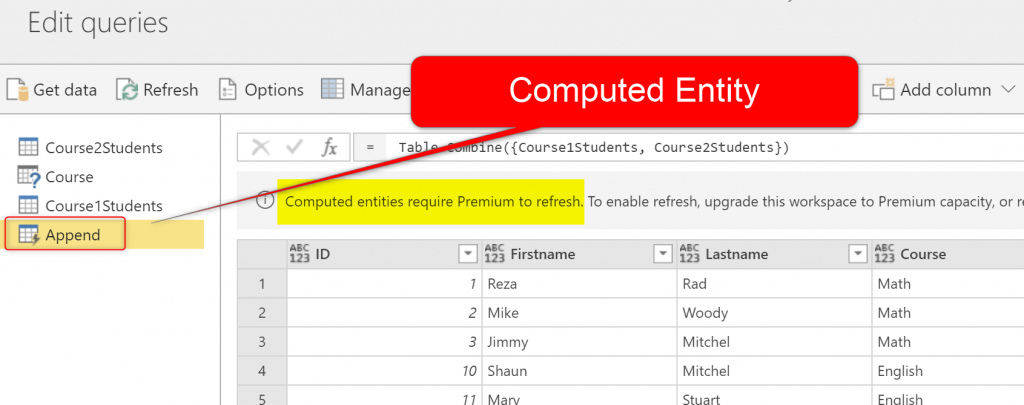
As you can see, the little lightning icon beside the new entity shows that this is a Computed Entity. And computed entity requires Premium Power BI capacity. To learn more about Computed Entity, read this article.
Sometimes, if you don’t really need to use the premium capacity (for example, the size of data is not large, and can be done easily without the need for it), you can implement one of the workarounds below to have this ability even without the need for the Computed entity.
Important Read before Reading the Workaround
Please note that I am not saying you should avoid creating a Computed Entity. I am saying that if you don’t really need a premium capacity and your need to that is only because you need to create a computed entity for your solution, and your data volume is not huge that actually requires a dedicated capacity to process it, then you can avoid it with some workarounds.
If any of the criteria above is not valid for your dataflow scenario, then I strongly recommend the usage of a Computed Entity, as it will help a lot with the performance of your data transformation implementation.
Workaround: Avoid the Computed Entity If You Don’t Need It
A computed entity is great for performance, especially because it stores the data as a middle layer in Azure Data Lake store, and continue the rest of the process from there. However, you might not need that. In that case, you can use any of the approaches below. Please note that there is a caution for each of the approaches mentioned, Make sure to read them carefully to know the side-effect of the action you are implementing.
Use Append or Merge, but without As New Option
You have seen already in the example above, If you use the Append Queries instead of Append Queries as New, then you won’t have a Computed Entity at all. It is only if you use the Append Queries as New or Merge Queries as New that you end up with the creation of a Computed Entity. So Avoid these two options if you can.
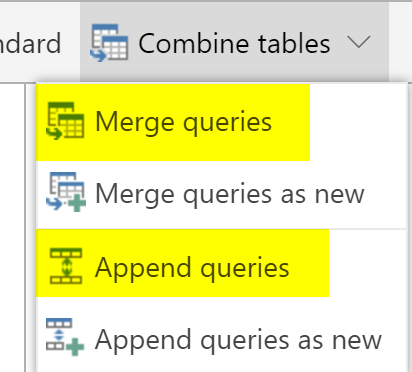
Caution: Using the Append or Merge Queries without As New option, will cause the current entity transformation to the result of the Merge or Append operation. If you don’t want to transform the existing entity, and want to keep that as is, you will need to use the As New options.
Important note about using this option is that if you don’t set the source entities to disable load, this will be still considered as a Computed Entity. So the next action below is needed to do this workaround. If you don’t disable load for the original source entities, you will get this message:

Set the Source Entities to Disable Load
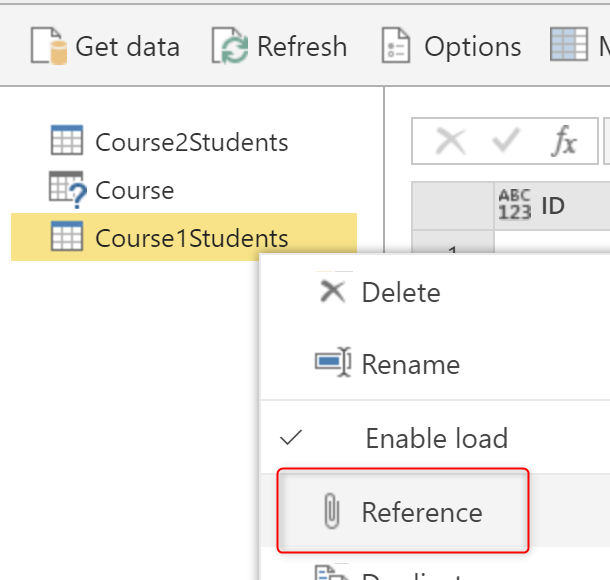
It is not always an option to use Merge Queries or Append Queries without the As New option. So you may end up using it as mentioned earlier in this article. In those cases, If you don’t need the original entity anymore, you can uncheck the enable load for it. This is possible with right-click on the original table and uncheck the Enable Load option. Here is a computed Entity Created by the Append Queries as New option already;
Now, you can right-click on Course1Students, and uncheck the Enable Load for it, and also do the same for Course2Students the same;
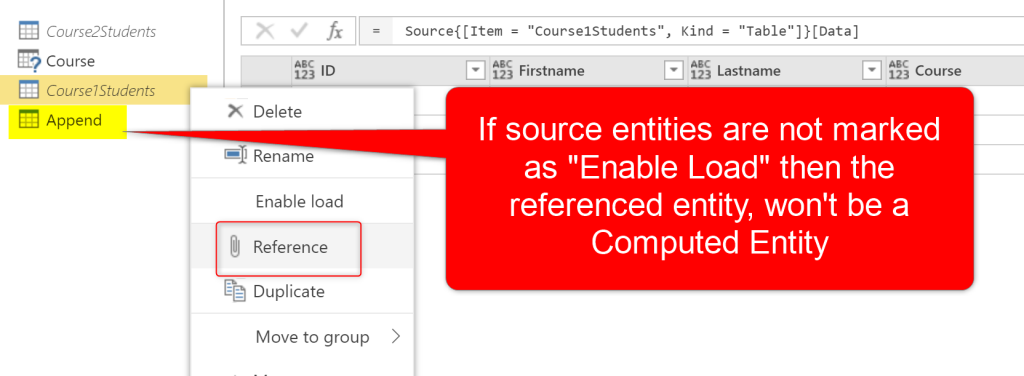
The same process is valid when you create a Reference from a query. You can then uncheck the Enable Load option from the source query, and you won’t have a Computed Entity anymore.
Caution: Enable Load means the result of that entity will be loaded into Azure Data Lake storage. If you uncheck that option, then only the referenced entity will be loaded into Azure Data Lake storage, not the intermediate table.
Sometimes, however, you still need the original entity to be there, as well as the referenced one. In those scenarios. I suggest using Duplicate.
Use Duplicate Instead of Reference
If you use the Reference option, you end up with a new entity which is a Computed Entity. However, if you use a Duplicate from the source entity, then there will be no Computed Entity from it, and you can do the rest of transformations there.
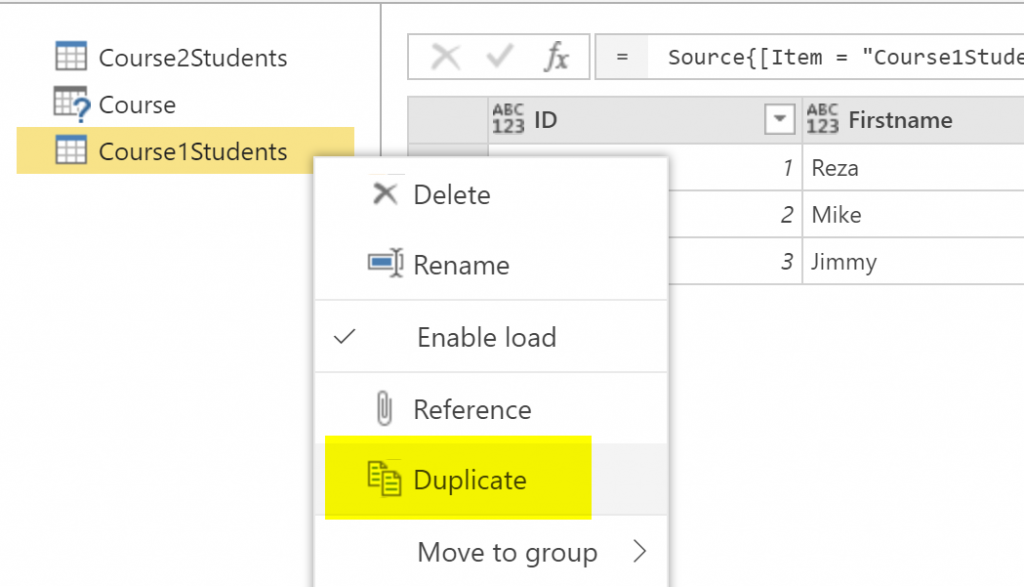
Caution: The Duplicate will create a copy of the entity with all applied steps as a new entity. The two entities after the duplicate action will be totally separated from each other, and a transformation applied on one, won’t affect the other.
If you don’t want this behavior and want to use one of the entities as the main table for transformations, and the other table to be continuing transformation from where the first query finished, you have to use the Reference. To learn more about the difference between Reference and Duplicate, read this article.
As an example of this workaround, I can do an implementation like below:
In one of my articles previously I explained how to create a shared dimension from multiple tables, I had three tables, which they all have Product Number in them. I explained, that we can create a copy of each table using Reference, and then combine them together. Using that method, If we apply any changes in the source tables, all the referenced tables will be having the change respectively, because we used the Reference option.
However, if you want to do that in a Dataflow, and you don’t want the creation of a Computed Entity to happen, you can do that using Duplicate.
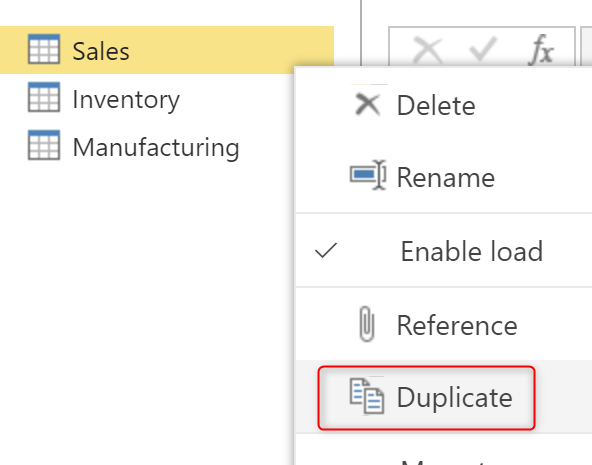
After creating the duplicate for each table, you can uncheck the Enable load option for them.
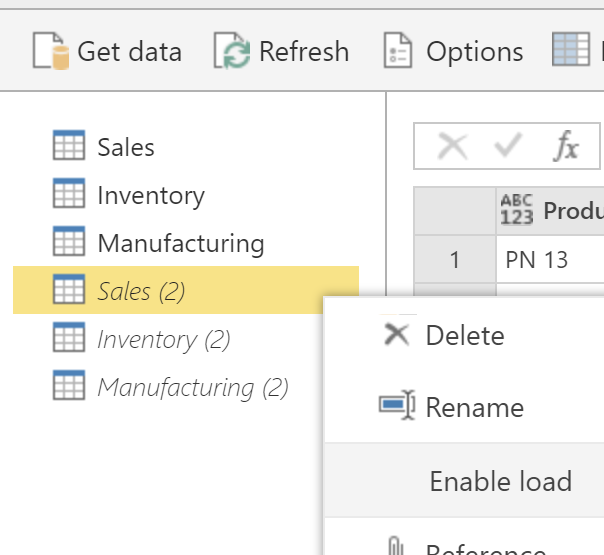
And then you can Append them in a new entity, without creating a Computed Entity;
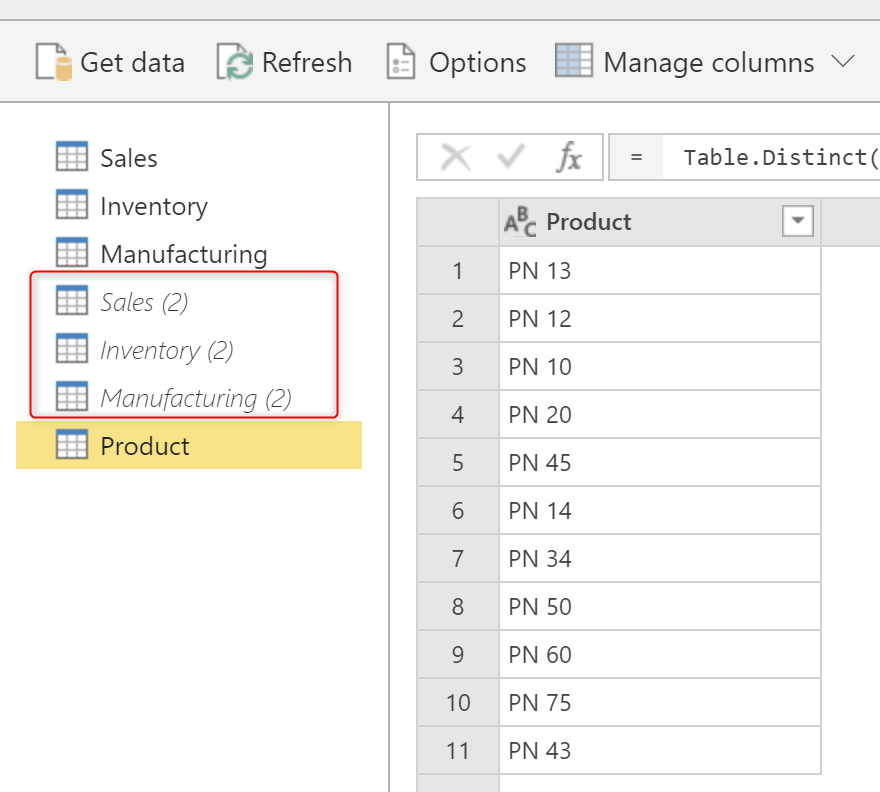
But be careful that the maintenance cost of this method is high. Because every changes that you make in the original tables, then has to be done again in the duplicated tables, or you have to copy the M script from the source table to the duplicate table each time after doing it.
Caution: Keep The Source Transformations Syncronized with Duplicated Entity
When you use the duplicate, the two entities will be separated from each other, and if you apply any transformations in the source entity, the new entity won’t have that transformation. You would need to keep them synchronized. In this type of scenario, usually, we use a Reference option to make sure they are automatically synchronized. However, because this post is about how to do it without the need for such thing, Here is how to keep them synchronized, using copying the M script.
You can right-click on the source entity, and go to Advanced Editor;
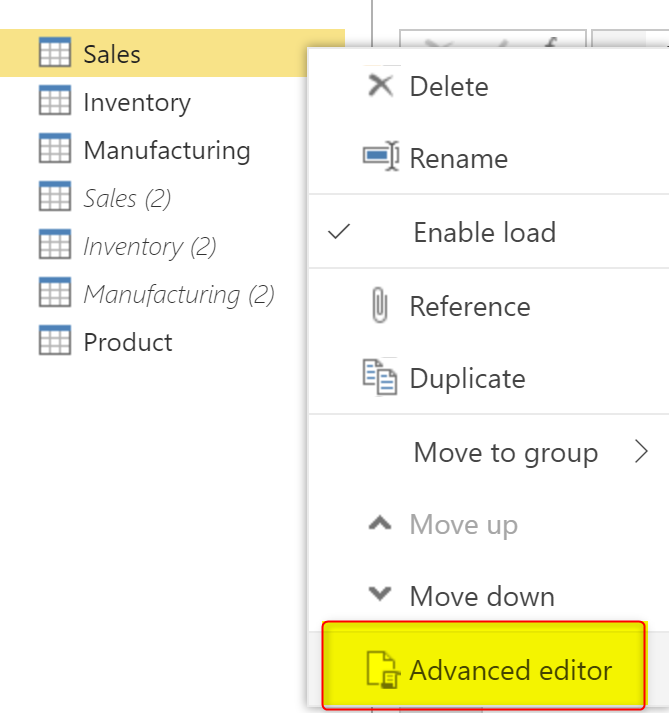
Then copy the entire M script:
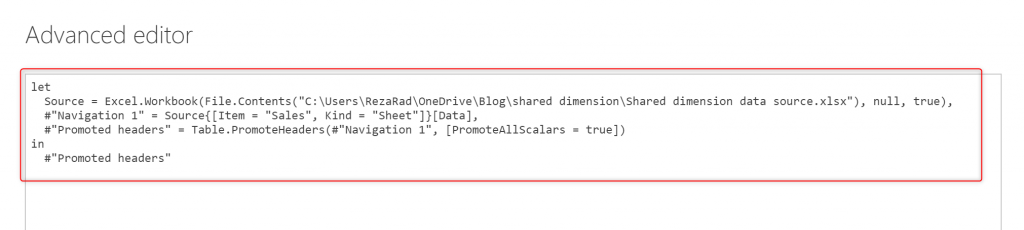
Then go the Advanced editor of the second entity (the duplicated entity), and paste it there.
If you have any further transformations applied in the duplicated entity, you have to make sure, that you keep them there, like this:
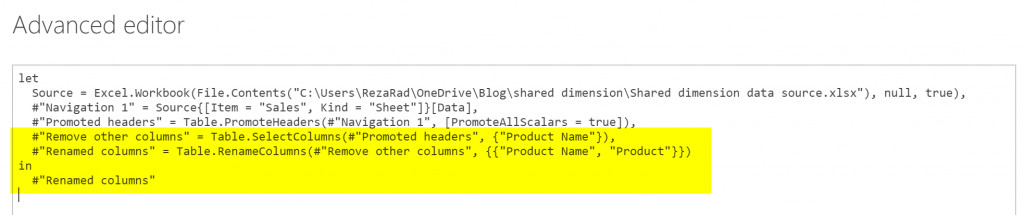
If you like to learn about the scripting language here, read the article about basics of Power Query M Scripting here. When you learn how to make changes in the M Script, you can even do all the above workarounds using the scripting and variables in the M script.
Summary
A Computed Entity is good for the performance of the dataflow transformation because it will store the output of the source table in Azure Data Lake storage. It will be also synchronized with the transformations from the source table. However, You might not need the premium capacity in Power BI, and the size of the dataset for you might be too small, and still, you want to leverage features such as appending or merging tables. If a computed entity is restrictive for you, then you can apply some workarounds as mentioned in this article. However, be cautious that every workaround comes with a side-effect. Make sure you read them before applying it in your solution.
If you wanat to learn more about Power BI Dataflows, read other articles in this series:
Part 1: What are the Use Cases of Dataflow for You in Power BI?
Part 2: Getting Starting with Dataflow in Power BI
Part 3: What is the Common Data Model and Why Should I Care?
Part 4: Linked Entity and Computed Entity; Part 4 of Dataflows in Power BI




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Hey Reza, thanks for this amazing tutorial.
I realized that if you merge before disable the load of the table, the power BI still asks for the premium capacity. But if you disable the load table and only after this, you merge, than it works.
Hi
Even after merge, if you go and disable the load of the source tables, this should not ask for the premium license from you
Cheers
Reza