
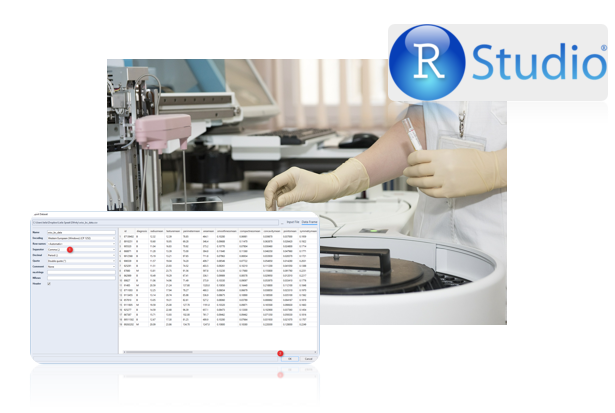
In the previous post (Part 1), I have explained the concepts of KNN and how it works. In this post, I will explain how to use KNN for predict whether a patient with Cancer will be Benign or Malignant. This example is get from Brett book[1]. Imagine that we have a dataset on laboratory results of some patients that some of them already Benign or Malignant. See below picture.
the first column is patient ID, the second one is the diagnosis for each patient: B stand for Benign and M stand for Malignant. the other columns are the laboratory results (I am not good on understanding them!)
We want to create a prediction models for a new patient with specific laboratory results, we want to predict whether this patient will be Benign or Malignant.
For this demo, I will use R environment in Visual Studio. Hence, after opening Visual Studio 2015, select File, New file and then under the General tab find “R”. I am going to write R codes in R scripts (Number 4) and then create a R scripts there.

After creating an empty R scripts. Now I am going to import data. choose “R Tools”, then in Data menu, then click on the “Import Dataset into R session”.
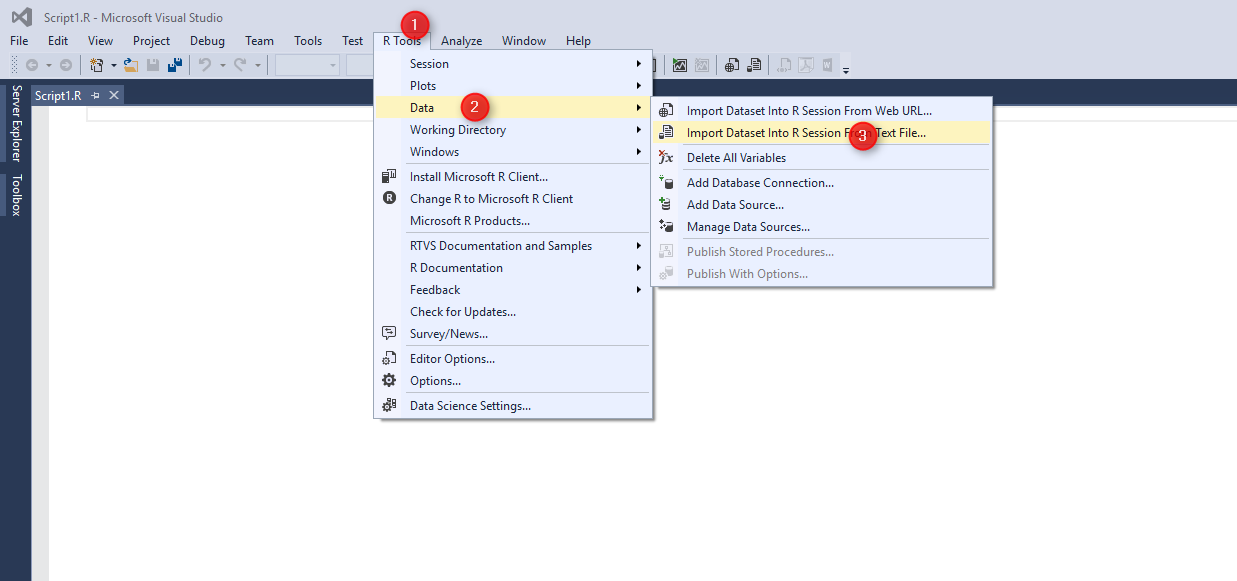
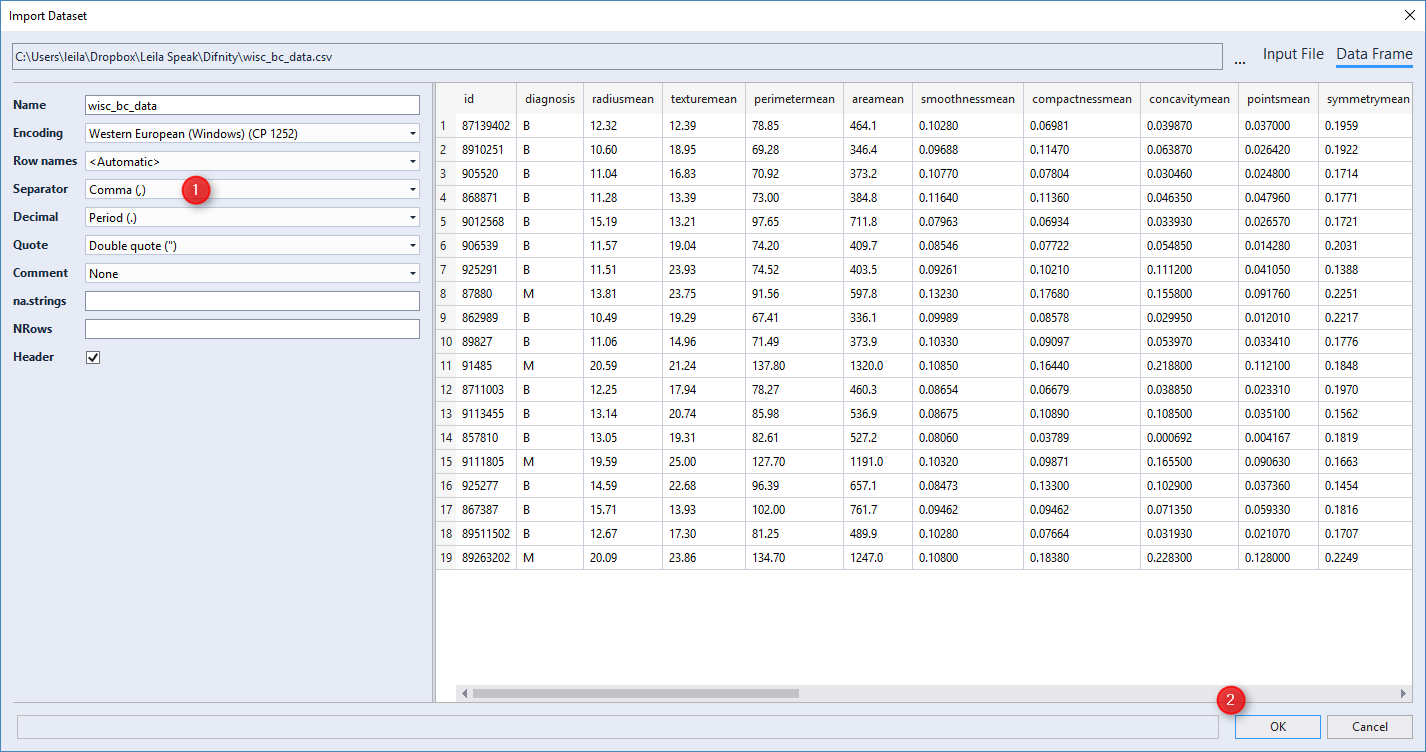
You will see below window. It shows all the columns and the sample of data. The SCV file that I am used for this post has been produced by [1]. It is a CSV file with delimiter (number 1) by Comma.
After importing the dataset, now we are going to see the summary of data by Function “STR”. this function shows the summary of column’s data and the data type of each column.
str(wisc_bc_data)
the result will be:
data.frame': 569 obs. of 32 variables: $ id : int 87139402 8910251 905520 868871 9012568 906539 925291 87880 862989 89827 ... $ diagnosis : Factor w/ 2 levels "B","M": 1 1 1 1 1 1 1 2 1 1 ... $ radius_mean : num 12.3 10.6 11 11.3 15.2 ... $ texture_mean : num 12.4 18.9 16.8 13.4 13.2 ... $ perimeter_mean : num 78.8 69.3 70.9 73 97.7 ... $ area_mean : num 464 346 373 385 712 ... $ smoothness_mean : num 0.1028 0.0969 0.1077 0.1164 0.0796 ... $ compactness_mean : num 0.0698 0.1147 0.078 0.1136 0.0693 ... $ concavity_mean : num 0.0399 0.0639 0.0305 0.0464 0.0339 ... $ points_mean : num 0.037 0.0264 0.0248 0.048 0.0266 ... $ symmetry_mean : num 0.196 0.192 0.171 0.177 0.172 ... $ dimension_mean : num 0.0595 0.0649 0.0634 0.0607 0.0554 ... $ radius_se : num 0.236 0.451 0.197 0.338 0.178 ... $ texture_se : num 0.666 1.197 1.387 1.343 0.412 ... $ perimeter_se : num 1.67 3.43 1.34 1.85 1.34 ... $ area_se : num 17.4 27.1 13.5 26.3 17.7 ... $ smoothness_se : num 0.00805 0.00747 0.00516 0.01127 0.00501 ... $ compactness_se : num 0.0118 0.03581 0.00936 0.03498 0.01485 ... $ concavity_se : num 0.0168 0.0335 0.0106 0.0219 0.0155 ... $ points_se : num 0.01241 0.01365 0.00748 0.01965 0.00915 ... $ symmetry_se : num 0.0192 0.035 0.0172 0.0158 0.0165 ... $ dimension_se : num 0.00225 0.00332 0.0022 0.00344 0.00177 ... $ radius_worst : num 13.5 11.9 12.4 11.9 16.2 ... $ texture_worst : num 15.6 22.9 26.4 15.8 15.7 ... $ perimeter_worst : num 87 78.3 79.9 76.5 104.5 ... $ area_worst : num 549 425 471 434 819 ... $ smoothness_worst : num 0.139 0.121 0.137 0.137 0.113 ... $ compactness_worst: num 0.127 0.252 0.148 0.182 0.174 ... $ concavity_worst : num 0.1242 0.1916 0.1067 0.0867 0.1362 ... $ points_worst : num 0.0939 0.0793 0.0743 0.0861 0.0818 ... $ symmetry_worst : num 0.283 0.294 0.3 0.21 0.249 ... $ dimension_worst : num 0.0677 0.0759 0.0788 0.0678 0.0677 ... >
Now we want to keep the original dataset, so we put data in a temp variable “wbcd”
wbcd <- wisc_bc_data
The first column of data “id” could not be that much important in prediction, so we eliminate the first column from dataset.
wbcd<-wbcd[-1]
We want to look at the statistical summary of each column: such as min, max, mid, mean value of each columns.
summary(wbcd)
The result of running the code will be as below, as you can see for first column (we already delete the id column), we have 357 cases that are Benign and 212 Malignant cases. also for all other laboratory measurement we can see the min, max, median, mean. 1st Qu, and 3rd Qu.
diagnosis radius_mean texture_mean perimeter_mean area_mean smoothness_mean compactness_mean concavity_mean points_mean symmetry_mean dimension_mean
B:357 Min. : 6.981 Min. : 9.71 Min. : 43.79 Min. : 143.5 Min. :0.05263 Min. :0.01938 Min. :0.00000 Min. :0.00000 Min. :0.1060 Min. :0.04996
M:212 1st Qu.:11.700 1st Qu.:16.17 1st Qu.: 75.17 1st Qu.: 420.3 1st Qu.:0.08637 1st Qu.:0.06492 1st Qu.:0.02956 1st Qu.:0.02031 1st Qu.:0.1619 1st Qu.:0.05770
Median :13.370 Median :18.84 Median : 86.24 Median : 551.1 Median :0.09587 Median :0.09263 Median :0.06154 Median :0.03350 Median :0.1792 Median :0.06154
Mean :14.127 Mean :19.29 Mean : 91.97 Mean : 654.9 Mean :0.09636 Mean :0.10434 Mean :0.08880 Mean :0.04892 Mean :0.1812 Mean :0.06280
3rd Qu.:15.780 3rd Qu.:21.80 3rd Qu.:104.10 3rd Qu.: 782.7 3rd Qu.:0.10530 3rd Qu.:0.13040 3rd Qu.:0.13070 3rd Qu.:0.07400 3rd Qu.:0.1957 3rd Qu.:0.06612
Max. :28.110 Max. :39.28 Max. :188.50 Max. :2501.0 Max. :0.16340 Max. :0.34540 Max. :0.42680 Max. :0.20120 Max. :0.3040 Max. :0.09744
radius_se texture_se perimeter_se area_se smoothness_se compactness_se concavity_se points_se symmetry_se dimension_se
Min. :0.1115 Min. :0.3602 Min. : 0.757 Min. : 6.802 Min. :0.001713 Min. :0.002252 Min. :0.00000 Min. :0.000000 Min. :0.007882 Min. :0.0008948
1st Qu.:0.2324 1st Qu.:0.8339 1st Qu.: 1.606 1st Qu.: 17.850 1st Qu.:0.005169 1st Qu.:0.013080 1st Qu.:0.01509 1st Qu.:0.007638 1st Qu.:0.015160 1st Qu.:0.0022480
Median :0.3242 Median :1.1080 Median : 2.287 Median : 24.530 Median :0.006380 Median :0.020450 Median :0.02589 Median :0.010930 Median :0.018730 Median :0.0031870
Mean :0.4052 Mean :1.2169 Mean : 2.866 Mean : 40.337 Mean :0.007041 Mean :0.025478 Mean :0.03189 Mean :0.011796 Mean :0.020542 Mean :0.0037949
3rd Qu.:0.4789 3rd Qu.:1.4740 3rd Qu.: 3.357 3rd Qu.: 45.190 3rd Qu.:0.008146 3rd Qu.:0.032450 3rd Qu.:0.04205 3rd Qu.:0.014710 3rd Qu.:0.023480 3rd Qu.:0.0045580
Max. :2.8730 Max. :4.8850 Max. :21.980 Max. :542.200 Max. :0.031130 Max. :0.135400 Max. :0.39600 Max. :0.052790 Max. :0.078950 Max. :0.0298400
radius_worst texture_worst perimeter_worst area_worst smoothness_worst compactness_worst concavity_worst points_worst symmetry_worst dimension_worst
Min. : 7.93 Min. :12.02 Min. : 50.41 Min. : 185.2 Min. :0.07117 Min. :0.02729 Min. :0.0000 Min. :0.00000 Min. :0.1565 Min. :0.05504
1st Qu.:13.01 1st Qu.:21.08 1st Qu.: 84.11 1st Qu.: 515.3 1st Qu.:0.11660 1st Qu.:0.14720 1st Qu.:0.1145 1st Qu.:0.06493 1st Qu.:0.2504 1st Qu.:0.07146
Median :14.97 Median :25.41 Median : 97.66 Median : 686.5 Median :0.13130 Median :0.21190 Median :0.2267 Median :0.09993 Median :0.2822 Median :0.08004
Mean :16.27 Mean :25.68 Mean :107.26 Mean : 880.6 Mean :0.13237 Mean :0.25427 Mean :0.2722 Mean :0.11461 Mean :0.2901 Mean :0.08395
3rd Qu.:18.79 3rd Qu.:29.72 3rd Qu.:125.40 3rd Qu.:1084.0 3rd Qu.:0.14600 3rd Qu.:0.33910 3rd Qu.:0.3829 3rd Qu.:0.16140 3rd Qu.:0.3179 3rd Qu.:0.09208
Max. :36.04 Max. :49.54 Max. :251.20 Max. :4254.0 Max. :0.22260 Max. :1.05800 Max. :1.2520 Max. :0.29100 Max. :0.6638 Max. :0.20750
>
Data Wrangling
first of all, we want to have a dataset that is easy to read. the first data cleaning is about replacing the “B” value with Benign and “M” value with Malignant in diagnosis column. this replacement makes the data to be more informative. Hence we employ below code:
wbcd$diagnosis<- factor(wbcd$diagnosis, levels = c("B", "M"), labels = c("Benign", "Malignant"))
Factor is a function that gets the column name in a dataset, and we can identify the labels with out consuming memories)
there is another issue in data. the numbers are not normalized!
what is data normalization : that mean they are not in a same scale. for instance for radius mean all numbers between 6 to 29 while for column smoothness_mean is between 0.05 to 0.17. for performing the predict analysis using KNN, as we use distance calculation (Part 1), it is important all numbers should be in same range[1].
normalization can be done by below formula
normalize <- function(x) {
return ((x - min(x)) / (max(x) - min(x))) }
now we are going to apply this function in all numeric columns in wbcd dataset. There is a function in R that apply a function over a dataset:
wbcd_n <- as.data.frame(lapply(wbcd[2:31], normalize))
“lapply” gets the dataset and function name, then apply the function on all dataset. in this example because the first column is text (diagnosis), we apply “normalize” function on columns 2 to 31.Now our data is ready for creating a KNN model.
from machine learning process we need a dataset for training model and another for testing model (from Market basket analysis post)
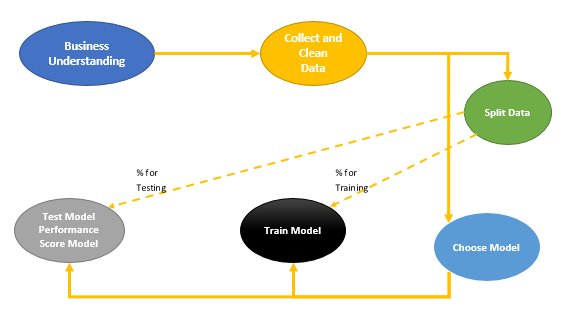
Hence, we should have two different dataset for train and test. in this example, we going to have row number 1 to 469 for training and creating model and from row number 470 to 569 for testing the model.
wbcd_train <- wbcd_n[1:469, ] wbcd_test <- wbcd_n[470:569, ]
so wbcd_train we have 469 rows of data and the rest in wbcd_test. also we need the prediction label for result
wbcd_train_labels <- wbcd[1:469, 1] wbcd_test_labels <- wbcd[470:569, 1]
So data is ready, now we are going to train model and create KNN algorithm.
For using KNN there is a need to install package “Class”
install.packages("class")
Now we able to call function KNN to predict the patient diagnosis. KNN function accept the training dataset and test dataset as second arguments. moreover the prediction label also need for result. we want to use KNN based on the discussion on Part 1, to identify the number K (K nearest Neighbour), we should calculate the square root of observation. here for 469 observation the K is 21.
wbcd_test_pred <- knn(train = wbcd_train, test = wbcd_test,cl= wbcd_train_labels, k = 21)
the result is “wbcd_test_pred” holds the result of the KNN prediction.
[1] Benign Benign Benign Benign Malignant Benign Malignant Benign Malignant Benign Malignant Benign Malignant Malignant Benign Benign Malignant Benign [19] Malignant Benign Malignant Malignant Malignant Malignant Benign Benign Benign Benign Malignant Malignant Malignant Benign Malignant Malignant Benign Benign [37] Benign Benign Benign Malignant Malignant Benign Malignant Malignant Benign Malignant Malignant Malignant Malignant Malignant Benign Benign Benign Benign [55] Benign Benign Benign Benign Malignant Benign Benign Benign Benign Benign Malignant Malignant Benign Benign Benign Benign Benign Malignant [73] Benign Benign Malignant Malignant Benign Benign Benign Benign Benign Benign Benign Malignant Benign Benign Malignant Benign Benign Benign [91] Benign Malignant Benign Benign Benign Benign Benign Malignant Benign Malignant Levels: Benign Malignant
we want to evaluate the result of the model by installing “gmodels” a packages that shows the evaluation performance.
install.packages("gmodels")
require("gmodels")
library("gmodels")
we employ a function name “CrossTable”. it gets label as first input, the prediction result as second argument.
CrossTable(x = wbcd_test_labels, y = wbcd_test_pred, prop.chisq = FALSE)
The result of “Cross table” will be as below. we have 100 observation. the tables show the result of evaluation and see how much the KNN prediction is accurate. the first row and first column shows the true positive (TP) cases, means the cases that already Benign and KNN predicts Benign. The first row and second column shows number of cases that already Benign and KNN predict they are Malignant (TN). The second row and first column is Malignant in real world but KNN predict they are Benign (FP). finally the last column and last row is False Negative (FN) that means cases that they Malignant and KNN predict as Malignant.
Total Observations in Table: 100
| wbcd_test_pred
wbcd_test_labels | Benign | Malignant | Row Total |
-----------------|-----------|-----------|-----------|
Benign | 61 | 0 | 61 |
| 1.000 | 0.000 | 0.610 |
| 0.968 | 0.000 | |
| 0.610 | 0.000 | |
-----------------|-----------|-----------|-----------|
Malignant | 2 | 37 | 39 |
| 0.051 | 0.949 | 0.390 |
| 0.032 | 1.000 | |
| 0.020 | 0.370 | |
-----------------|-----------|-----------|-----------|
Column Total | 63 | 37 | 100 |
| 0.630 | 0.370 | |
-----------------|-----------|-----------|-----------|
so as much as TP and FN is higher the prediction is better. in our example TP is 61 and FN is 37, moreover the TN and TP is just 0 and 2 which is good.
to calculate the accuracy we should follow the below formula:
accuracy <- (tp + tn) / (tp + fn + fp + tn)
Accuracy will be (61+37)/(61+37+2+0)=98%
In the next post I will explained how to perform KNN in Power BI (data wrangling, modelling and visualization).
[1].Machine Learning with R,Brett Lantz, Packt Publishing,2015.



