

Azure ML Services has a new component that has been announced a couple of months ago, name Automated Machine Learning. I already start to write about Azure ML Services and Automated ML specifically recently ( which will continue 🙂 ). In Post one to 4 you can find all discussions ( Post 1, Post 2, Post 3, and Post 4).
In this post, I briefly explain the algorithms and pre-process approaches that have been used in Azure Automated ML.
Algorithms
If you are using Azure Automated ML you can select the prediction tasks ( see below)
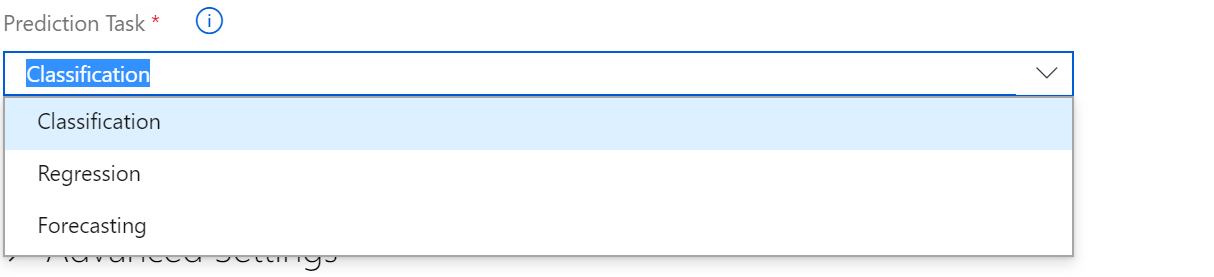
Or if you using the Azure Not book and Python for Automated model, you able to choose the prediction task via Python code as below.
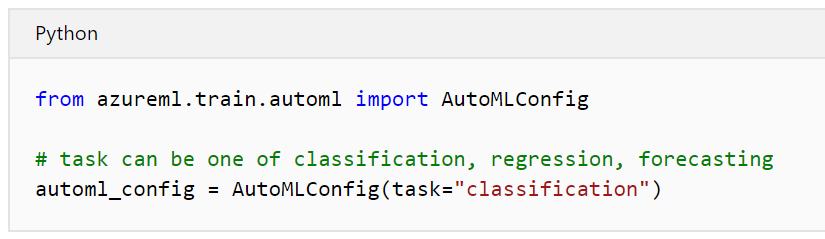
No matter what approaches (via Azure NOtebook or Automated ML interface) you are using for choosing the prediction task, there are a list of algorithms that have been applied on the dataset as below table [1]
If you click on each of those algorithms, will see some technical explanation on specific algorithms.
Some of the algorithms can be seen in all three tasks, like KNN or decision tree. If you click on the explanation of these algorithms, you will see how these algorithms can be used for classification and regression approaches.
Data preprocessing & featurization
In most machine learning practice, we need to do some pre-process activities such as remove missing values, scaling data, group and binning, and feature selections.
In Automated ML ( wizard) or Azure NOte book ( Python codes), you will able to access standard preprocess and advance preprocess options.
Standard Preprocess
If you are using Automated ML, by default the standard preprocess will apply. The standard one is limited to the normalizing the data. For most ML algorithms you need to scale data based on the nature of data. One of the below approaches may be used for scaling based on the nature of data.
| Scaling & normalization | Description |
|---|---|
| StandardScaleWrapper |
Standardize features by removing the mean and scaling to unit variance
|
| MinMaxScalar |
Transforms features by scaling each feature by that column’s minimum and maximum
|
| MaxAbsScaler |
Scale each feature by its maximum absolute value
|
| RobustScalar |
This Scaler features by their quantile range
|
| PCA |
Linear dimensionality reduction using Singular Value Decomposition of the data to project it to a lower-dimensional space
|
| TruncatedSVDWrapper |
This transformer performs linear dimensionality reduction by means of truncated singular value decomposition (SVD). Contrary to PCA, this estimator does not center the data before computing the singular value decomposition. This means it can work with scipy.sparse matrices efficiently
|
| SparseNormalizer |
Each sample (that is, each row of the data matrix) with at least one non-zero component is re-scaled independently of other samples so that its norm (l1 or l2) equals one
|
Advance Preprocessing
For, having access to more data preparation, you can choose the preprocess be active wether in Automated ML or Azure Notebook ( Python). In Automated ML, if you choose the Preprocessing option ( as shown below) then you will get a list of preprocessing options.

The same in Python code in Azure NOtebook, you will able to access the preprocessing,
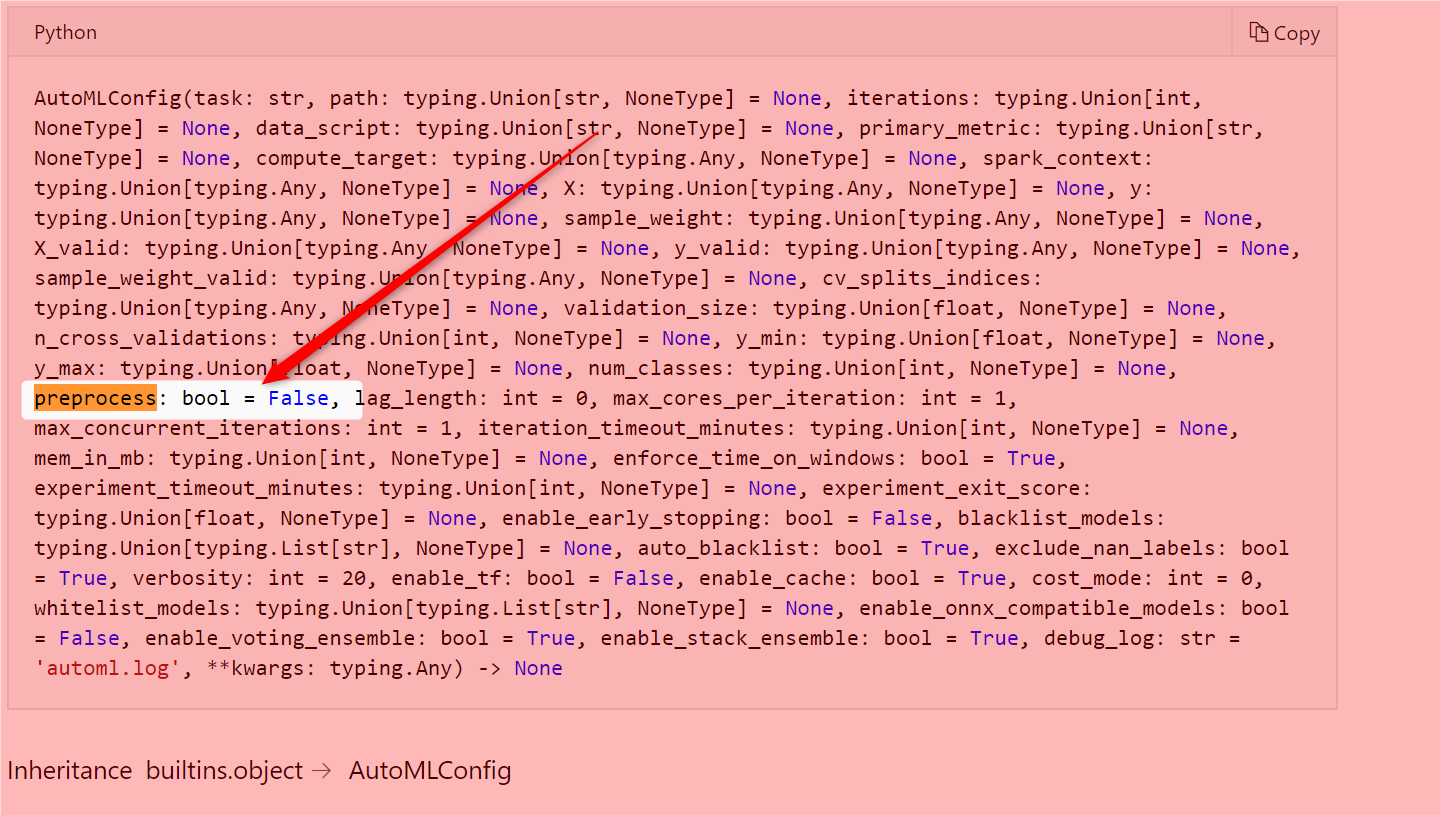
need to set the value to
preprocess:bool=True
By activating the preprocess task ( via Python code or via visual interface), below tasks will run automatically apply to your data [2].
Pre Processing steps |
Description |
| Drop high cardinality or no variance features |
Drop these from training and validation sets, including features with all values missing, same value across all rows or with extremely high cardinality (for example, hashes, IDs, or GUIDs).
|
| Impute missing values |
For numerical features, impute with an average of values in the column. For categorical features, impute with most frequent value.
|
| Generate additional features |
For DateTime features: Year, Month, Day, Day of the week, Day of Year, Quarter, Week of the year, Hour, Minute, Second. For Text features: Term frequency based on unigrams, bi-grams, and tri-character-grams.
|
| Transform and encode |
Numeric features with few unique values are transformed into categorical features. One-hot encoding is performed for low cardinality categorical; for high cardinality, one-hot-hash encoding.
|
| Word embeddings |
Text feature that converts vectors of text tokens into sentence vectors using a pre-trained model. Each word’s embedding vector in a document is aggregated together to produce a document feature vector.
|
| Target encodings |
For categorical features, maps each category with the averaged target value for regression problems, and to the class probability for each class for classification problems. Frequency-based weighting and k-fold cross-validation are applied to reduce overfitting of the mapping and noise caused by sparse data categories.
|
| Text target encoding |
For text input, a stacked linear model with bag-of-words is used to generate the probability of each class.
|
| Weight of Evidence (WoE) |
Calculates WoE as a measure of the correlation of categorical columns to the target column. It is calculated as the log of the ratio of in-class vs out-of-class probabilities. This step outputs one numerical feature column per class and removes the need to explicitly impute missing values and outlier treatment.
|
| Cluster Distance |
Trains a k-means clustering model on all numerical columns. Outputs knew features, one new numerical feature per cluster, containing the distance of each sample to the centroid of each cluster.
|
Reference:
[2]https://docs.microsoft.com/en-us/azure/machine-learning/service/how-to-create-portal-experiments




Thanks Leila,
So happy I found your post mentioning “Weight of Evidence (WoE)” to “measure of the correlation of categorical columns to the target column”. I’ve been struggling with the optimal number of bins to stuff nearly 4000 nominal categoricals into. More or less than 99 bins. (Mine is regression project, with the target label as a series of continuous integers from 1 to 99).
Is it only available in Azure AutoML? Can I drag it in and connect it as one of the modules in Azure ML workspace, say after a “Select Columns”?
Thanks for your series. I’ll be studying them in depth!
Nam Nguyen
You are welcome, I need to check that good question