
In previous posts (Part 4 and Part 5), I have explained some of the main components of Azure ML via a prediction scenario. In post one the process of data cleaning (using SQL Transformation, Cleaning Missing Value, Select specific Columns, and Edit Meta Data) has been explained. and in the second Post, I have explained how to apply Data normalization, Feature selection and how to split Data for creating Training and Testing Datasets has been explained.
In this post I will continue the scenario of predicting patient diagnosis to show how to select appropriate algorithms, Train Models, and Test Models (Score), In the next post I will show how to evaluate a model using “Evaluate Model” component, also how to find the best parameters for algorithms using Tune Model Hyperparameters, and also check the algorithm evaluation result on different portion of the dataset using Cross Validate component.
How to choose Algorithms
There are many algorithms that address the different types of machine learning problems. In Azure ML, there are four types of the algorithms : Anomaly Detection, Classification, Clustering, and Regression.
Anomaly Detection : this types of algorithms are helpful for finding cases that not follow the normal pattern of the data such as finding the fraud in credit cards (above pictur3e Number 1).
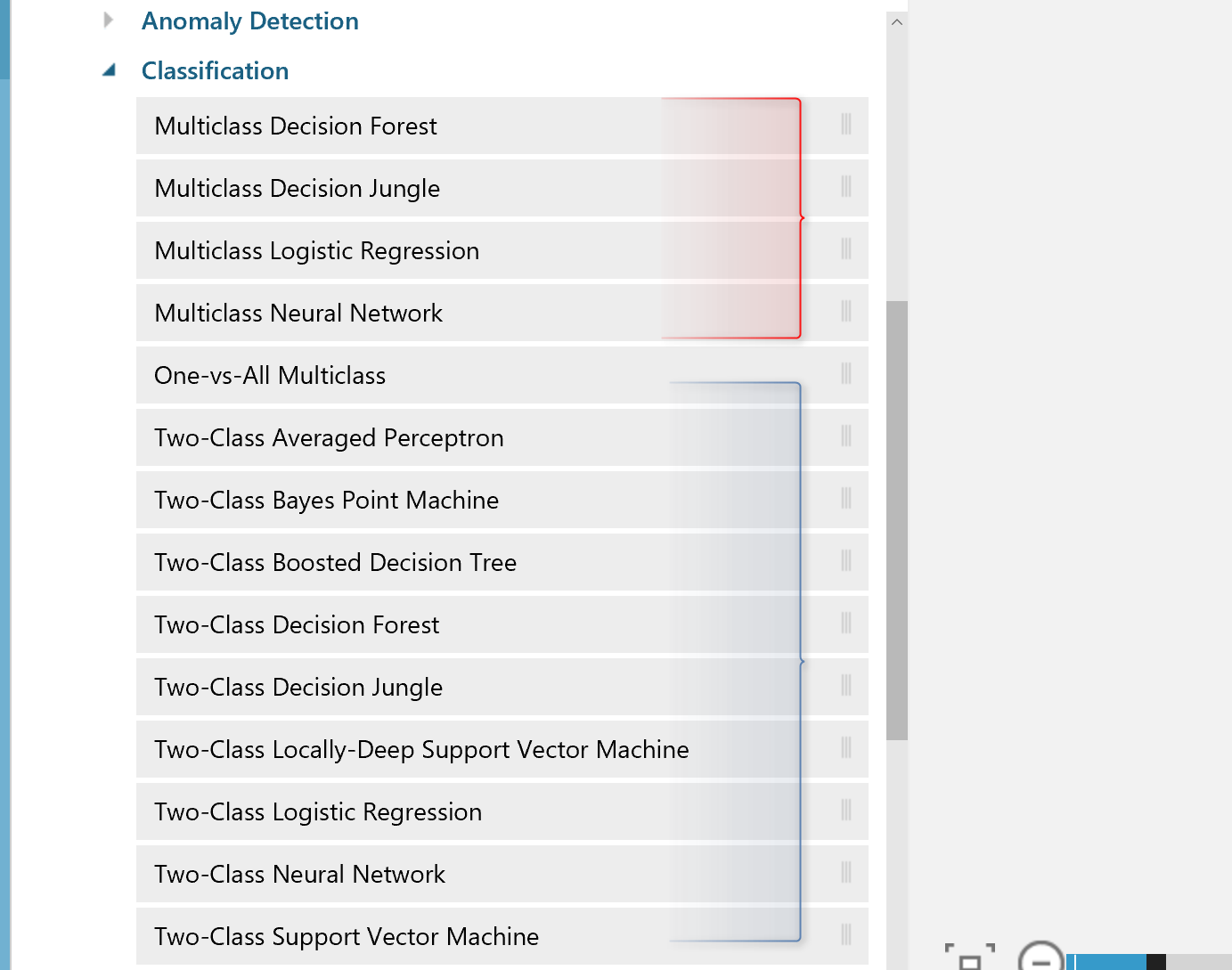
Classifications: Classification can be used for predicting a group. For instance, we want to predict whether a customer will stay with us or not, or a customer will get a Bronze, Silver, or Gold membership. In Azure ML we have two sets of algorithms for classification as : Two-Class and Multi-class algorithms (See below Picture)
Clustering
Clustering algorithms like k-mean clustering (I have a post on it) more used for finding the natural pattern in data without doing a prediction.
Regression
Regression algorithms is used for predicting a value. for instance predicting the sales amount in a company.
In this scenario we are going to predict whether a patient will be Benign or Malignant. So I have to use a two-class algorithms.
So I am going to use two-class classification algorithms.
To get a better result, it always recommend to :
Try different algorithms on a dataset to see which one better able to predict.
Try different Dataset it is good idea to divide a current dataset to multiple one, and then check the algorithms evaluation in different parts of a dataset. in this scenario I am going to use a component name “Cross Validate Model”
Try different algorithms Parameters. Each algorithms has specific parameter’s values, It always recommended to try the different parameter’s value. there is a component in Azure Ml called “Tune Model Hyperparameters”, that run the algorithms against different parameter’s value.
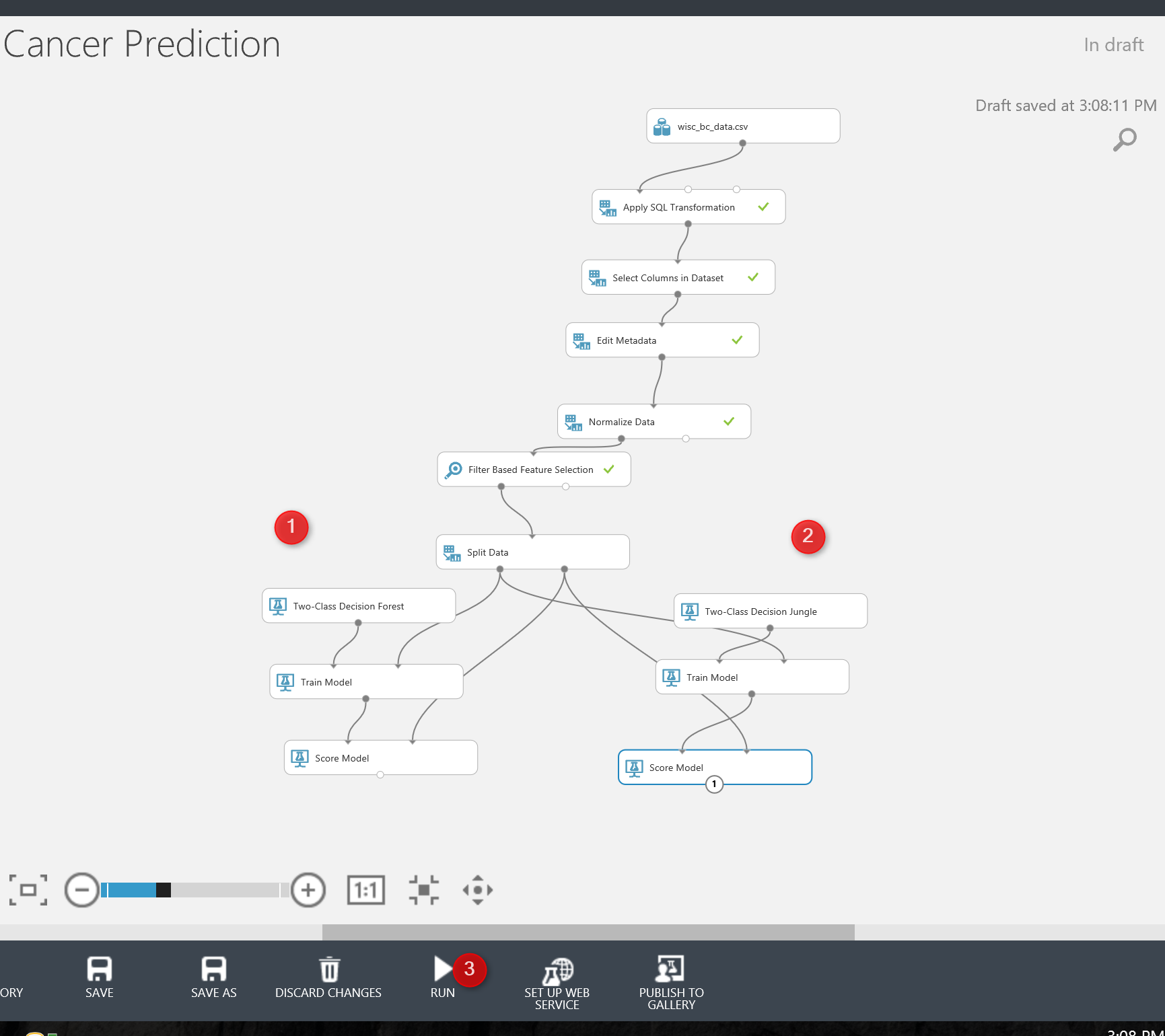
first I am going to try two algorithms on a single dataset to see which one better predict the patient’s diagnosis.
I select the “Two-Class Decision Forest” and “Two-class Decision Jungle” to see which one better predict.
I just simply search for them in left side menu, and drag and drop them into experiment area.
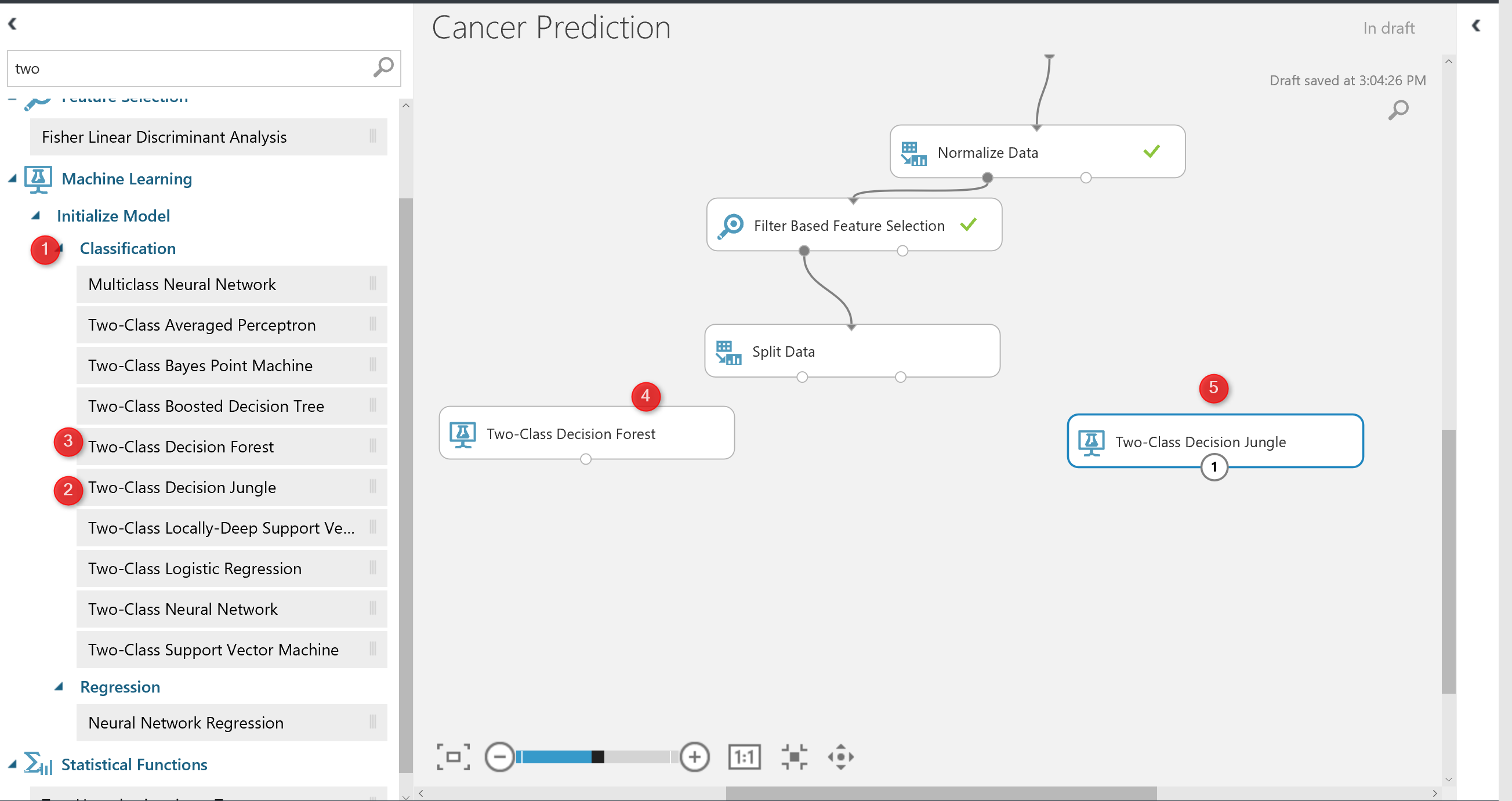
to work with thee models we need to train them first, there is a component name “Train Model” that help us to train a model. Train model component gets two input: one from algorithm and the other from dataset (in out example from split output node at the left side) see below picture. Moreover, just click on the train model components, and in the right side of the experiment in properties (number 4), we have to specify the columns that we want to predict. in this example is “Real Diagnosis”.

Finally, we have to test the model. To test a model in Azure ML, there is component name “Score Model“. search for it and drag and drop it into experiment area. The score model gets first input from train model component, that is a machine learning algorithm, and the right side input from the split component the output for testing dataset.
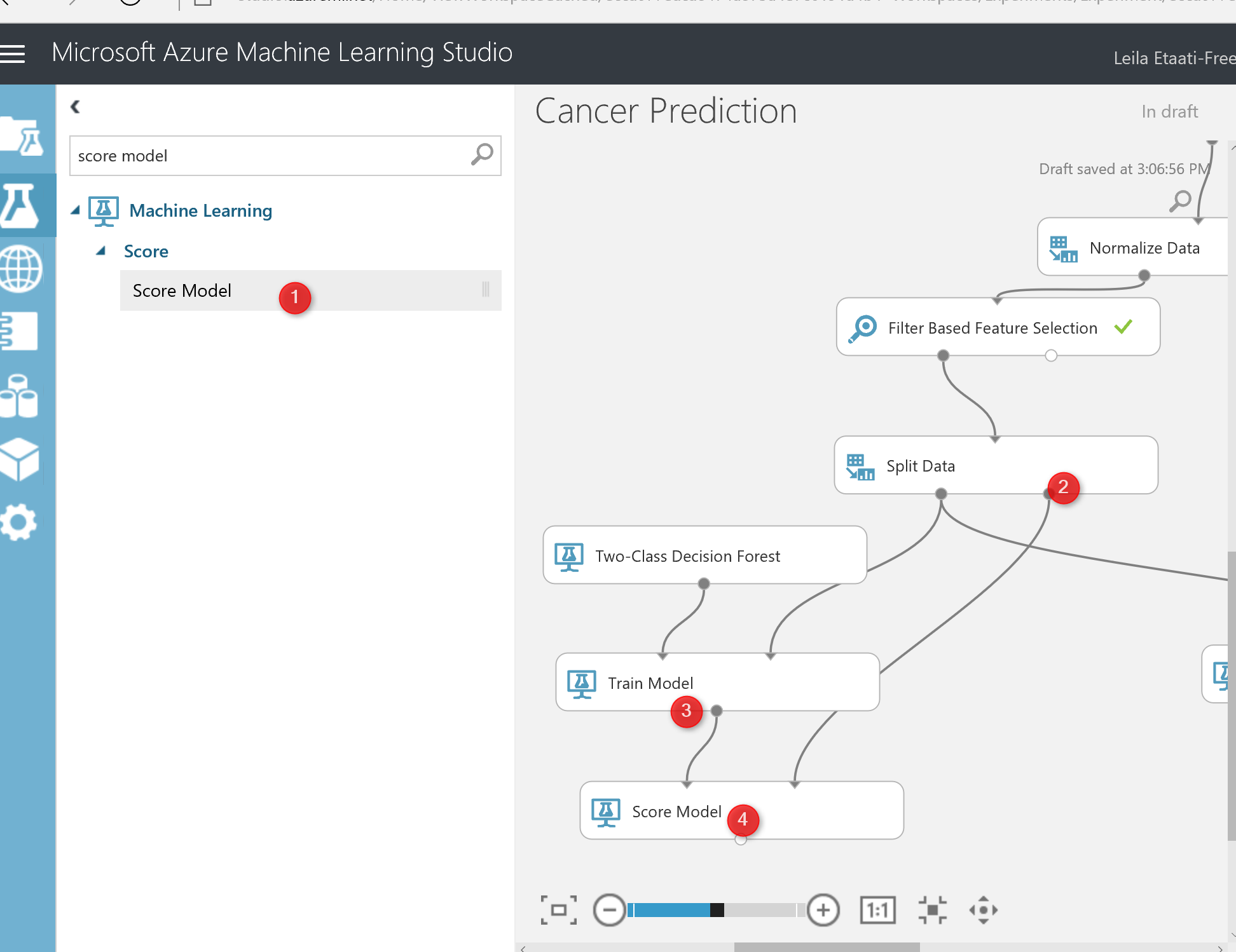
I just created the same process for “two-class decision jungle and forest” (see below picture). Now I am going to run the experiment, to see the result.
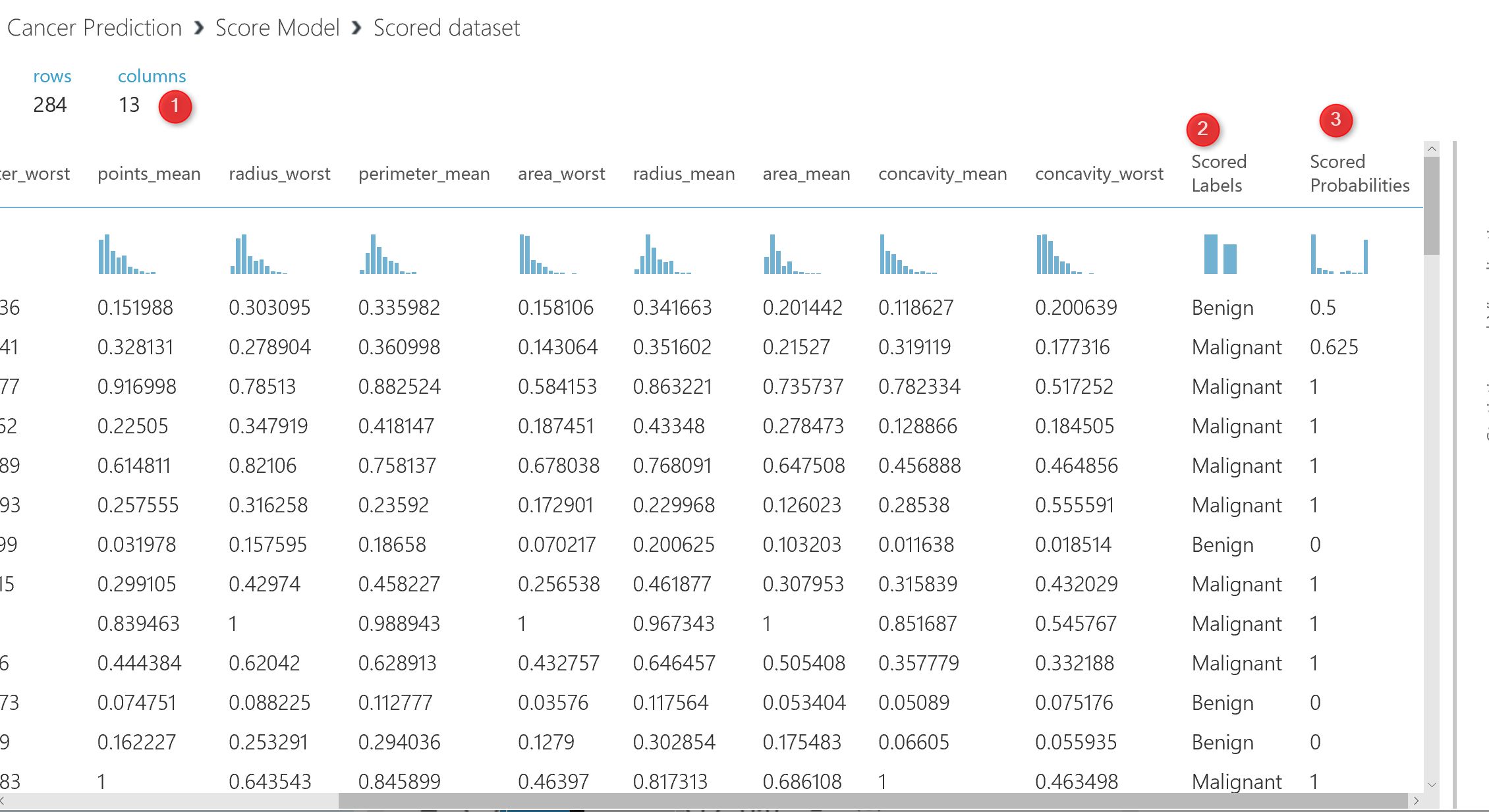
after the running the experiment, just click on the output node of one of the score model and visualize the dataset. in this dataset, you will see that we have 284 rows (that is the testing dataset), also you will see that we have 13 columns instead of 11. the 2 other columns are for the result of predictions as:Score Label and Score Probabilities.
The Score Label: show the prediction of the diagnosis for patients . The score Probabilities show the probability of predictions. For instance, for the first row the prediction of the model was patient with these laboratory result will be Benign with 50% probability
In the next post I will show How to evaluate the result of the prediction, how to try different algorithm parameters using tune hyper parameters, and also how to check different dataset using Cross Validation.



