
Power BI is one of the BI tools in the market that supports more than one type of connection. Each connection type has pros and cons. In this section, we are going to cover everything about Import Data or Scheduled Refresh type of connection. You will learn briefly how Power BI stores data into xVelociy in-memory engine, and what are pros and cons of this method in detail.
Video
Connection Type is not Data Source Type
Connection type doesn’t mean the data source type. Apparently, Power BI supports more than 160 of data source types. Connection Type is the way that the connection is created to the data source. One data source can support multiple types of connections. For example, you can connect to SQL Server database with Import Data or DirectQuery. It is the same data source, however different types of connections.
Every Connection type has some advantages and disadvantages. One connection type is suitable for smaller datasets, one for big, one connection type is useful for better flexibility, the other for not needing the scheduled refresh, etc. You cannot change the type of connection in the middle of your Power BI development cycle. Choosing the connection type is one of the decisions that should be made at the beginning. Otherwise, you might end up with a lot of re-work.
Import Data or Scheduled Refresh
Import Data is the first type of connection, which I explain here in this post. This type of connection imports the whole dataset into the memory. This memory will be the memory of the machine that hosts the Power BI dataset. If you have a Power BI dataset opened in Power BI Desktop, then it will be the memory of the machine that Power BI Desktop is running on it. When you publish your Power BI file on the Power BI website, it will be the memory of that machine in the cloud.
Loading data into the memory also means something more; data needs to be refreshed. The process of updating the data needs to be scheduled if you are using this method of connection. Otherwise, data will be obsolete. That is why this technique is called Import Data, or Scheduled Refresh.
Closer Look at Import Data
To have a closer look at import data, let’s create a report with this type of connection. Open Power BI Desktop, and click on Get Data. Select from Excel.
Select the Excel file Pubs Descriptions.xlsx, select all tables from the list shown in Navigator, and then click on Load.

Loading Data to Model
You will see that Power BI loads this data into the model.

As you probably guessed already this is Import Data Connection Type. Excel data source only supports Import Data Connection type. If a connection type supports multiple connection types, then you can choose it when you are connecting to that source. For example, if you are connecting to SQL Server database, you will see an option to choose Import Data or another option.
How Does Power BI Store Data into Memory
The very first question that comes to your mind is then how big the memory needs to be? What if I have hundreds of millions of records? Or many gigabytes of data? How does Power BI store data in the memory? To answer that question, you need to learn first a little bit about the in-memory engine named xVelocity.
Power BI, SQL Server Analysis Services Tabular, and Power Pivot are three technologies that are using the same engine for storing data. In-memory engine named xVelocity. xVelocity is storing data in the memory. However, it applies a few compression steps to the data before storing it. The data stored in the memory would not be the same size as your data source in the majority of the cases. Data will be compressed significantly. However, the compression is not always at the same rate. Depending on many factors, it might behave differently.
How xVelocity Compresses the Data
To learn the whole concept of data compression in xVelocity, you need to read a book. However, in this section very briefly I’m going to explain to you what happens when the xVelocity engine works on compressing the data.
Traditional database technologies stored data in the disk because it was mainly big. Considering a table such as below;

As you can see in the above image; every column consumes some space depending on the data type of the column. The whole row ends up with 100 bytes. Then for 100 million rows in the table, you will need 10 gigabytes of space on the disk. That is why the traditional technologies stored their data on the disk.
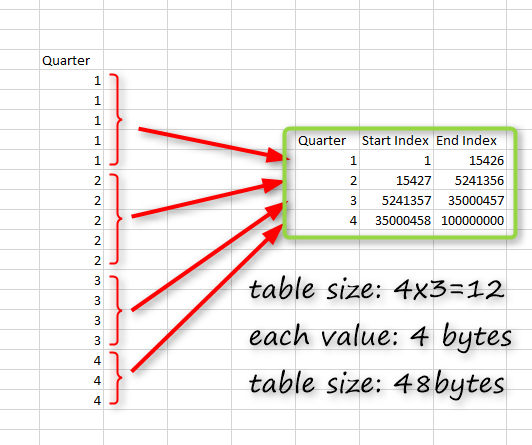
xVelocity uses Column-store technology combined with other performance-tuned compression algorithms. In simple words; xVelocity stores data column by column, it will first sort every column by its values. Then it will create a mapping table for it with indexes at the beginning and end of each section.
The whole point of this compression is that when you have a huge column, a lot of values are repetitive in that column. For the Quarter column in the example above, you can have only four unique values. So instead of storing that for 100 million times, which takes about 400MB of space (4 bytes every value, multiplied by 100 million rows will be equal to 400MB), you can store unique values and their start and end index.
The mapping table shown in the above image is a table of three columns, and four rows mean 12 values. Even considering 4 bytes for each; this table would end up being 48bytes only. The method explained in the above paragraphs is roughly how the compression engine works in xVelocity.
Compression has other levels as well, and it even compresses data more than this a little bit. But this mapping table is the core of compression. Learning this means you know that the data before loading into the memory of Power BI will be compressed. The size of data is probably not the same size as the data in your source database or file. You might have an Excel file of 800MB size, and when you load it into Power BI, your model becomes 8 MB size. The compression obviously depends on many things; cardinality of the data, number of unique values in each column, etc.
Important: If you have a column with a lot of unique values, then compression engine of Power BI suffers, and Power BI memory consumption will be huge. Examples are the ID of the fact tables (Not ID of dimensions that used in the fact table as a foreign key), or some created or update DateTime columns that even sometimes has millisecond information.
Where the Data Stored in the Memory
Your next question maybe is where the data is stored in the memory. Power BI models are always loaded into the Analysis Services engine. Even if you don’t have Analysis Services installed, it will be in your system, when you use Power BI with the Import Data connection type.
To check this feature; Go to Task Manager of the machine that you have a Power BI Desktop with Import Data connection mode opened in it, and you’ll find the Microsoft SQL Server Analysis Services engine is running. Here is where your data is stored in the memory. Analysis Services keeps that in memory.

When you save and close your Power BI file, then that data will be persisted in a *.pbix file. The next time you open the file, data will be loaded again into Analysis Services in-memory engine.
How about Service?
In the Power BI Service, you can also see how much every dataset consumes memory. Just click on the Setting icon, and then on Manage Personal Storage.

Here you will look at all datasets and their sizes

Is there a Limitation on the Size?
If you are developing Power BI files and then publishing them to the service, there is a limitation on the size of the file. Because the Power BI service is a cloud-based shared hosting service for Power BI datasets, then it needs to limit the access so that everyone can use the service in a reasonable response time.
At the time of writing this post, the limit for Power BI file size is 1 GB per model (or dataset in other words) if you use a Power BI Pro or Free account. You will have 10 GB of space in your account, but every file cannot be more than 1 GB. If you load your data into Power BI, and the file size ends up being more than 1 GB, then you need to think about another connection type.
Important: Power BI Premium is a licensing that offers dedicated capacity in Power BI service. With Power BI premium, you can have much more extensive datasets. At the time of writing this post, the dataset size for Power BI premium models can be up to 400 GB. There is a per-user option for premium called Premium Per User (PPU), which gives you the dataset size of 100 GB. To learn more about the licensing options in Power BI, read this article.
Combining Data Sources; Power Query Unleashed
So far you know how the Import Data connection type works. Now let’s see scenarios that this type of connection is suitable for those. One of the advantages of this type of connection is the ability to combine any type of data source. Part of the data can come from Excel, and another part from SQL Server database, or from a web page. With the Import Data connection type, Power Query is fully functional.
To see that through the example; in the same Power BI file that you used so far (which has data from Pubs Descriptions.xlsx Excel file in it), click on Get Data and choose from Text/CSV.
Now select the Pubs Transactions.csv file, and then click on Load. Then click on the model tab. The model tab is on the left-hand side panel, the bottom option. You will see tables from both data sources are connected to each other.

One of the main benefits of Import Data is that you can bring data from any data source, and combine them with each other.
You can also leverage full functional Power Query with this connection type. You can do many data transformations and calculations with Power Query.
To see the Power Query transformations, click on Transform data;
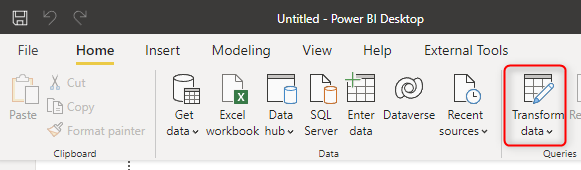
You can then see the Power Query Editor with many transformations built-in to use. In this example, we are not going to talk about that more in detail. To learn Power Query, you should read books, and one of them is Power BI from Rookie to Rock Star book with a lot of Power Query examples.
DAX: Powerful Analytical Expression Language
Another powerful functionality of Power BI which you have access to it when using Import Data is DAX. DAX is the language that you can leverage to do analytical calculations. Calculations such as Year to Date, a rolling average of 12 months, and many other calculations become super-efficient to be done in DAX. DAX is a language that is supported in all xVelocity technologies of Microsoft (Power BI, Power Pivot, and SQL Server Analysis Services Tabular).
You can write any DAX calculations in Import Data mode, such as Quantity Year to date as below;
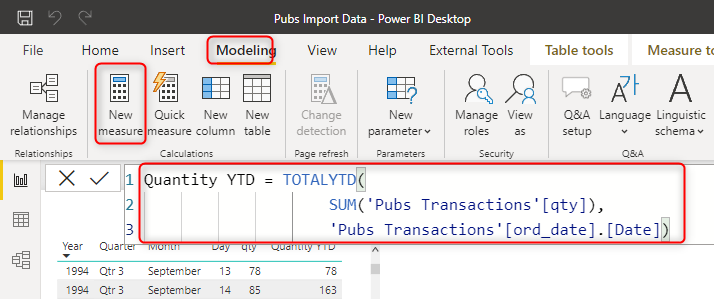
The calculation above is a measure defined in DAX with the code below;
Quantity YTD = TOTALYTD(
SUM('Pubs Transactions'[qty]),
'Pubs Transactions'[ord_date].[Date])And the result of that calculates the year-to-date value of the quantity.

DAX is another powerful component of Power BI. This component is fully functional in Import Data. There are many calculations you can write with this. DAX is a whole language to learn itself. I recommend reading the Power BI book from Rookie to Rock Star with many DAX examples in it to learn it in detail.
Publish the Report
Publishing a report is all the same for Import Data or other types of connections. You can click on Publish in the Home tab, and publish it to your workspace.
Gateway Configuration
For Import Data connection types that use on-premises data sources, you need to have a gateway. If your data sources are all cloud-based (such as Azure SQL database etc.), you don’t need a gateway for that.
Because in the Import Data connection type, you can easily combine multiple data sources with each other, it is very likely that your Power BI file has more than one data source in it. You need first to check all data sources in your Power BI Desktop and define them all under the gateway.
To find data sources in Power BI Desktop, click on the Home tab, under Transform data, Data Source Settings.
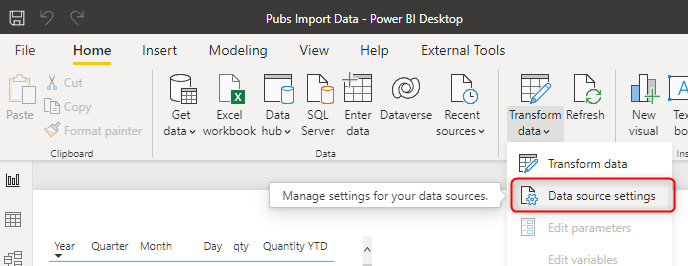
Here you will find all the data sources;

In the previous post, I explained how to add data sources in the gateway. You need to make sure that all data sources in the *.pbix file are defined under the same gateway. Otherwise, you won’t be able to use this gateway for the dataset. To learn how to install the gateway, or add data sources to it, read the previous post.

Schedule Refresh
After adding all sources, then you can connect this gateway to the dataset, in the scheduled refresh configuration of the dataset.
After connecting the gateway, then you can set a scheduled refresh. Refreshed can be scheduled weekly, or daily. With a maximum number of refreshes up to 8 times a day (with Power BI Premium, you can refresh it up to 48 times a day).

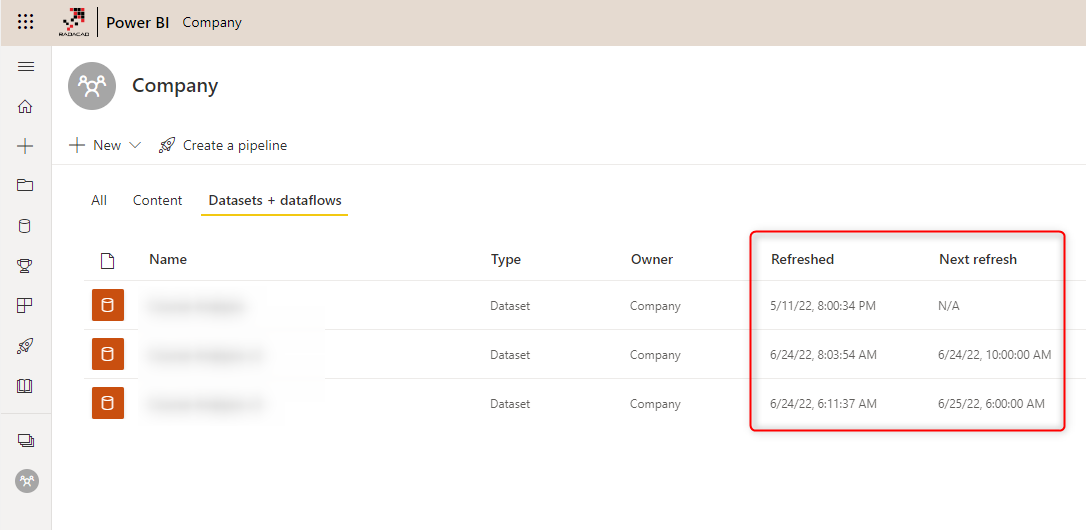
After setting up the scheduled refresh, you can see the next refresh and the last refresh time in the dataset properties.
Advantages and Disadvantages of Import Data
Let’s wrap up things and see what the pros and cons of Import Data are, and what are scenarios that this connection type is useful. This section is a wrap-up of what is explained above, just a quick review of those;
Advantages of Import Data
Speed: In-Memory Engine
Another advantage of the Import Data connection type is the super-fast response time. Remember that this is an in-memory technology and querying data from memory is much faster than querying from disk. This method of connection is the fastest method of connection in Power BI.
Flexibility: DAX and Power Query
With this method, you have Power Query and DAX fully functional. Power Query and DAX are two dominant components of Power BI. In fact, Power BI without these two elements is just a visualization tool. The existence of Power Query and DAX made this tool an extraordinary tool that can cover all analytics requirements. If you use Power BI with other types of connections, you don’t have these two components fully functional. Import Data gives you the flexibility to do data manipulation with Power Query, and analytical calculations with DAX.
Disadvantages of Import Data
The requirement to Schedule Refresh
In many BI scenarios, data will be refreshed overnight or on a scheduled basis. However, sometimes demand is to have data without delay. Import Data is not capable of doing that. With Import Data, there is a need for the dataset to be refreshed. And it can be scheduled to refresh up to 8 times a day (or 48 times a day with Power BI Premium).
Very-large-scale data
If your dataset is massive, let’s say petabytes of data, and the compression engine of Power BI cannot fit it into the allowed size (which is 1 GB per model for pro, and 400 GB per model for premium), then you must change the type of connection. Alternatively, you can choose to be part of a Power BI Premium capacity and leverage a larger dataset allowance with that option.
When to use the Import Data?
Now the million-dollar question that when is good to use the Import Data method?
Import Data should be your first choice when choosing a connection type in Power BI, The reason is that it gives you so much flexibility, power, and performance, that avoiding it would come at big costs. I would say, try to import your data into Power BI, if you cannot do it (maybe the size is too big, or a real-time dashboard is needed, etc) then you can think of other methods. but the Import Data has to be the first option you would try.
Summary
In this post, you learned about Import Data or Scheduled Refresh. With this type of connection, the data will be imported into the memory. However, data will be compressed, and the copy of the data in memory would be usually smaller than the actual data source size. Because this method copies the data into the memory, so you do need to set a scheduled refresh for this model.
Import Data or Scheduled Refresh is the fastest method, the agilest way of working with Power BI, and the most thoroughly functional connection type in Power BI. It allows you to combine multiple data sources with Power Query, write analytical calculations with DAX, and finally visualize the data. This method is super-fast because reading data from memory is always faster than reading from disk.
However, The Import Data mode has a couple of limitations; the need to refresh data is one of them, and the other one is the size limitation of Power BI files. Size limitation can be lifted using Power BI premium capacity, or by changing to other types of connections which I explain in very few next posts.




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Another excellent blog post Reza. There is something I spotted which may be a typo in relation to xVelocity engine compression.
“Important: If you have a column with very few unique values, then compression engine of Power BI suffers, and Power BI memory consumption will be huge…..”
I thought very few unique values is exactly what aids the compression? The IDs (surrogate keys) on a fact table will be mostly unique and this high cardinality is not a good candidate for compression…
Hi Fabian,
Thanks for your comment 🙂 You are absolutely right same as Mikhail. That was a typo. I fixed it now. less unique values is good, more is not obviously 🙂
Cheers
Reza
thank you, a lot new and valuable information, looking forward to reading more from you.
I was wondering if you can explain this….
…. Important: If you have a column with very few unique values, then compression engine of Power BI suffers, and Power BI memory consumption will be huge……
Why very few unique values causes problems for the Engine. As far as I understood, the less unique value one column has the less space we need to store it. If we have a lot of unique values in the column, then the Engine will not be happy… am I right?
Thank you, Mikhail
Hi Mikhail
Thanks for your comment. You are right. That was a mis typing issue. I changed it now thanks to your comment 🙂 it is a lot of unique values that makes the compression not effective
Cheers
Reza
Thank you Reza, keep doing what you are doing. You can’t imagine how these posts are helping us.