

I’ve talked about Data Preparation many times in conferences such as PASS Summit, BA Conference, and many other conferences. Every time I talk about this I realize how much more I need to explain this. Data Preparation tips are basic, but very important. In my opinion as someone who worked with BI systems more than 15 years, this is the most important task in building in BI system. In this post I’ll explain why data preparation is necessary and what are five basic steps you need to be aware of when building a data model with Power BI (or any other BI tools). This post is totally conceptual, and you can apply these rules on any tools.
Why Data Preparation?
All of us have seen many data models like screenshot below. Transactional databases has the nature of many tables and relationship between tables. Transactional databases are build for CRUD operations (Create, Retrieve, Update, Delete rows). Because of this single purpose, transactional databases are build in Normalized way, to reduce redundancy and increase consistency of the data. For example there should be one table for Product Category with a Key related to a Product Table, because then whenever a product category name changes there is only one record to update and all products related to that will be updated automatically because they are just using the key. There are books to read if you are interested in how database normalization works.

I’m not going to talk about how to build these databases. In fact for building a data model for BI system you need to avoid this type of modeling! This model works perfectly for transactional database (when there are systems and operators do data entry and modifications). However this model is not good for a BI system. There are several reasons for that, here are two most important reasons;
- The model is hard to understand for a Report User
- Too many tables and many relationship between tables makes a reporting query (that might use 20 of these tables at once) very slow and not efficient.
You never want to wait for hours for a report to respond. Response time of reports should be fast. You also never wants your report users (of self-service report users) to understand schema above. It is sometimes even hard for a database developer to understand how this works in first few hours! You need to make your model simpler, with few tables and relationships. Your first and the most important job as a BI developer should be transforming above schema to something like below;
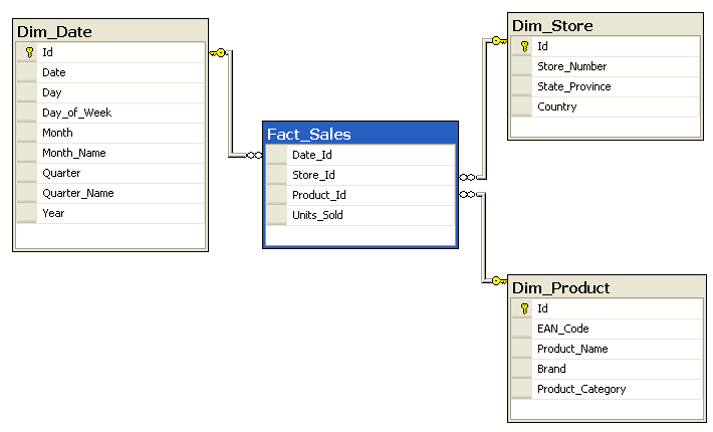
This model is far simpler and faster. There is one table that keeps sales information (Fact_Sales), and few other tables which keep descriptions (such as Product description, name, brand, and category). There is one one relationship that connects the table in the middle (Fact) to tables around (Dimensions). This is the best model to work with in a BI system. This model is called Star Schema. Building a star schema or dimensional modeling is your most important task as a BI developer.
How to Design a Star Schema?
To build a star schema for your data model I strongly suggest you to take one step at a time. What I mean by that is choosing one or few use cases and start building the model for that. For example; instead of building a data model for the whole Dynamics AX or CRM which might have more than thousands of tables, just choose Sales side of it, or Purchasing, or GL. After choosing one subject area (for example Sales), then start building the model for it considering what is required for the analysis.
Fact Table
Fact tables are tables that are holding numeric and additive data normally. For example quantity sold, or sales amount, or discount, or cost, or things like that. These values are numeric and can be aggregated. Here is an example of fact table for sales;

Dimension Table
Any descriptive information will be kept in Dimension tables. For example; customer name, customer age, customer geo information, customer contact information, customer job, customer id, and any other customer related information will be kept in a table named Customer Dimension.

each dimension table should contain a key column. this column should be numeric (integer or big integer depends on the size of dimension) which is auto increment (Identity in SQL Server terminology). This column should be unique per each row in the dimension table. This column will be primary key of this table and will be used in fact table as a relationship. This column SHOULDN’T be ID of the source system. There are several reasons for why. This column is called Surrogate Key. Here are few reasons why you need to have surrogate key:
- Codes (or IDs) in source system might be Text not Integer.
- Short Int, Int, or Big Int are best data types for surrogate key because these are values which will be used in the fact table. Because fact table is the largest table in the data set, it is important to keep it in the smallest size possible (using Int data types for dimension foreign keys is one of the main ways of doing that).
- Codes (or IDs) might be recycled.
- You might want to keep track of changes (Slowly Changing Dimension), so one ID or Code might be used for multiple rows.
- …
Surrogate key of the dimension should be used in the fact table as foreign key. Here is an example;
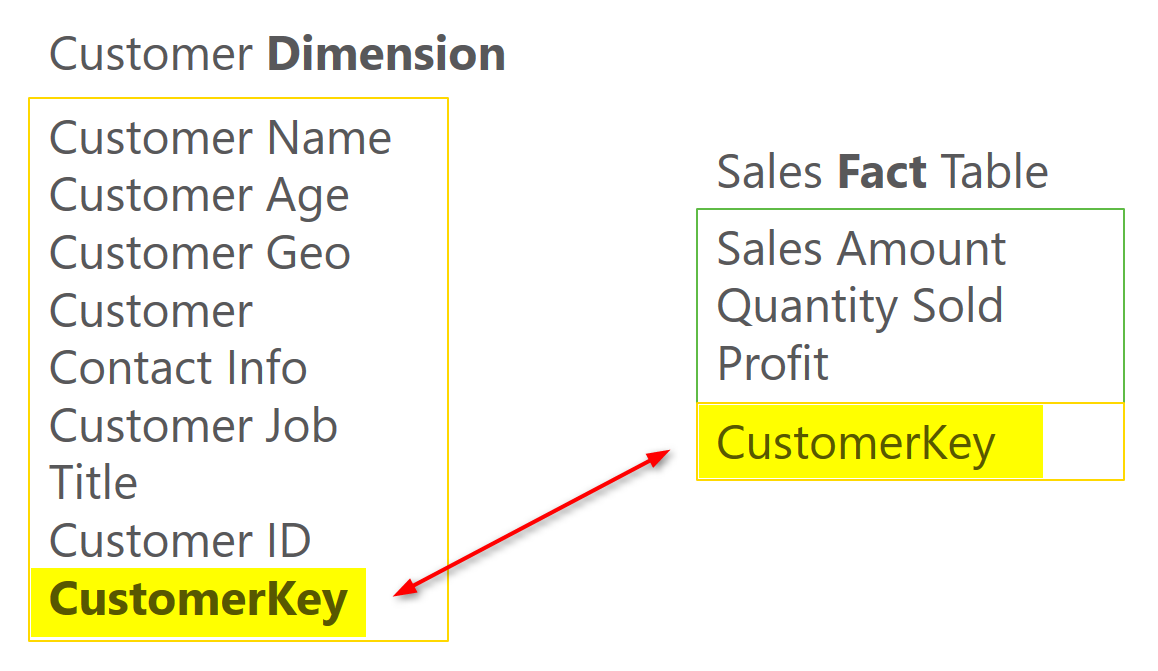
Other dimensions should be also added in the same way. in example below a Date Dimension and Product Dimension is also created. You can easily see in the screenshot below that why it is called star schema; Fact table is in the middle and all other dimensions are around with one relationship from fact table to other dimensions.
Design Tips
Building star schema or dimensional modeling is something that you have to read books about it to get it right, I will write some more blog posts and explain these principles more in details. however it would be great to leave some tips here for you to get things started towards better modeling. These tips are simple, but easy to overlook. Number of BI solutions that I have seen suffer from not obeying these rules are countless. These are rules that if you do not follow, you will be soon far away from proper data modeling, and you have to spend ten times more to build your model proper from the beginning. Here are tips:
Tip 1: DO NOT add tables/files as is
Why?
Tables can be joined together to create more flatten and simpler structure.
Solution: DO create flatten structure for tables (specially dimensions)
Tip 2: DO NOT flatten your FACT table
Why?
Fact table are the largest entities in your model. Flattening them will make them even larger!
Solution: DO create relationships to dimension tables
Tip 3: DO NOT leave naming as is
Why?
names such as std_id, or dimStudent are confusing for users.
Solution: DO set naming of your tables and columns for the end user
Tip 4: DO NOT leave data types as is
Why?
Some data types are spending memory (and CPU) like decimals. Appropriate data types are also helpful for engines such as Q&A in Power BI which are working based on the data model.
Solution: DO set proper data types based on the data in each field
Tip 5: DO NOT load the whole data if you don’t require it
Why?
Filtering part of the data before loading it into memory is cost and performance effective.
Solution: DO Filter part of the data that is not required.
More to Come
This was just a very quick introduction to data preparation with some tips. This is beginning of blog post series I will write in the future about principles of dimensional modeling and how to use them in Power BI or any other BI tools. You can definitely build a BI solution without using these concepts and principles, but your BI system will slow down and users will suffer from using it after few months, I’ll give you my word on it. Stay tuned for future posts on this subject.




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.
Completely agree with tip number 3.
Might be a bit off topic; I’m always annoyed with the decision to put ‘technical’ naming convention in Data Warehouse. But it’s so hard to argue with other BI developers because they think it’s simple, therefore it’s not that important. Whereas in reality, a good naming convention is very important for business people, especially when we want to achieve the so called “Single Source of Truth”.
Hi Leo,
Thanks for your feedback. The data warehouse naming can be still ‘technical’. However there should be views on top of that. or even in the model itself some renaming. that change those to business understand-able names.
Cheers
Reza
I agree that a star scheme is creating a lot of clarity in the model, but sometimes it just doesn’t allow you to create more complex models. So what to do when you have more than one fact tables, where there’s also relationships between various dimensions directly?
If you have designed the model in the right way, your dimensions should not be related to each other. You have to flatten dimensions. If still considering that you do need to connect two or more dimensions separately (not through the fact table), then it means you probably need another fact table too. Your data mart should be a net or mesh of star schemas. No two fact tables connected to each other, and no two dimensions connected to each other. fact-dim relationships only. And believe me, this can work for a complex and sophisticated model. The design of such a model, however, takes time.
If my data source consists of a bunch of excel files, do you recommend creating in star schema-ish model in Power BI? Are does it only apply to databases/data warehouses ?
Doesn’t matter what your data sources are (Excel, database, files, web page, SharePoint list etc). When you load it into Power BI or any other BI tools, I’d recommend a good star schema for that. you can even build it using Power Query, like this example.
Cheers
Reza
Thank you for the tips! I was intrigued about surrogate keys since I’ve been seeing them in a lot of articles. With this I realize the important of them, but I don’t see a solution how to get them, my question: if I create a surrogate key that replace the ID of the source system from a dimension table how do I relate with the fact table? Should I replace these IDs from the fact table as well?
The only solution that cross to my mind is, in Power Query editor, after creating the surrogate key, merge the fact table to the dim table with the ID source, and take the new surrogate key column, the remove the ID source column. But it doesn’t look a very efficient approacn.
Hi Giovany,
yes, your thinking is right.
the process of assigning the surrogate key is through the ETL process, using the natural key (primary key in the source system) and merges and lookups
this process sometimes can be slow. that is why I recommend it only if you really need it.
Cheers
Reza
What books do you recommend on star schema/dimensional modeling?
I have written a book on the Power BI modeling which you can get from here.
Cheers
Reza