

The Dataflow in Microsoft Fabric is an element for getting the data from the source, transforming it, and loading it into a destination. In this article and video, we will go through what Dataflow is and how it works with a simple example of it.
Video
What is Microsoft Fabric?
Microsoft Fabric is an end-to-end Saas cloud-based offering from Microsoft. If you like to have some background information about what is Microsoft Fabric and get familiar with concepts such as Data Pipeline in Data Factory and Lakehouse, here are some of my other articles which I recommend;
- What is Microsoft Fabric
- How to enable Fabric in your organization
- What is Lakehouse, and a sample Dataflow Gen2 created to load data into it.
- Getting started with Data Pipelines in Microsoft Fabric Data Factory
What is Dataflow?
For a data analytics project, there is always a data transformation component. In BI terminology, it is often called an ETL (Extract, Transform, and Load) tool or service. An ETL tool is a tool that gets data from variable sources, transforms the data to get it in the shape and format needed, and loads it into the desired destination. Microsft has had a bunch of ETL tools and services throughout the years. These include but are not limited to:
- DTS (Data Transformation Services)
- SSIS (SQL Server Integration Services)
- ADF (Azure Data Factory)
- Power Query
- And a few other options, such as writing T-SQL codes and executing them through scheduled jobs in SQL Server Agent.
Through the years, the Data Transformation engines evolved. In the past, much coding was involved, and the user interface was not the best experience. These days, most actions can be done through pre-built transformations; less coding is needed, and a hardcore developer is not needed for preliminary tasks. This enables citizen data engineers to work with these tools.
Power Query is the data transformation engine of the new generation of Microsoft Data Integration tools and services. Power Query is the data transformation engine used in Power BI. However, Power Query can be used as a standalone cloud-based data transformation service when it is used as Dataflow. Dataflow is the ETL in the cloud offered by Microsoft, which uses the Power Query engine.
To learn more about Dataflow in general, I recommend reading my article or watching the video of it here;
Dataflow Gen2
Dataflow in Microsoft Fabric has some enhancements compared to the Dataflow we used before; that is why it is named Dataflow Gen2. With the Dataflow Gen2, you can have data destinations in addition to the ADLS (Azure Data Lake Storage) and Dataverse. You can have Lakehouse, Data Warehouse, Azure SQL Database, and Azure Data Explorer (Kusto)

In addition to that, the Dataflow can be exported as a template. This template can then create a dataflow similar to this in another workspace or environment. Previously in Dataflows, you could explore a JSON metadata file. This export template is not a newer and more enhanced edition of that.
There are other additional features added in Dataflow Gen2 as well. However, this article tends to focus on the entire Dataflow experience as a getting-started guide rather than comparing it with the prior versions (we might have another article focusing on the details of the enhancements of Dataflow Gen2 separately in the future).
Example
You can create a Dataflow Gen2 from the Data Factory workload inside the Fabric portal.

Start a Dataflow Gen2.
You can import data from Excel or any other source in the Dataflow Editor.
Dataflow supports a wide range of data sources.
In my example, I get data from an Excel file in my OneDrive for Business folder. Once you select the source, you can see the tables in the Excel file and select which of them you want to get the data from.
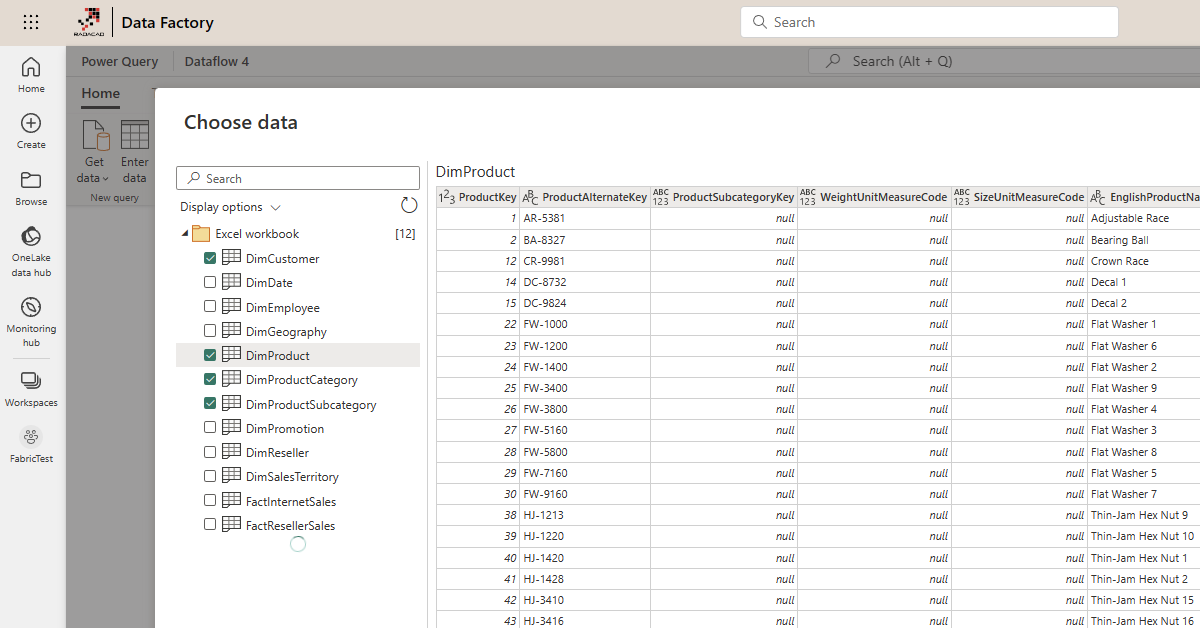
Then you will be navigated to the Dataflow Editor. Dataflow’s Power Query Editor is an online experience where you can apply data transformations using the graphical interface (1) and see a data preview after the transformation applies (2). The applied transformation steps (3) will be part of the Dataflow and will be saved as part of the solution. You can have multiple transformation queries within one Dataflow (4).
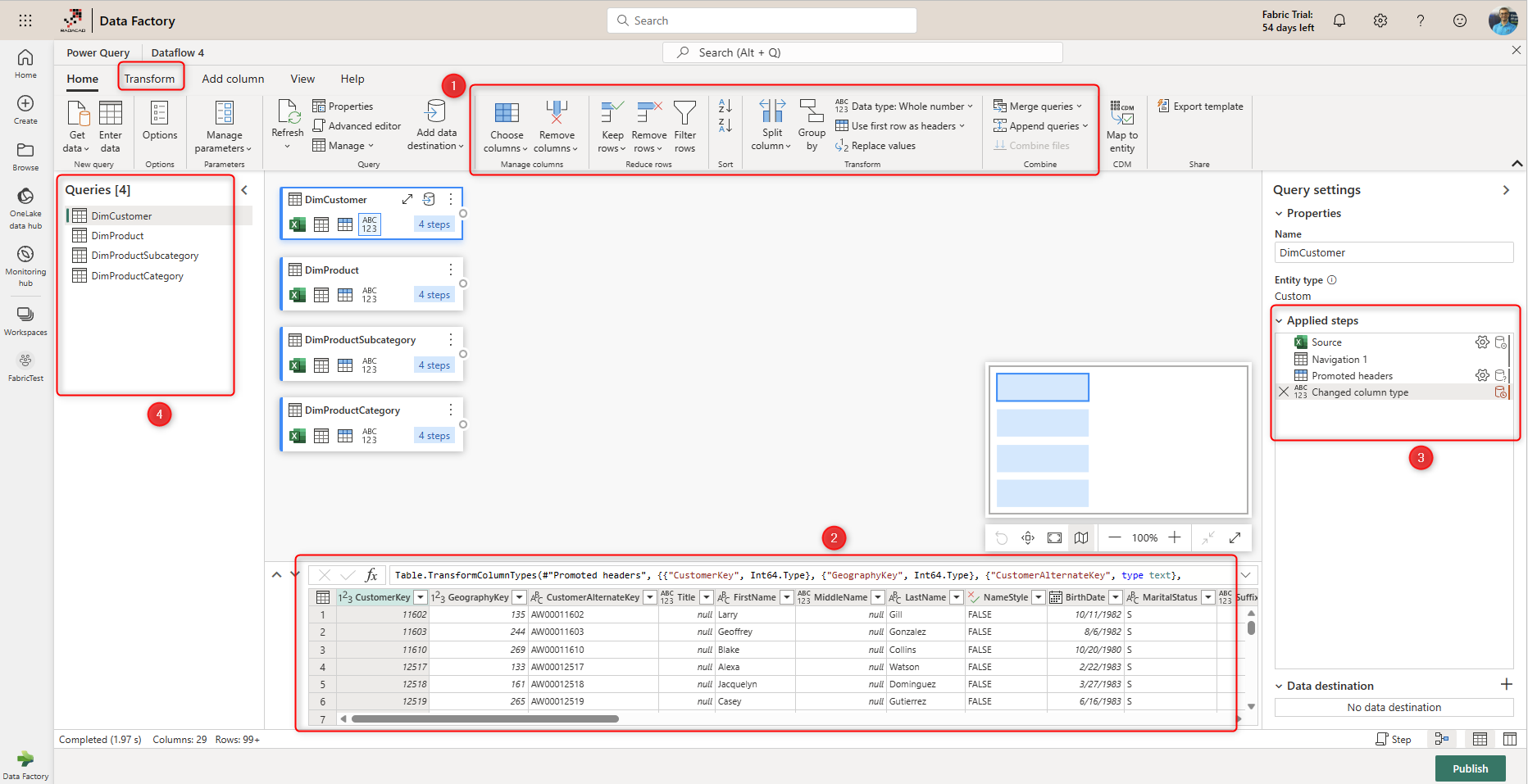
For example, using Merge, you can combine the three tables DimProduct, DimProductCategory, and DimProductSubcategory. I have explained the Merge operation in Power Query in more detail in this article. This can be done by clicking on DimProduct’s more options, then Merge queries as new.
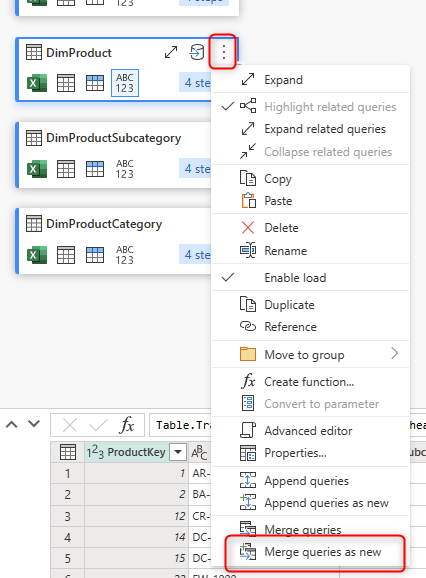
Then merge it with DimProductSubcategory by clicking on the ProductSubcategoryKey column on both tables.
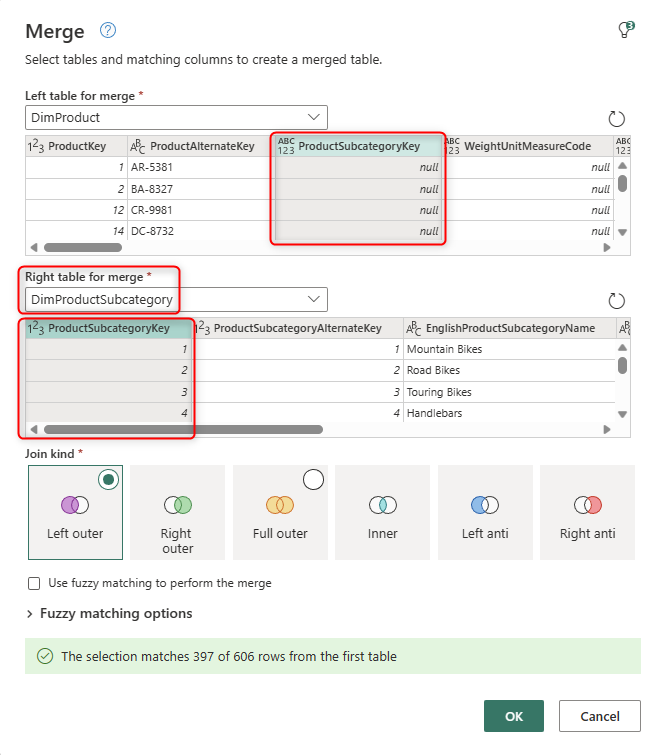
This will lead to a merged result like the one below;
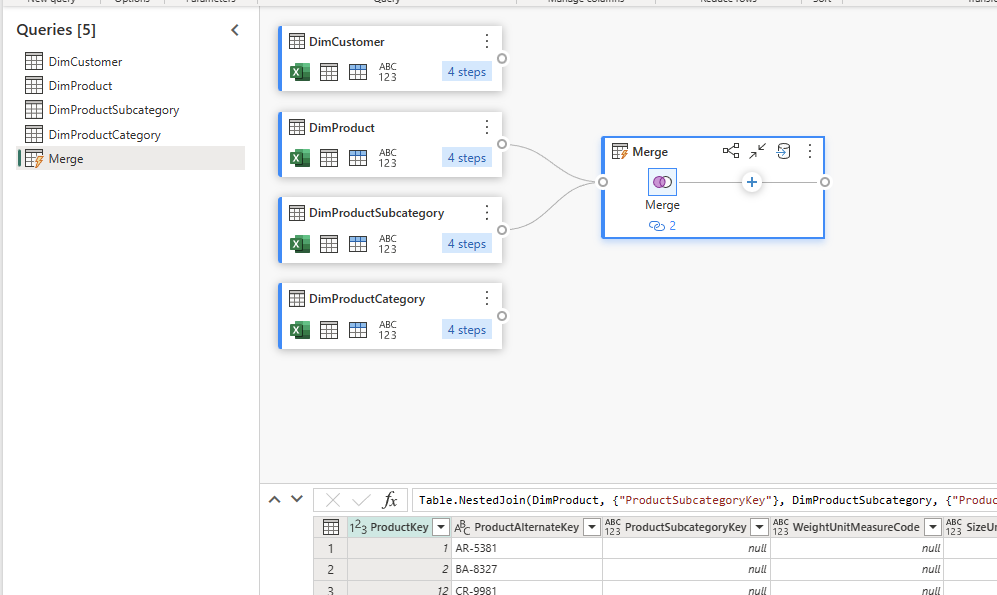
The result of the merge can then be expanded to include the columns from the DimProductSubcategroy table. This can be done by going to the last column of the merged table and expanding it.
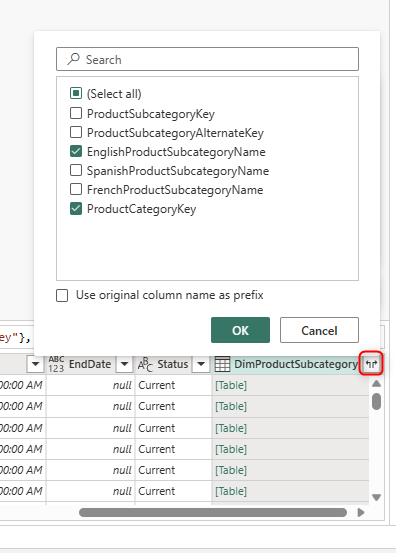
The same Merge process can be done using the DimProductCategory table and the ProductCategoryKey column. The result after cleaning up extra columns will look like the below;
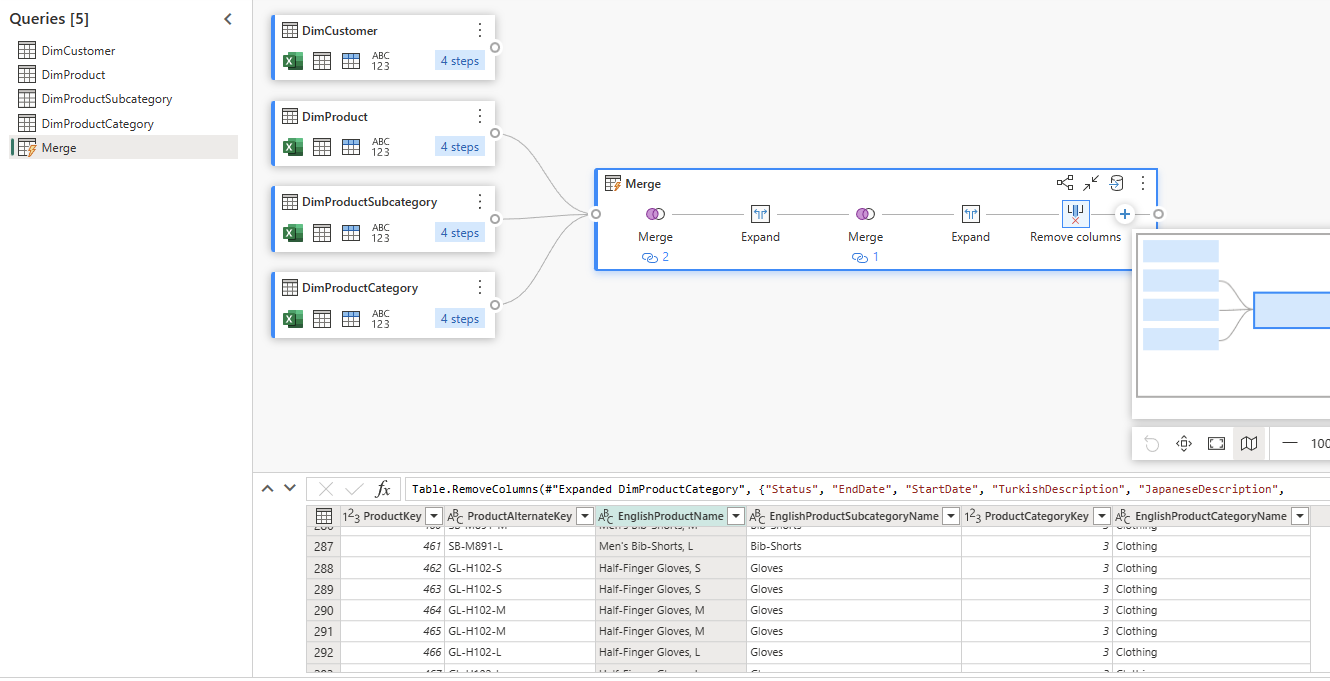
The Merged result is the Product table we need, and we can then disable the load of DimProduct, DimProductSubcategory, and DimProductCategory. This way, we created a flattened product table. I have explained this method in more detail in my article here.
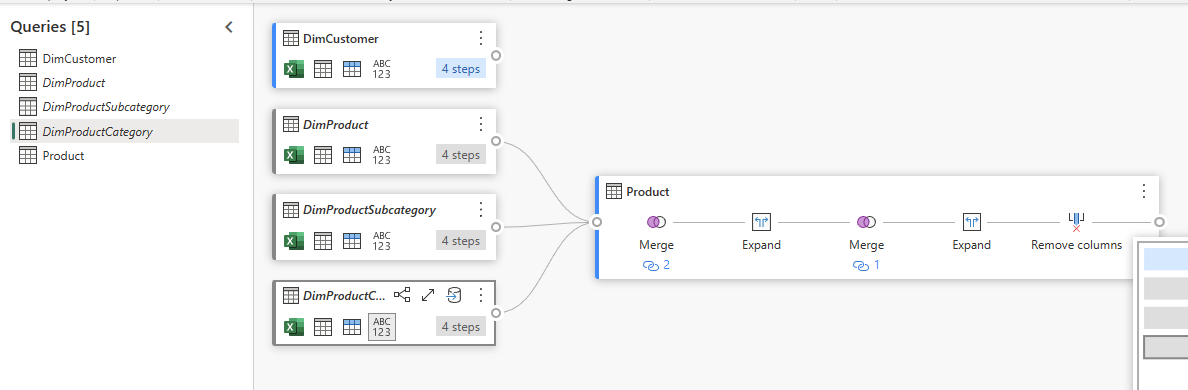
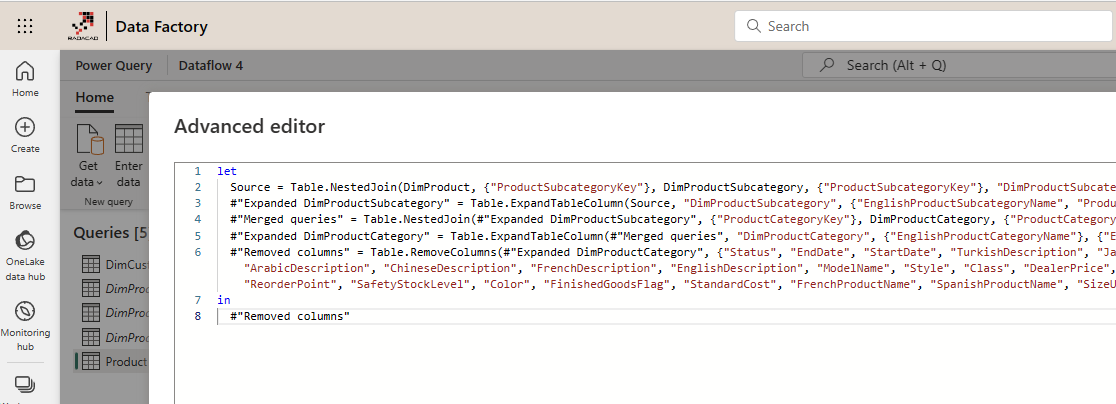
As the example above shows, the Dataflow provides the graphical interface to apply joins between tables. You don’t need to write any lines of code; it will do everything behind the scenes for you. If you want to see what the code looks like, you can go to the advanced editor.
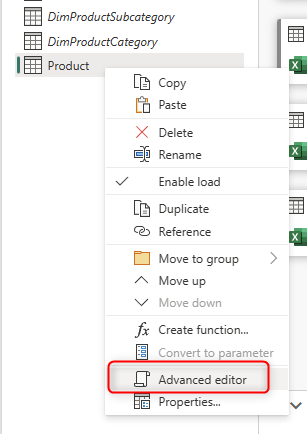
This will bring the scripting editor of the Power Query. Every transformation converts to lines of code here. The scripting language here is called M. I have explained the basics of M language here and how it differs from a language like DAX. If you ever need to apply some changes here, you can apply so easily in this editor.
Power Query has many more transformations you can apply to any data to get it to the shape you want.

After building your transformations and ensuring the outcome is what you need, then you can define the data destination. The data destination is where the data will be stored. The data will be stored in Azure Data Lake Storage Gen2 behind the scene by default. However, you can connect it to other destinations if you want.
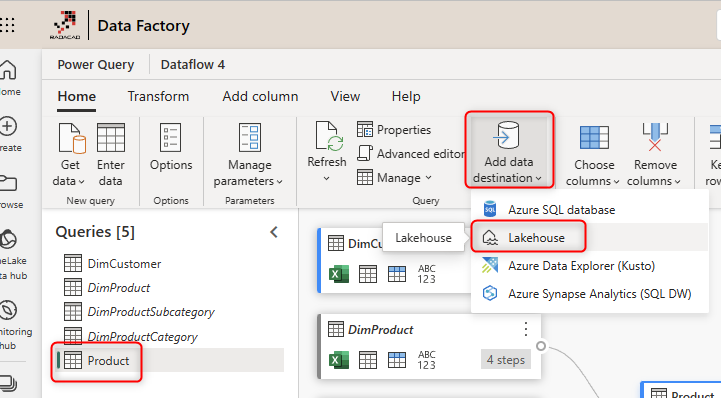
For my example, I use Lakehouse. I have explained how to create a Lakehouse in my other article here. You can also choose the method by which you want the data to be updated. The Replace means deleting whatever exists in the destination table and re-loading it, whereas Append means appending this data to the existing data of the table.

After setting the destinations for all queries, then you can publish. After the successful publish, you can run the dataflow so that it performs the get data > transformation > load into the destination.

You can also schedule the refresh of the Dataflow.
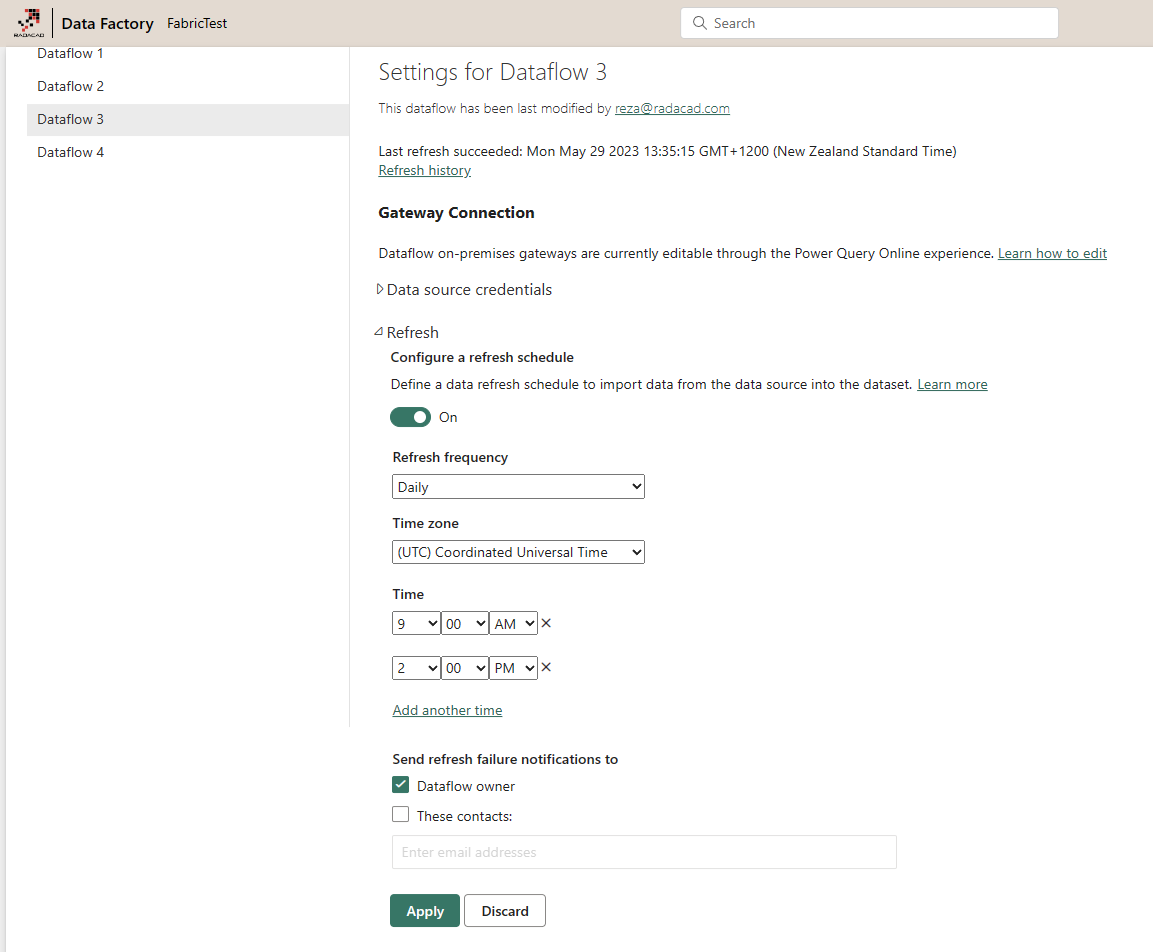
The execution history of the Dataflow can be seen on the settings page of it.

And the Dataflow can be embedded inside a Data Factory Pipeline so that you can execute it with some other control flow elements, such as sending an email on completion or looping until a specific condition is met, etc. Learn more about how to run a Dataflow inside a Data Pipeline in my article here;
Summary
Dataflow is the data transformation engine of Microsoft Fabric. Dataflow uses the Power Query engine to get, transform, and load the data into destinations. A Dataflow building environment is a user-friendly environment that does not need a hardcore data engineer to work with it. However, it is powerful enough for complex transformations. Dataflow can be embedded inside a Data Pipeline to run as one of the tasks of a bigger control flow execution.
To learn more, I recommend reading these related articles;
- What is Microsoft Fabric
- How to enable Fabric in your organization
- What is Lakehouse, and a sample Dataflow Gen2 created to load data into it.
- Getting started with Data Pipelines in Microsoft Fabric Data Factory




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.