


The main aim of machine learning is to learn from past data that able us to predict the future and upcoming data.
It is so important that chosen algorithm able to mimic the actual behaviour of data. in the all different machine learning algorithms, there is away to enhance the prediction by better learning from data behaviour.
However, in the most machine learning experiences, we will face two risks :Over fitting and under fitting.
I will explain these two concepts via an example below.
imagine that we have collected information about the number of coffees that have been purchased in a café from 8am to 5pm.
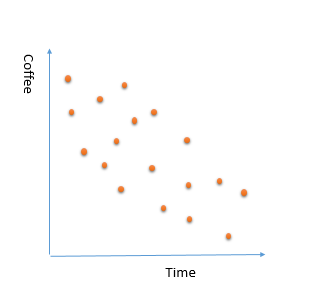
we spotted below chart
we what to employ a machine learning algorithm that learn from the current purchased data to predict what is the coffee consumption during a working day. This will help us to have a better prediction on how much coffee we will sell in each hour for other days.
For learning from past data there is three main ways .
1- Considering all purchased data. for instance:
12 cups at 8am
10 cups at 10am
5 cups at 10.30 am
10 cups in 13 pm
5 cups in 13.20 pm
3 cups in 13.40 pm
5 cups in 14 pm ?
you see the number of the selling coffee change and fluctuate, so if we consider all the coffee purchased points, it is very hard to find a pattern and we have lots of “if and else” condition that makes learning process hard. for example, number of purchased coffee dropped suddenly at 8.30 am, which is not that much make sense. Because , in the morning people are more in coffee. As a result, by considering all the points,we are going to have some noises in data. This approach, will be have bad impact on the learning process. and we not able to come up with a good training data.
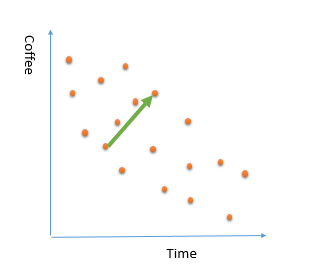
2- Considering a small portion of data. Sometimes we just consider a small portion of data that not able to explain all the data behaviour. Imagine that in the above example , we just look at the coffee consumption from 11am to 2pm. as you can see in the below picture, there is a increase in the coffee consumption. It this trend apply to other times? is it correct to say for future days, number of purchased coffee will be increase by time of the day ? absolutely not (at least our data not showing this)
this is an example of biased that we just consider a sample portion of data for explaining or learning from data. another name for this behaviour is “under fitting”. this behaviour also lead to a poor prediction.
3- so in reality, in our data set there is a decrease in consumption of coffee during day. a good prediction model will find below trend in data. not small portion that just focused on specific data point not all data that make lots of noises.
each algorithms provides some approach to avoid these two risks.
to see how to avoid over fitting or under fitting in the KNN algorithm, check the Post for k nearest neighbour, selection of variable “k” (number of neighbour).



