

If you want to use Power BI, Microsoft Fabric, or any other data analytics tools, one of the key concepts to understand when working with a data warehouse system is the SCD (Slowly Changing Dimension). I will do this in a series of at least two articles. The first one (this one) will be on the concept of what SCD is, its meaning, and its different types. Then, the next one will discuss how to implement SCD types (such as Type 2) using Microsoft Fabric and Power BI.
Video
Dimension attributes change
A dimension table is a descriptive table whose attributes (columns) will be used as the axis of charts and visuals in filters and slicers. For example, a Customer table in a sales data warehouse can be a dimension table.
It is possible that the values of some of the existing records of dimension columns (also called attributes) change. For example, you may have a customer who was based in New York City for a while but has now moved to London. The City column’s value for this customer needs to change. On the other hand, you may have a customer whose name has changed, and the value of that also needs updating.
SCD: Slowly Changing Dimension
SCD Stands for Slowly Changing Dimension. It is when the value of an attribute (column) in a dimension member (row) changes, and then the behavior you take and implement to support that change is the Type of SCD.
For example, You may say the Customer ID column cannot change (Type 0), or the name changes and we just need the most current value of it (Type 1), or the city changes, but we need to preserve the previous values (Type 2 to 7)
Here are some of the most common types of SCD;
- Type 0: retain original
- Type 1: update value in place
- Type 2: preserve history (UPSERT)
- Type 3: keep only the previous value
- Type 4: history and current values in separate tables
- Type 5: 4+1
- Type 6: 1+2+3
- Type 7: easier link between fact and dimension tables
- …
Let’s dig into some of the most common types from the list above.
SCD Type 0: Change is not accepted
For example, if the Customer ID changes, you may not accept it. You may say that the Customer ID in the source system never changes; if it changes, there is a problem in the source system that needs investigating. So you won’t accept the change. This is SCD Type 0.
SCD Type 0 means no change is accepted. You will not update the original value, which means no action is needed in your ETL process. This is the simplest SCD Type to implement—you don’t have to do anything!

SCD Type 1: Update the original
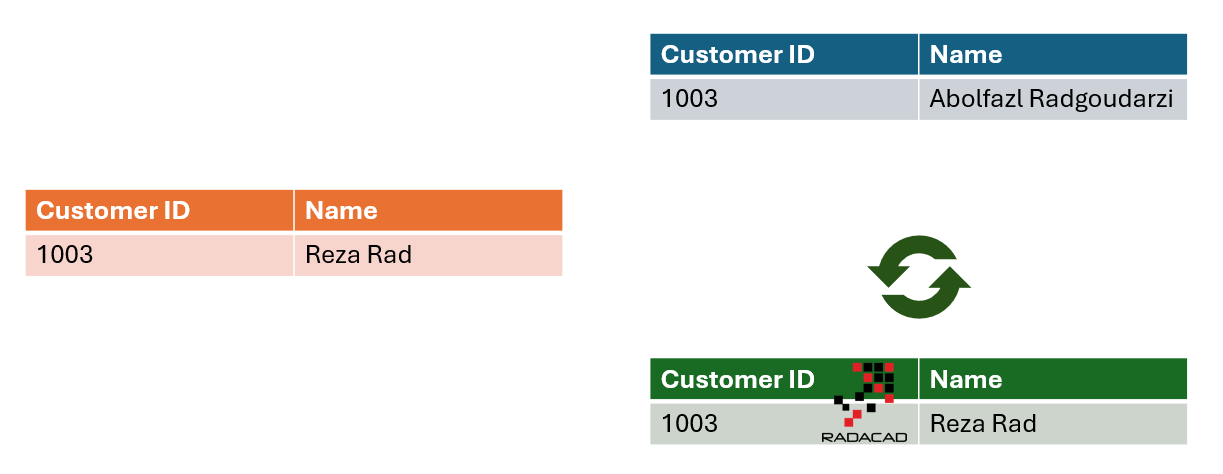
In another scenario, you may accept the change. Let’s assume that the customer’s name changes. In your system, the customer’s previous name isn’t important for data analysis. You just care for the current, most up-to-date name of the customer. In a case like that, you just update the value. This is SCD Type 1.
The ETL process for this would be a simple UPDATE of the current record’s value in that attribute. It can also be a DELETE of the existing record and INSERT of the new one. This is also a simple ETL process. Most ETL tools either automatically delete the entire dimension table and load it again (for example, when you use the Replace option in Dataflow Gen2 in Fabric), or it can be a simple UPDATE command using SQL.
SCD Type 2: Keep the entire history
In some scenarios, you accept the change, but you also want to keep the previous values. For example, if the customer in a sales system was based in New York City and was purchasing from a NYC branch, now is moved to London. In a case like this, you may want to preserve the history because the customer purchases in NYC should not be counted as London’s branch purchases. In a case like this, you will keep the current value, make it historical with effective date values, and then add a new value as another record. This is SCD Type 2.
The dimension table structure for SCD Type 2 needs to be changed. You must use the Surrogate Key (the primary key of the dimension table, which is different from the primary key of the source system), and you also need two extra columns: FromDate and ToDate.
The ETL process will update the ToDate of the current (now the old one) record, and then inserts a new record with the FromDate as of today (the date of ETL process execution), and the ToDate to be null (blank). This UPDATE and INSERT process is also called UPSERT.

SCD Type 2 and Type 1 are the two most common types of SCD in a data warehouse implementation.
SCD Type 3: Keep a limited history
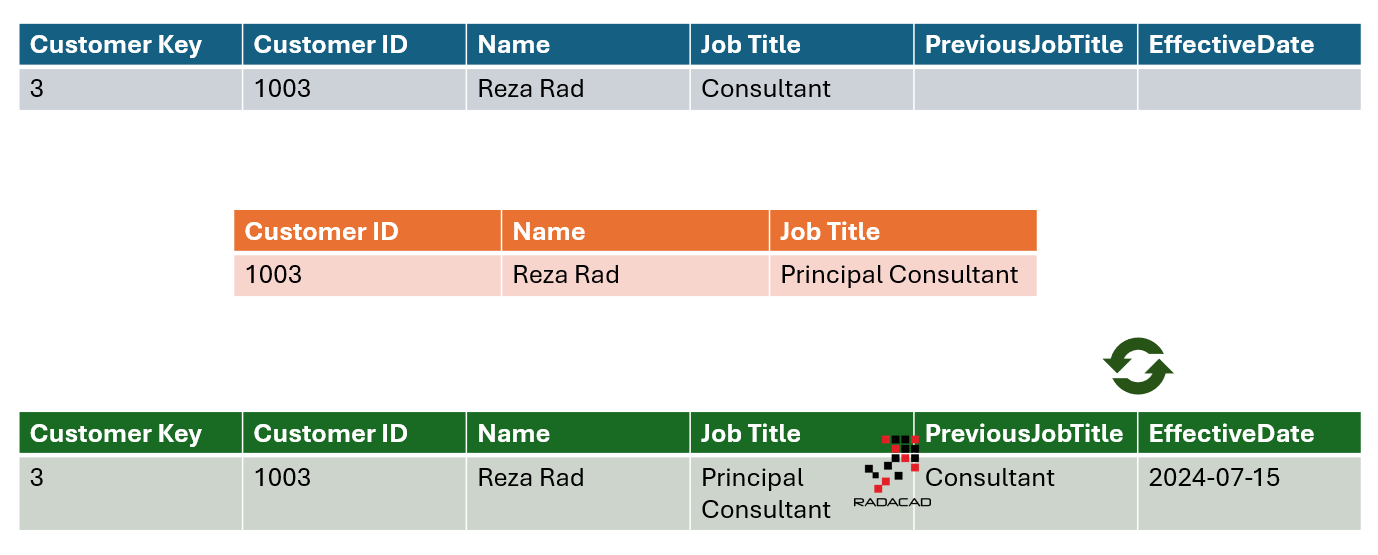
Sometimes, you may want to keep the history but only a limited set of changes. For example, you are only interested in the customer’s current and previous job titles. All previous value changes are not helpful for your analysis system. This is SCD Type 3.
Type 3 is implemented by adding two columns for each attribute that supports this type of change: A column for the previous value and a column for the effective date of the last value.
The ETL process for Type 3 will update the record, setting the previous value as the current value, updating the effective date column, and then setting the current value as the new value.
SCD Type 4: Type 2, with a cleaner dimension table
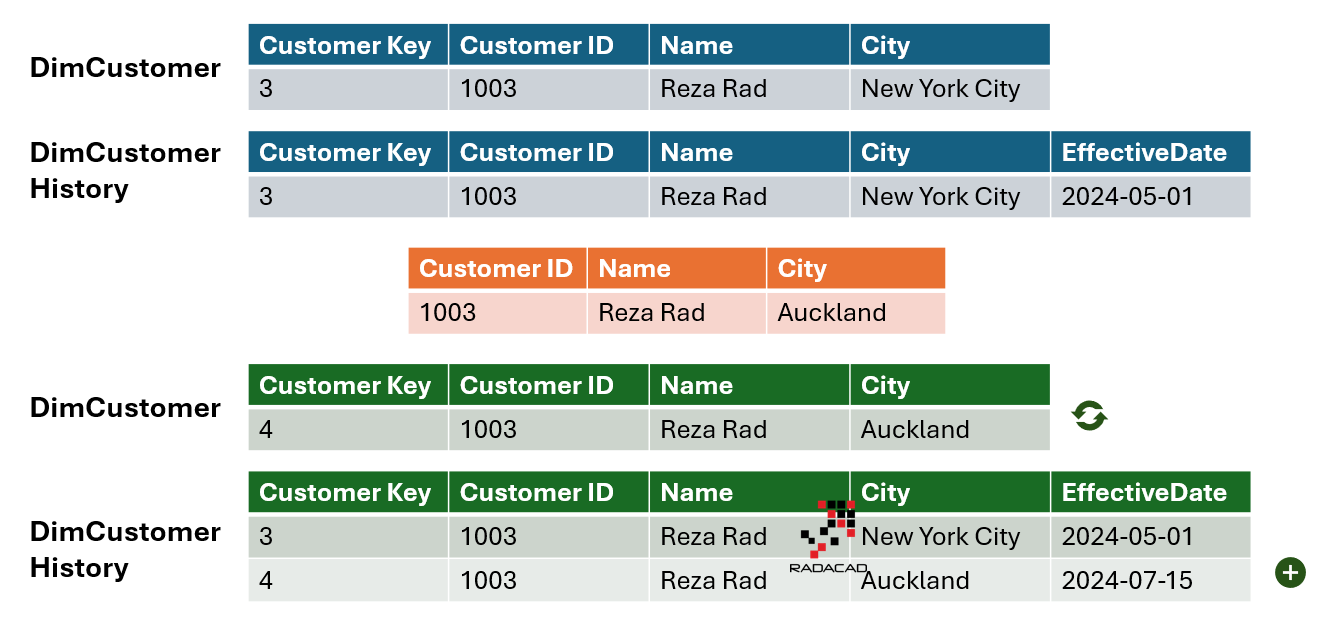
SCD Type 2 will keep all the records in the dimension table, including the current and historical records. The dimension table gets messy after a while. An improvement to Type 2 is when you keep historical records in another table, and the dimension table only keeps the current values. This is called SCD Type 4 (one of my personal favorites when implementing).
In this case, only the historical table needs the date column, but only one column can suffice. You would not need FromDate and ToDate; you will just need an EffectiveDate (you can keep both date columns if you want).
The ETL process will add a new record in the historical table with the effective date and the current value (which is now historical) and then update the record in the dimension table with the new value.
Although Type 4 is a much cleaner version of Type 2, it is not commonly used because of the complexity of working with two tables in the ETL process. One good way of implementing it is using SQL Server Temporal Tables, which I explained in this article nine years ago!
Not so-popular SCD Types
The other three types of SCD are not very popular because of their complexity of implementation and the special use cases they support. They are normally combined versions of the previous types. For example, Type 6 is a combined version of Types 1, 2, and 3. Or they are built to simplify part of the process. For example, Type 7 is built to simplify the connection between the fact table and dimension table, which can be complicated in other types of SCD that support keeping historical values.
Here is a short definition of them just for a reference;
- Type 5: Combine Type 4 and Type 1
- Type 6: Types 1+2+3
- Type 7: Save both the Surrogate Key and Natural Key in the Fact Table
The most common types of SCD
SCD Type 1 is very common; you may already be doing it without noticing it! When your dimension’s table’s data is deleted in each ETL process and refilled, you are doing SCD Type 1. It is as simple as that or just a simple update command in SQL.
SCD Type 2 is the other most common type. Keeping the historical value for some of the attributes is essential in some systems, and Type 2 is the most simple (but still with some complexity) way of doing it compared to other types.
In the next article, I’ll explain how you can implement SCD Type 2 using Microsoft Fabric and Power BI.
Summary
SCD, or Slowly Changing Dimension, is the behavior you take when an attribute of the dimension member changes. Depending on how you handle the change, there are different types of SCD. The most common types are Type 1 and Type 2. However, Type 4 is also used in some systems. You may occasionally see Type 6 and other types used, but their ETL process will be most complex.
In the next article, I’ll explain how you can implement SCD Type 2 using Microsoft Fabric and Power BI.
Here are some useful information as extra reading related to this article;
- What is a Dimension Table
- What is a Data Warehouse in Microsoft Fabric
- What is Microsoft Fabric
- SCD Type 4 implementation using Temporal Tables in SQL Server
- Dataflow Gen2 in Microsoft Fabric




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.