

I have previously explained a number of use cases for dataflows. One really useful case for it is to use dataflow for slow data sources. In this short article and video, I’ll explain how this works.
What is a dataflow?
Dataflow is a Power Query process that runs in the cloud and stores the result of the transformation into storage. I have explained about dataflow previously:
Slow data source
Some data sources are working very slow. Sometimes it is the problem with the data source engine. sometimes, it might be the connector issue, sometimes it might be a limitation on the data source (such as the number of API calls in a time period). All of these situations cause the refresh of the Power BI report to become really slow because it has to wait for the data source’s response.
No matter what caused the data source to be slow (the old technology, performance issues, slow connector, limitations, etc), it will cause the data refresh of the Power BI dataset to become slow. Even if you have an incremental refresh setup, it might not still help much, because sometimes the query folding doesn’t happen. Slow refresh time will not only be bad for the service, but it will be also bad for the developer who has to wait a long time for the data to be available after each refresh.
Dataflow as an intermediate storage
You can use dataflow as an intermediate storage for the slow data source. Even if no transformations is needed, it can help to move the slow refresh to the dataflow side.
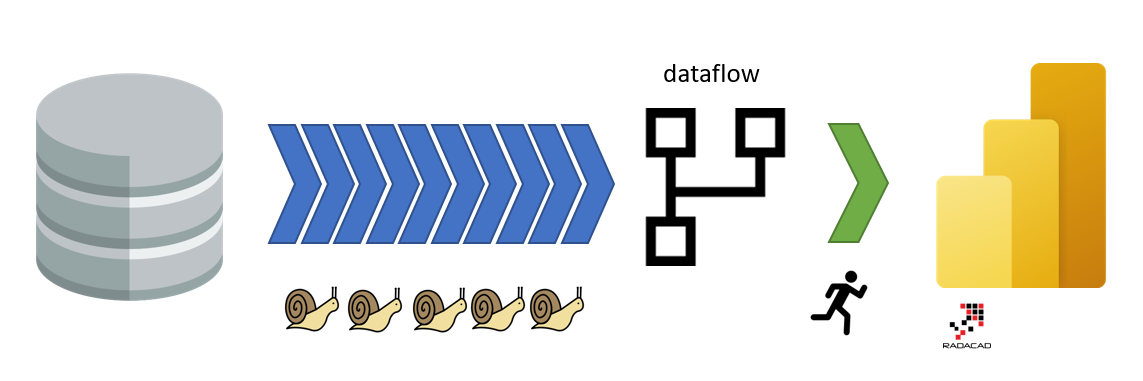
This will not make the refresh of dataflow fast, but because Power BI will be using dataflow as a data source, the Power BI refresh time would be faster. Even if the dataflow is just ingesting the data from the data source and not doing any transformations, still this method will be helpful from the Power BI side. This is a method I also explained here:
In fact, you are not making the whole process faster. However, from Power BI side, this will be much faster, because the slow data source is now separated from the rest of the solution.
Video




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.