

The structure of storing data in OneLake for the Lakehouse tables is interesting. The commonly used structure is called the Delta Lake Table structure. In this article and video, you will learn what this structure is, how it works, and what the difference is with Parquet, and you will see some related demos.
Video
What is Delta Lake?
Please don’t get lost in the terminology pit regarding analytics. You have probably heard of Lake Structure, Data Lake, Lakehouse, Delta Tables, and Delta Lake. They all sound the same! Of course, I am not here to talk about all of them; I am here to explain what Delta Lake is.
Delta Lake is an open-source standard for Apache Spark workloads (and a few others). It is not specific to Microsoft; other vendors are using it, too. This open-source standard format stores table data in a way that can be beneficial for many purposes.
In other words, when you create a table in a Lakehouse in Fabric, the underlying structure of files and folders for that table is stored in a structure (or we can call it format) called Delta Lake.
As mentioned, Delta Lake is not a Microsoft-specific technology. It is used to build a Lakehouse architecture that uses compute engines such as Spark, PrestoDB, Flink, Trino, and Hive. Microsoft’s compute engine is based on Spark, so Microsoft decided to use this storage framework with the Lakehouse.
This link gives you more general information about Delta Lake.
Benefits of Delta Lake

The specific way that the data is stored in the Delta Lake framework is beneficial for many reasons. Here are a few;
- ACID transactions
- Time travel
- Audit history
- Updates on the data
- and many others
Let’s see what the above means;
ACID transactions
ACID stands for Atomicity, Consistency, Isolation, and Durability. Supporting ACID transactions means that the Lakehouse table (which is stored in Delta Lake format) supports concurrency and guarantees the validity of the data across transactions that read and write data from and to the table.
Audit history
A log of any actions taken on the table will be kept, which can be retrieved anytime needed with full details of changes.
Time travel
The Delta Lake format in which the data is stored supports the ability to query data as a snapshot back in time. For example, we can see what the customer record looked like on April 15, 2000.
Updates on the data
Various languages and commands can be used to Update and Delete (or Upsert) the data and perform actions such as Slowly Changing Dimension (SCD), Inferred Dimension Member, etc, based on the requirements.
Of course, Delta Lake offers many more benefits, but only a few of the above show how effective and efficient it is in a data storage structure like Lakehouse.
Delta Lake Table Structure in Microsoft Fabric
Each table is stored in a format like the one below;
- Table Name
- _detla_log
- 00000.json
- 00001.json
- …
- xyz.parquet
- xyw.parquet
- …
- _detla_log
The folder includes everything needed for that table. Underneath that will be Parquet files for storing the actual data and a _delta_log folder that holds all the log entries in JSON format. The JSON files keep a log of all changes in Parquet files.
Here is what a table’s data looks like in OneLake. (I used OneLake File Explorer for Windows to see this. It is an awesome add-on to install on your machine. It is free, and once installed, it makes OneLake really look like OneDrive for you.)
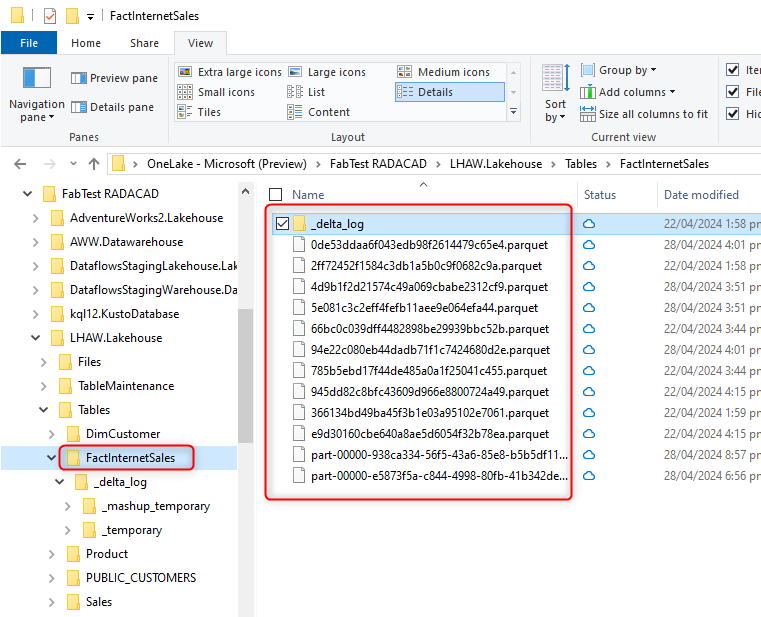
As you see, the FactInternetSales is a table in the Lakehouse. It has all the data in a folder with its name, and under that, we have parquet files plus the _delta_log folder. The _delta_log folder’s content looks like the below;
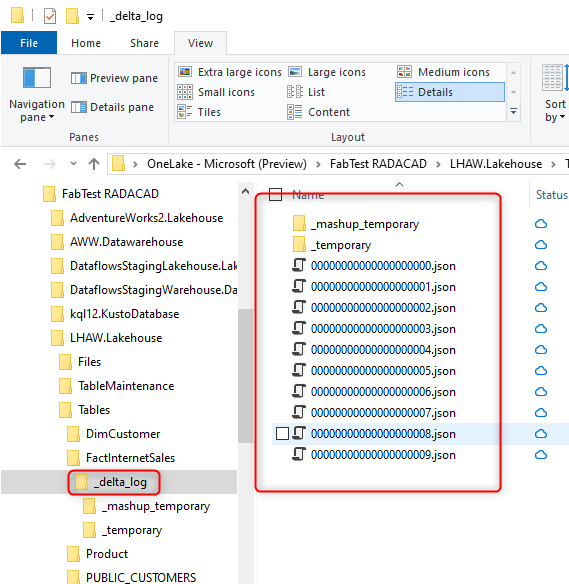
I used OneLake file explorer for Windows to see the above structure.
You can also use Lakehouse Explorer and the View files option to see the Delta Lake structure of Lakehouse tables.
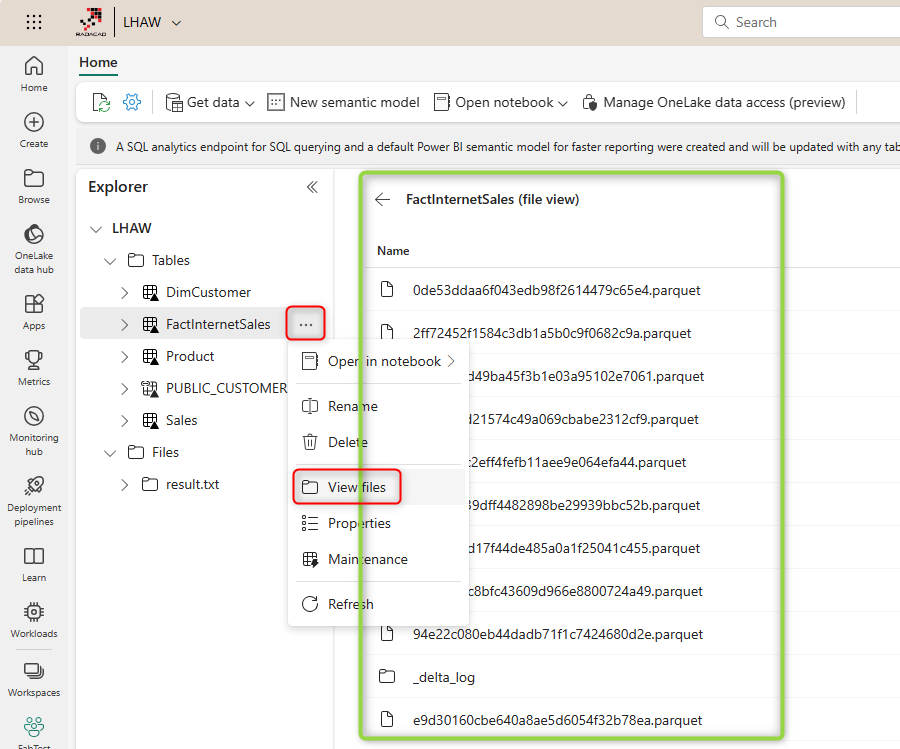
Delta Lake VS. Parquet
What is Parquet, and is it the same as Delta Lake? How different they are? Let’s talk about that in this section.
Parquet is a file format for storing data. It is an open-standard format, like CSV. However, CSV files are more human-readable; you can open them and read them in Notepad or Excel. Parquet files are not readable like that, but systems such as Spark can read them.
Parquet files store data in columnar storage format, which makes them really efficient in reducing file size and perfect for analytics. Querying the data from a Parquet file will be extremely faster than reading it from a structure like CSV. So, it is a file format that stores data much more efficiently and reads data from it much faster. What can be better than that?
Microsoft Fabric stores data using the Parquet file structure. However, that doesn’t mean Parquet is similar to Delta Lake or that Parquet and Delta Lake are replaceable.
Delta Lake is the structure in which the table’s data is stored. It includes folders and files underneath. One of those file types is Parquet. That is where the actual data is stored. So, Parquet is part of the Delta Lake structure. Together, they will give a table structure that is not only perfect for transactional actions such as a database table (Delta Lake benefit) but also super-fast for analytics (Parquet benefit).
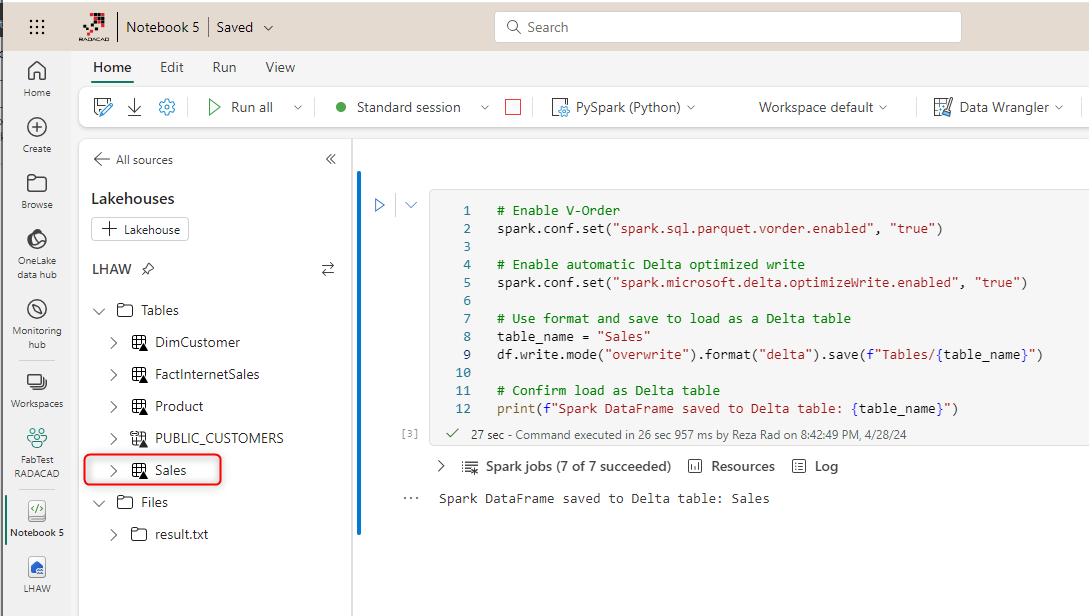
Creating Delta Lake table
There are two main ways you can create a Delta Lake table. The main one is by creating the table in Lakehouse, any table will be automatically having the Delta Lake structure.
The second approach is creating it using a script like the one below. The script is a Python code run through a Notebook;
df=spark.read.csv("path for csv file")
table_name = "Sales" df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
Updates on the data
To understand how the changes work in the Delta Lake tables, let’s go through an example of updating the data. I have a FactInternetSales table to which I want to apply the update code below (the update SQL code is running using a Notebook)
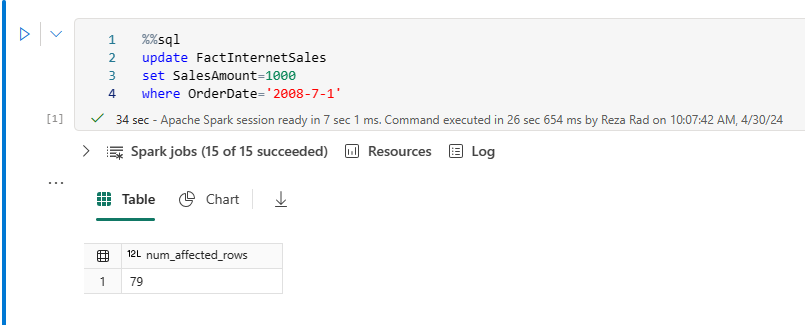
The code above updated 79 records from the FactInternetSales table. Now, if I go and check out the files, I can see that some changes happened in Parquet files;
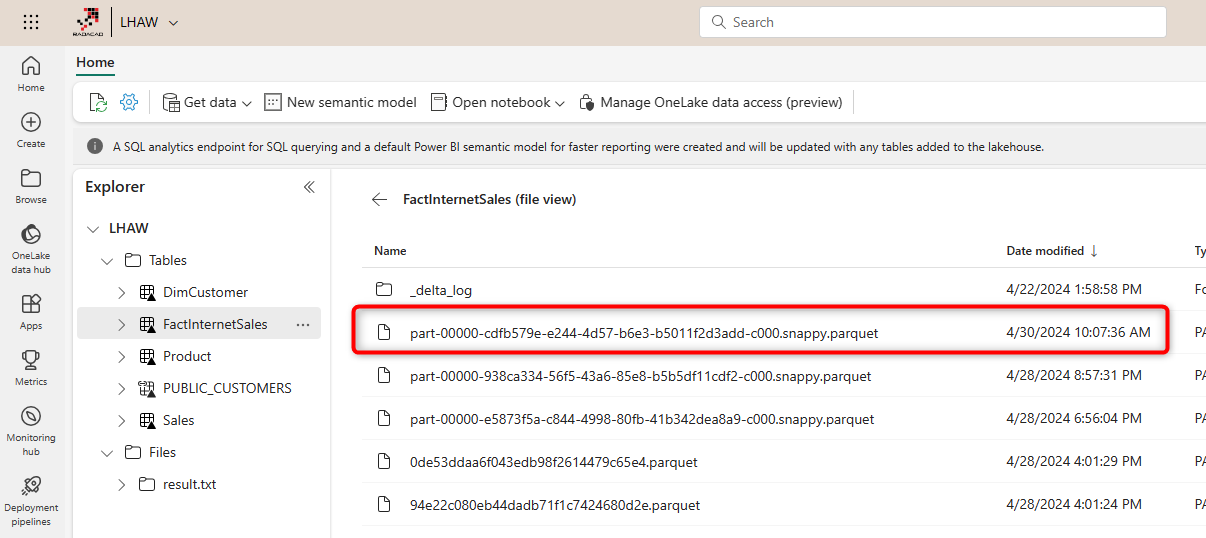
And also, under the _detal_log folder,
I have a new JSON file;
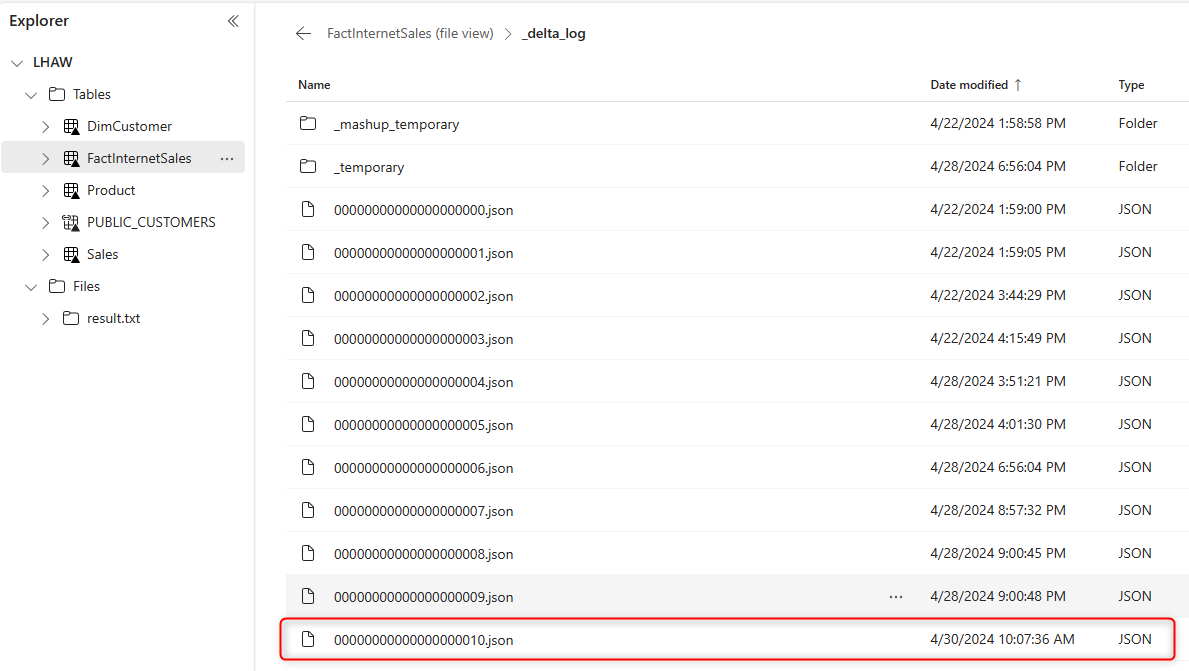
The JSON files will have a detailed log of the change and how the Parquet file relates to that.
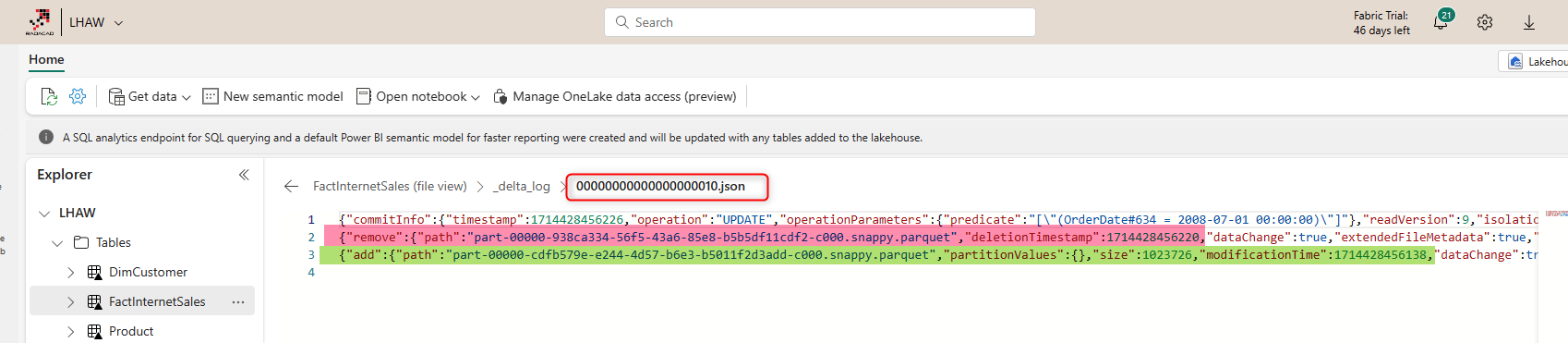
As you can see in the JSON file, there are details about which Parquet file is not in use anymore, which one should be used from now on, the dates of change, etc. These detailed logs are making it super helpful for audit reporting.
Checking the changes in history
I can use the DESCRIBE command in a Notebook to get the history of changes on a table as easily as below;
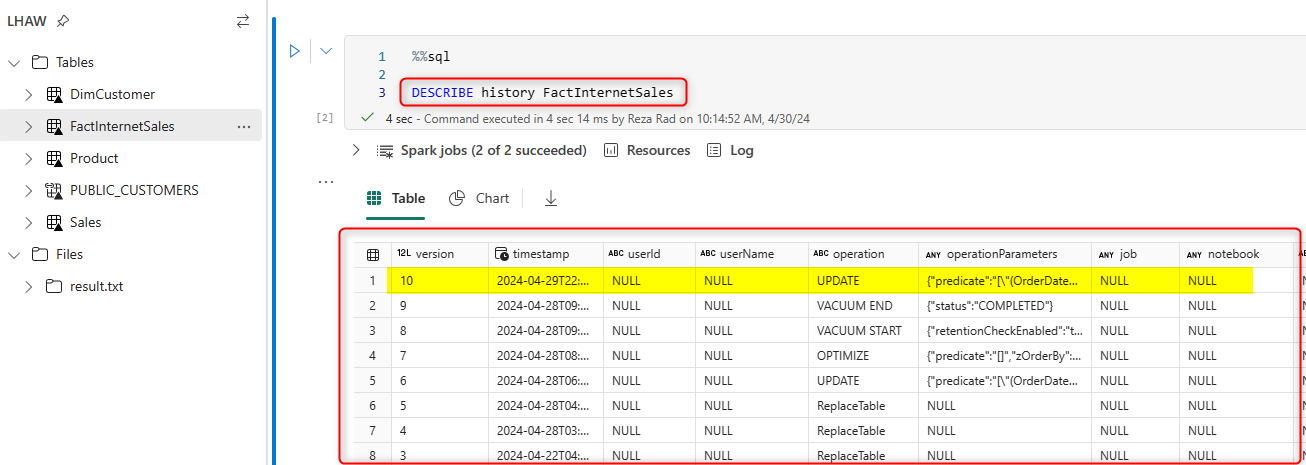
Time Travel
I can also use a query like the one below to get the data as a snapshot at a desired time.
df_old_table = spark.read.format("delta").option("timestampAsOf", '2024-04-28').load("Tables/FactInternetSales")The code above gives me a copy of the FactInternetSales table exactly as it was on the 28th of April before my change happened. I can compare it with my new data like the below;
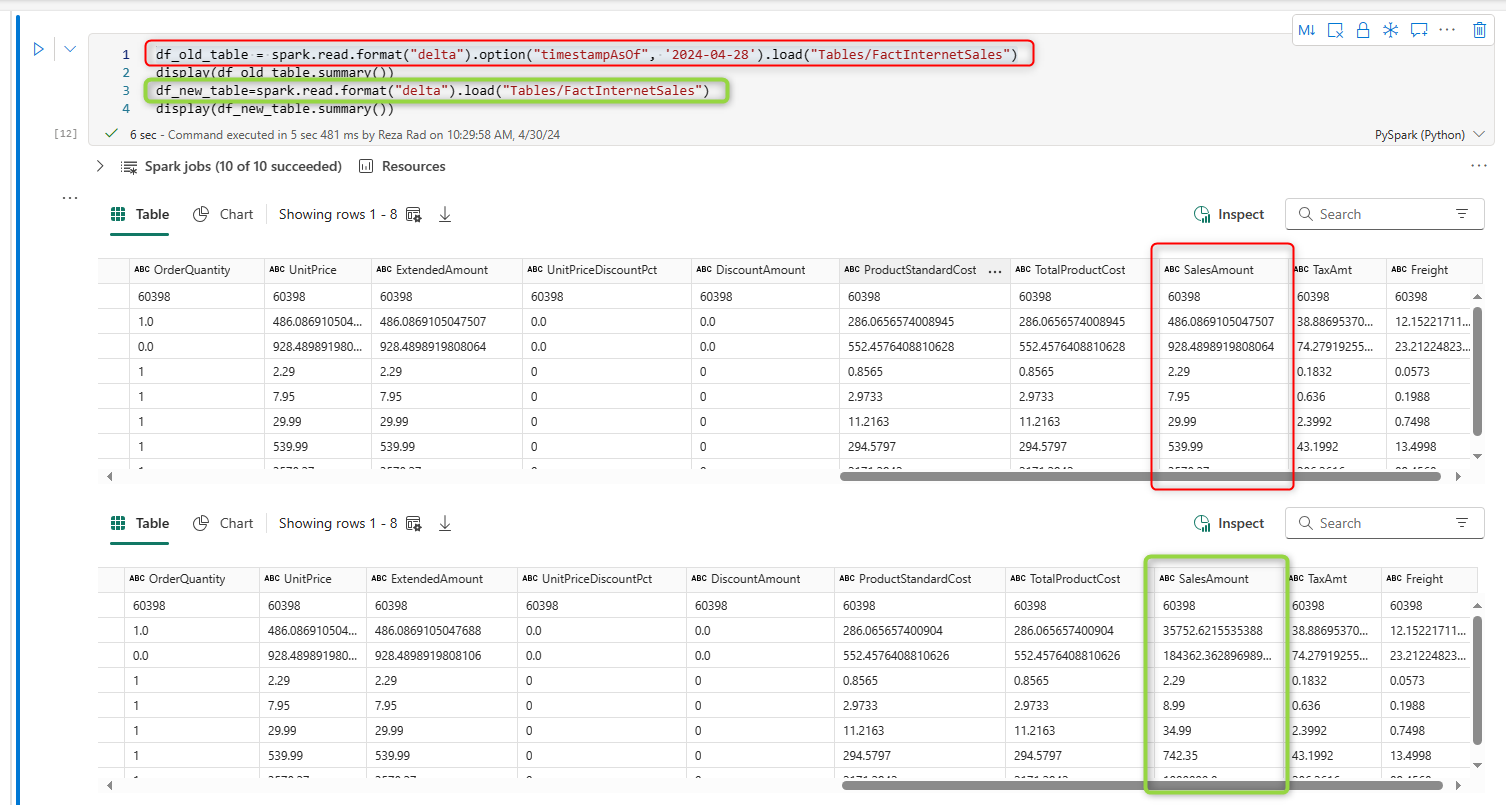
You can see that the data of the past and the new are different. Using the Delta Lake table structure, I can do time travel just like that. The code above is a Python code run from Notebook.
Optimization
It might occur to you that what about the performance? If many changes (updates and deletes) happen on the Lakehouse table, we would have lots of log files, parquet files, etc.
That is a good thinking, of course. The good news is that there are optimization techniques that can be used to vaccum the un-necessary files, and optimize the structure, commands such as OPTIMIZE, VACCUM combined with optimization techniques such as V-Order and Z-Order are there to help in these situations. They are mostly done automatically behind the scenes, so you don’t have to do anything about them. However, it is helpful to understand what they are and what they do, and how to use them just in case they are needed. That will be the subject of another article and video from me coming soon. So stay tuned for that.
Summary
In this article and video, you learn about Delta Lake, an open-source standard for storing data of Lakehouse tables. You learned how it structures the files and folder and keep the data in Parquet format. The Delta lake gives us benefits such as time travel, ability to audit the log and many other useful features which you have seen a few examples of those in this article. I will be writing about optimization options on Delta Lake tables in another article.
To learn more about some of the subjects mentioned in this article, use the links below;
- Introduction to Microsoft Fabric
- What is a Lakehouse
- Learn about OneLake
- What is a Notebook and how to use it




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.