

Copy Activity is one of the most commonly used activities in Microsoft Fabric’s Data Factory Pipeline. The Copy Activity copies the data from a source to a destination. However, there is more to that rather than just a simple copy. In this article, you will learn what Copy Activity is, its rationale, how it works, and its configuration options.
Video
Introduction
To understand the Copy Activity, it is best to understand Microsoft Fabric and Data Factory first.
Microsoft Fabric
Microsoft Fabric is an end-to-end Data Analytics software-as-a-service offering from Microsoft. Microsoft Fabric combined some products and services to cover an end-to-end and easy-to-use platform for data analytics. Here are the components (also called workloads) of Microsoft Fabric.

To learn more about Microsoft Fabric and enable it in your organization, I recommend reading the articles below;
Data Factory
The Data Integration component in Fabric is called Data Factory. This workload has two primary types of objects that help in data engineering activities: extracting data from the source, transforming it, and loading it into a destination. My article and video below explain more about Data Factory.
Data Pipeline
Data Pipeline is a control flow execution component inside Data Factory. A Data Pipeline is a group of activities (or tasks) defined by a particular flow of execution. The activities in a Pipeline can involve copying data, running a Dataflow, executing a stored procedure, looping until a specific condition is met, or executing a particular set of activities if a condition is met, etc.
Read my article below to learn more about Data Pipeline;
Copy Activity
Copy Activity is copying data from a source to a destination. Copy Activity can be added to a Pipeline to work with other activities, such as calling a stored procedure or as part of an IF condition or a Foreach Loop container.
There are, of course, different ways to copy data from a source to a destination. For example, depending on the destination, you might want to use Dataflow Gen 2 to get data from a source table and then load it into a destination (only a limited list of destinations is currently supported). Or you may write a stored procedure that reads data from a source table and insert it into a destination table. So what is the point of having an activity for copy? Let’s dig more into that in the next section.
ETL or ELT?
ETL is an old term in the data warehousing realm. ETL stands for Extract, Transform, and Load. This is when you first get the data from a source (Extract), transform it using functions and operations (Transform), and Load it into a destination. In the world of data warehousing, the destination is often a data warehouse. There are heaps of ETL tools in the market for this purpose. In the Microsoft world, SSIS and Power Query are two of these.
In the past few years, however, ETL has become a painfully long process due to the rise in the volume of data. Sometimes, the data source is slow; extracting and transforming it as one process may become very slow for big data. Instead, ELT became a method in which you first Extract the Data, then Load it into a destination without transforming it. After the data is in the destination (usually a high-performant system), you apply the transformation.

Many articles about ETL VS ELT and where and when to choose what. Doing the Load right after the Extract (EL) is called data ingestion. Data ingestion technologies invested a lot in improving the extract and load process performance. That is why ELT tools sometimes are different than ETL tools and technologies. Azure Data Factory has been an ELT tool in the Microsoft technology set.
ELT technologies focus on expanding the compute resources into multiple clusters to process more data faster and load massive amounts of data in a matter of seconds.
Copy Activity: The ELT Approach
Now it makes more sense to talk about just copying data from a source to a destination. If you are building a data warehouse to transfer billions and trillions of rows of data, then an ELT approach works better. You can load the data in seconds or minutes and then get the transformations applied on a high-performant data warehouse. The Copy Activity in Fabric helps you to do that exactly.
Copy Activity supports many data sources. Once the data is selected from a source, you can choose the destination and the mapping between the source and the destination. That’s it. No transformations. This will be a pure copy but a very high-performant copy.
Copy Activity will use the compute bursting feature of Fabric to enable more clusters to process the data faster and load it in the least possible time into the destination.
After the data is loaded into the destination, you can use their activities, such as a Stored Procedure or Dataflow Activity, to apply data transformations.
Staging While Copying
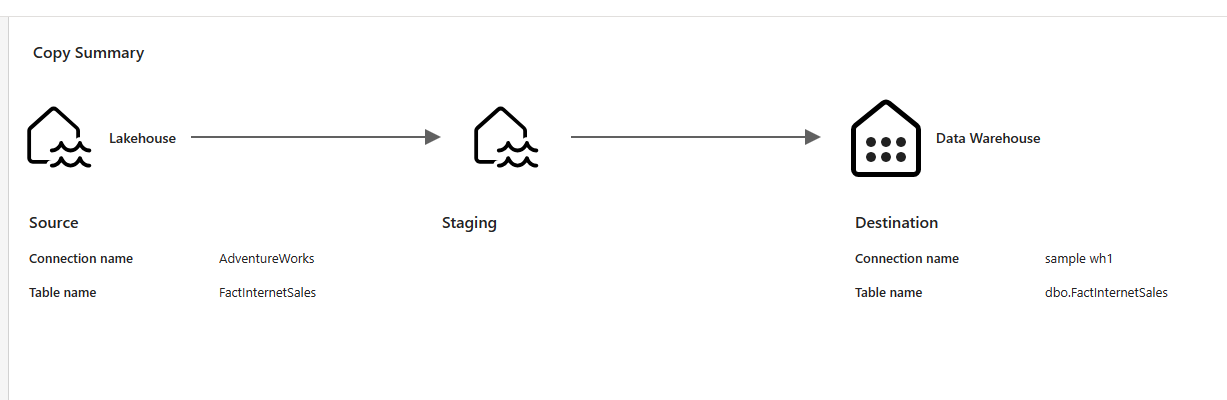
It is often needed to bring the data from the source into a staging environment first and then load it into a destination. Staging data has many benefits, one of which is data source isolation. My article explains some of the benefits of data source isolation. Copy Activity can stage the data while copying it, which is very helpful.
Getting Started
To use the Copy Activity, Go to the Data Factory workload of the Microsoft Fabric.
Then create a Data Pipeline
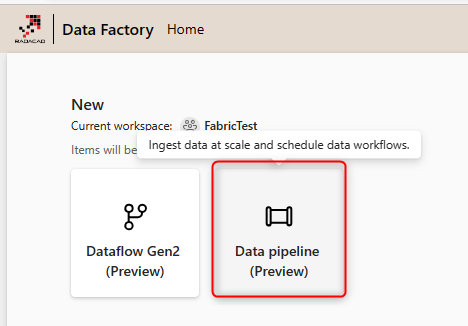
Inside the Pipeline editor, Create a Copy Data Activity. The best way to start it is to use the copy assistant, which will load a wizard.
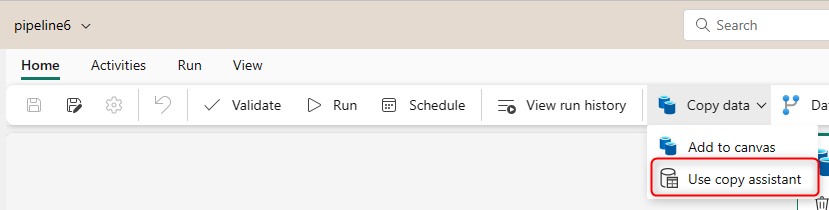
The Copy assistant is straightforward to use. You can choose the source type,
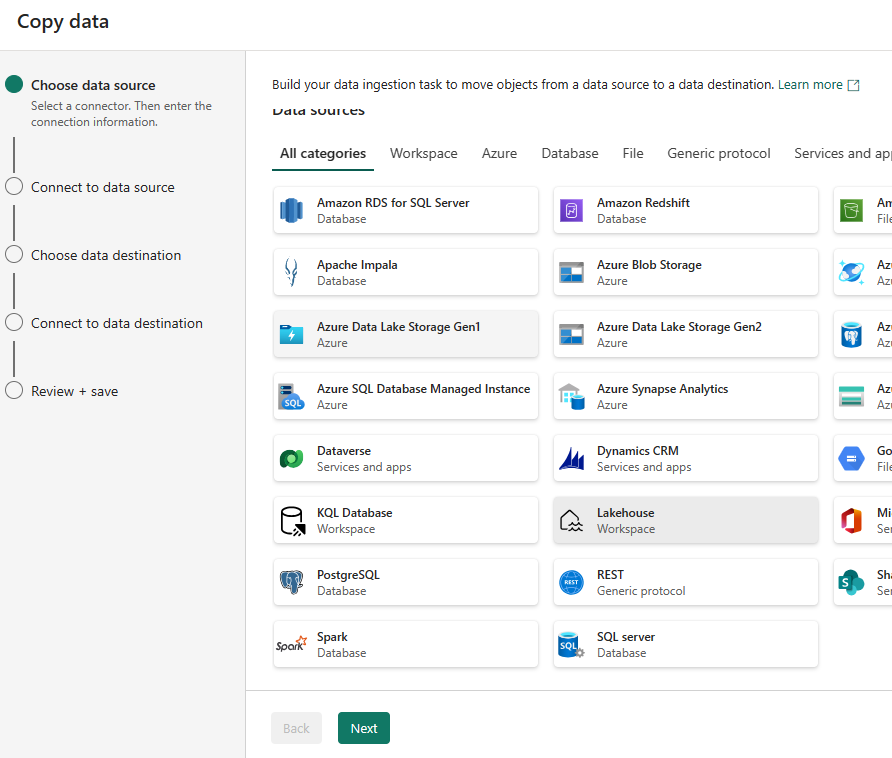
Then the source connection, and then the source table or file.
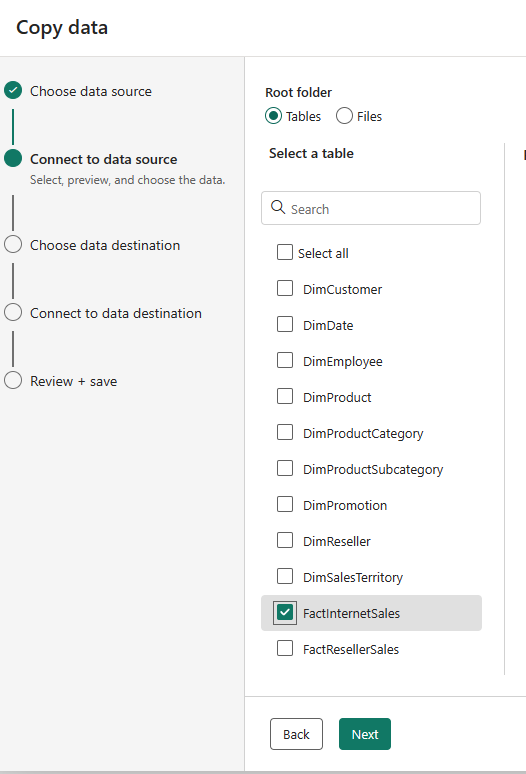
Then the destination type, the connection, and the table.
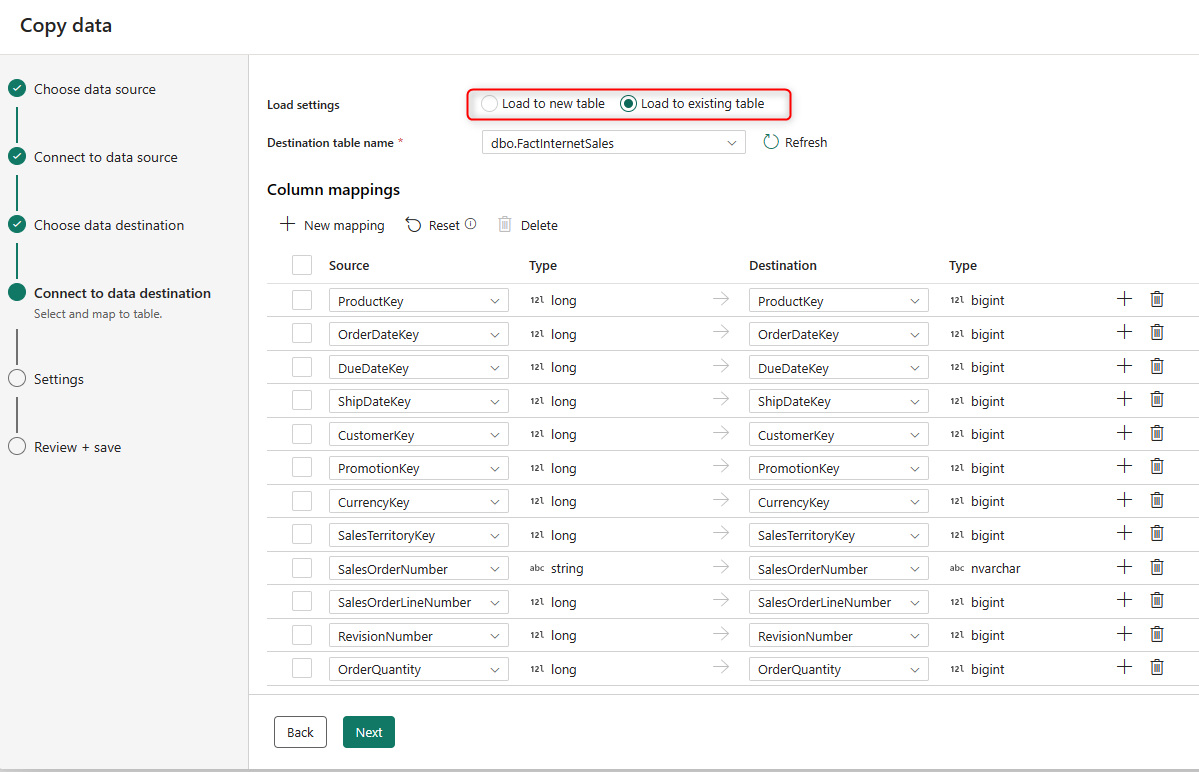
Then you can enable staging if you want.
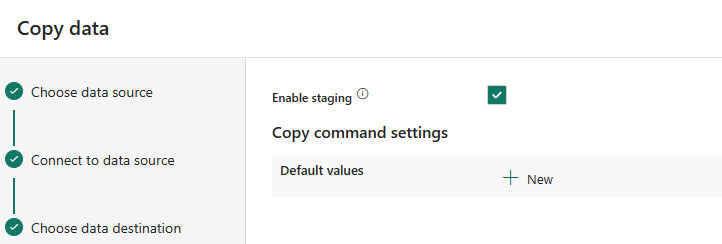
And review the settings.
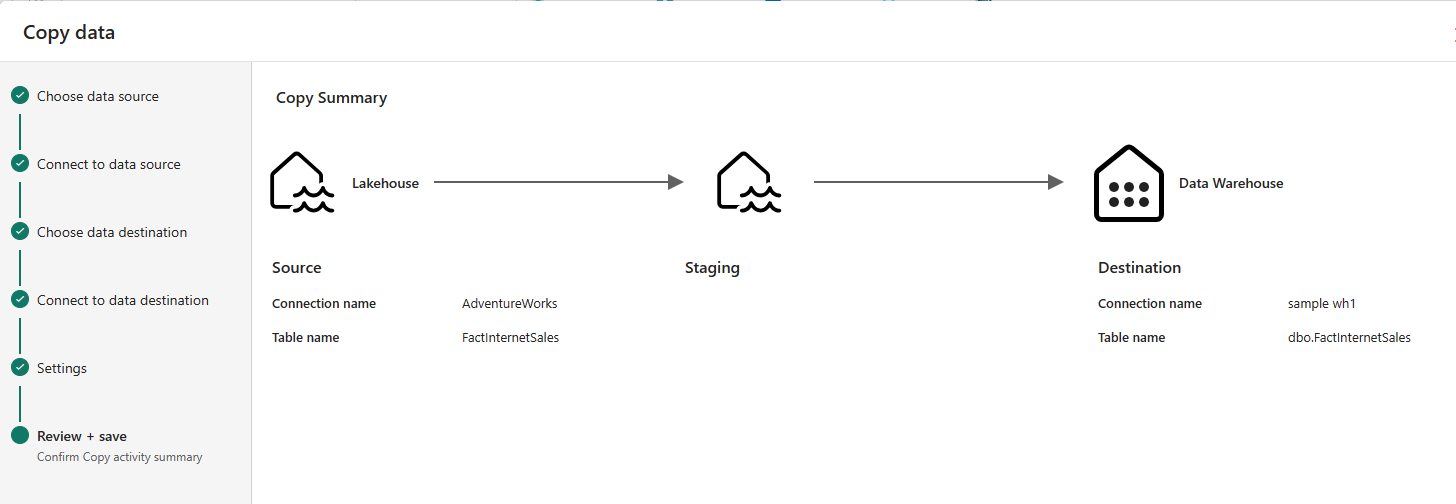
And run and monitor the execution of the activity and the data transfer operation.
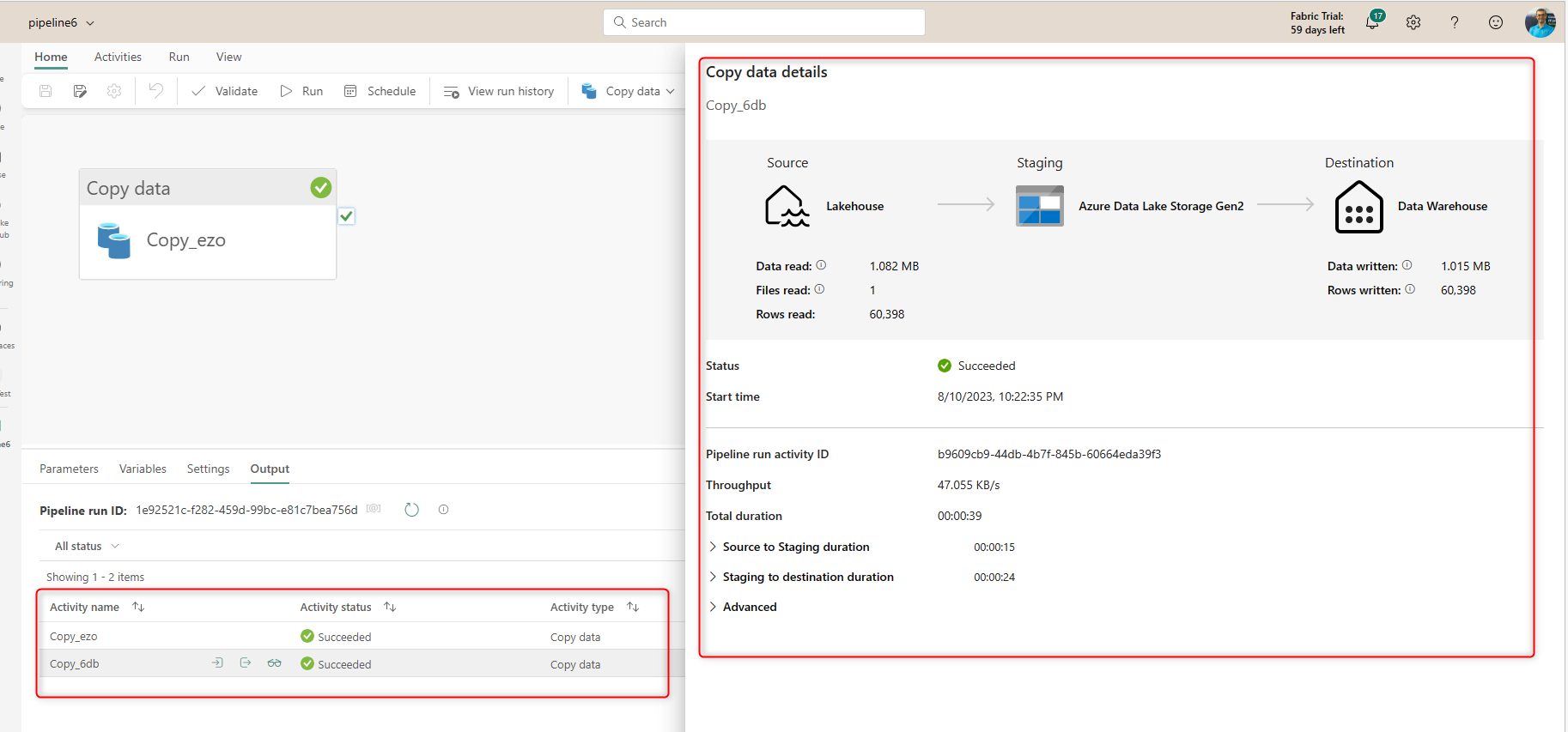
As you see, using the Copy Activity is simple. You can, however, apply some extra configurations.
Copy Activity: Copy with Extras
You can create the Copy Activity without the copy assistant. Or after you create it using the assistant, in the Data Pipeline editor, click on it and go to further settings.
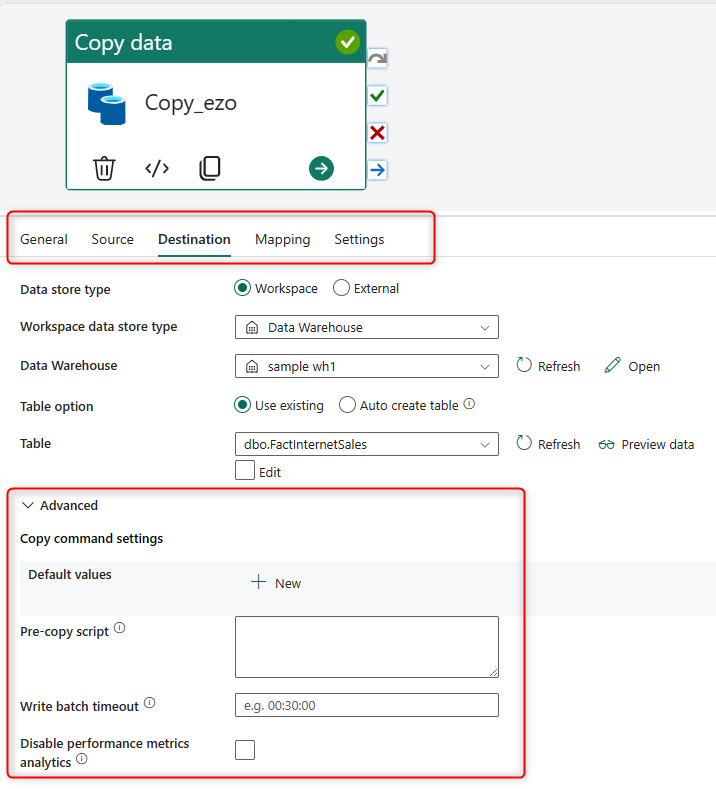
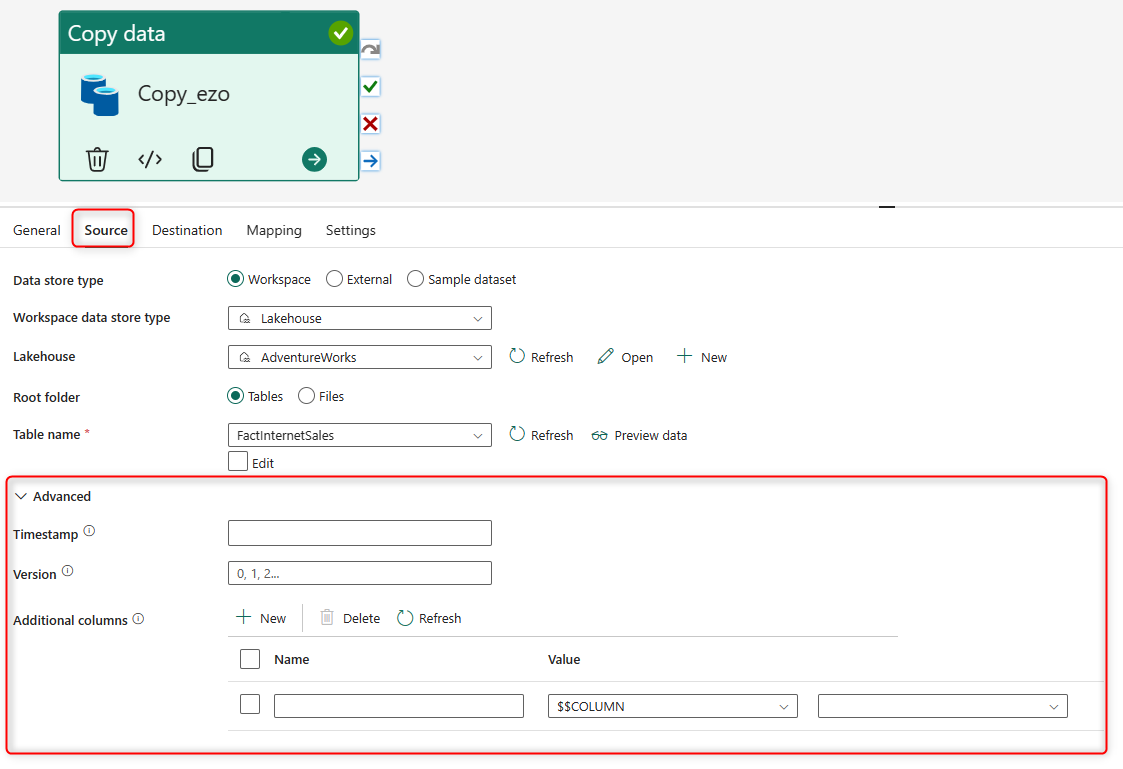
Each tab in the Copy Activity configuration will have options for advanced setup. For example, in the Destination tab, you can run a script before the copy process, Or you can create some extra columns in the Source tab, columns with timestamps and some other system information.
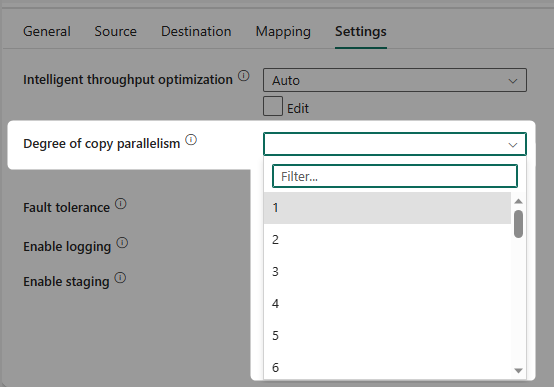
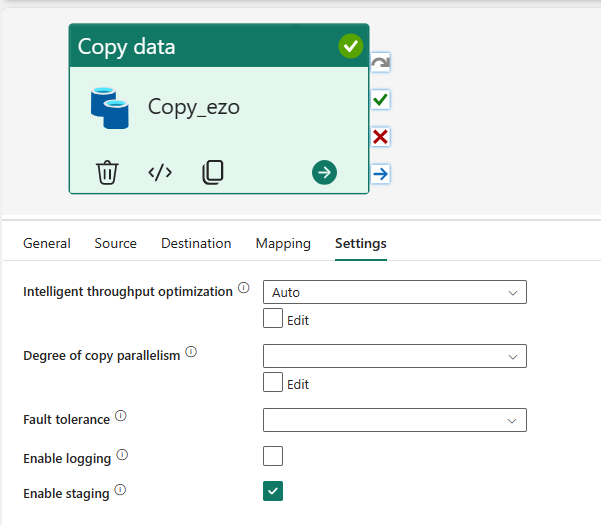
In addition to advanced settings in each tab, you also have a Settings tab, where you can set up things such as parallelism, logging, staging, and a few other options.
Summary: Copy or Not Copy
Copy Activity makes the process of extracting and loading very simple. However, this is not the only thing that it does. When the volume of data is enormous, the Copy Activity uses extra computing power to speed up the performance. The Copy Activity has extra settings and configurations to make a data transfer process work. These settings include mapping of columns, pre-copy script, adding extra system columns, additional logging, staging data before copying, and many other options.
It is through that copying data is just a small portion of the overall data integration process. However, with a high volume of data, it is often better to ingest the data first and then transform it. That is when the Copy Activity comes to play its role. The question that you should ask yourself is that do you want to do EL first or ET; Do you want first to copy the data or not? If yes, the Copy Activity is worthwhile considering.




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.