

Microsoft Fabric offers an end-to-end SaaS analytics solution; however, the world is using all kinds of data sources in its implementation. Mirroring is a new functionality in Fabric that allows customers to keep their data wherever they are, but then they can use Fabric analytics solutions with the same speed and performance as if their data were in Fabric. Best of all, this won’t cost extra. If you wonder what it is and how it works, read this article.
Video
Microsoft Fabric
Microsoft Fabric is an end-to-end Data Analytics software-as-a-service (SAAS) offering from Microsoft. It combines some products and services to provide an easy-to-use platform for data analytics. Here are the components (also called workloads) of Microsoft Fabric.
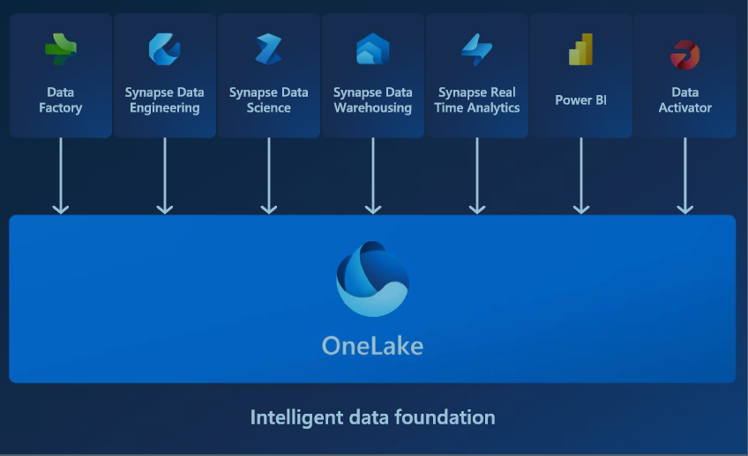
To learn more about Microsoft Fabric and enable it in your organization, I recommend reading the articles below;
Mirroring
Mirroring provides a replicated copy of the source database inside Fabric. The replicated copy is ingested once and then maintained synchronized with the data source in near real-time. Instead of investing time, resources, and money in integrating data from the source system into a Fabric Data Warehouse and keeping the data constantly up-to-date, Mirroring will do that all for you in just a few clicks!
Mirroring provides a replicated copy of the source database inside Fabric. The replicated copy is ingested once and then maintained synchronized with the data source in near real-time.
The diagram below shows how Mirroring will be used. The mirrored warehouse (which can be mirrored from Snowflake, Azure SQL DB, or Azure Cosmos DB) will be like a normal warehouse inside Fabric. You can have a Power BI Semantic Model for it, which uses a Direct Lake connection with superfast performance and then reports with a Live connection to it. Or you can have SQL code cross-joining the data of the mirrored warehouse with other warehouses and lakehouses in Fabric, even those with shortcuts from other sources.
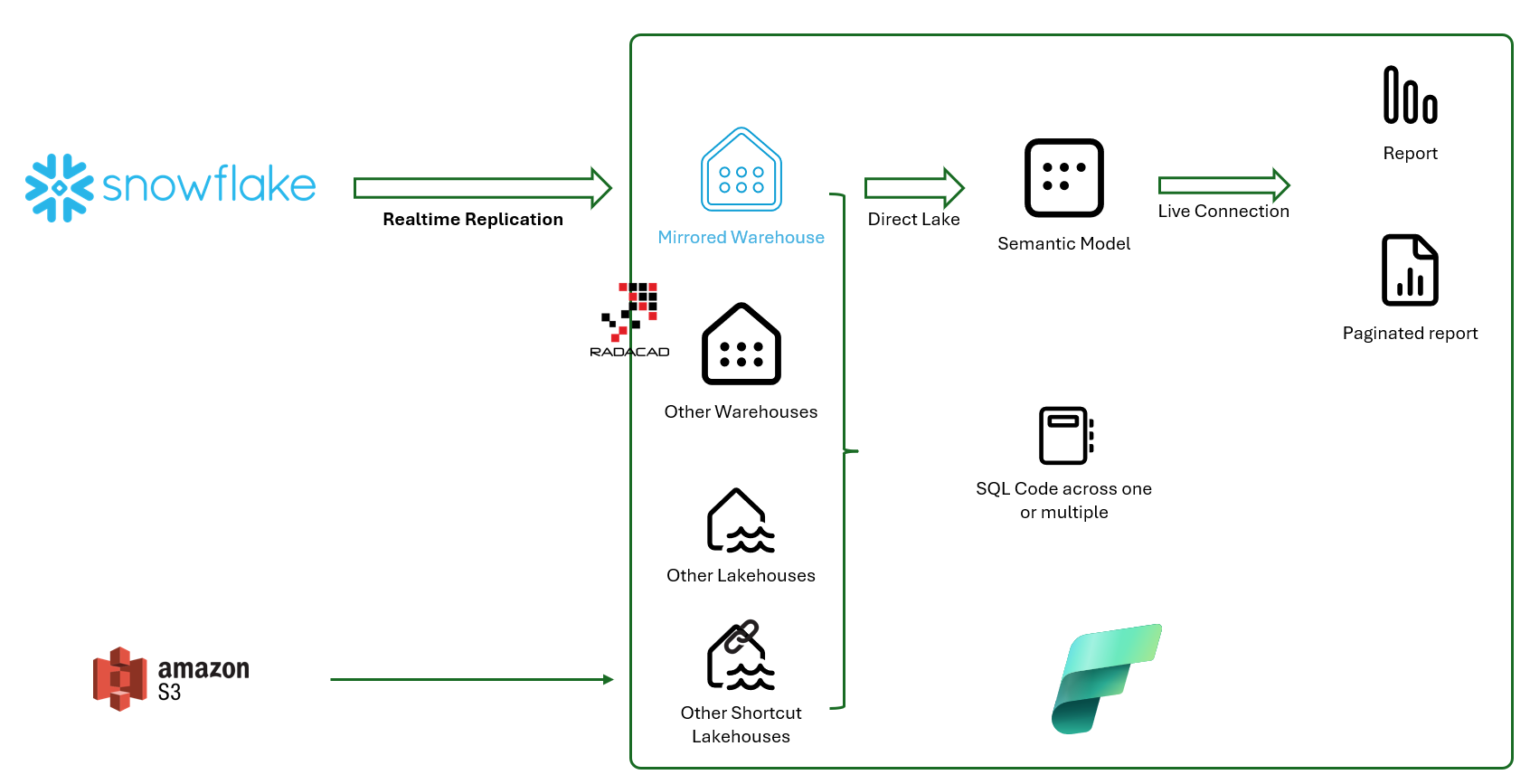
At the time of writing this article, Mirroring is possible for three sources: Snowflake, Azure SQL Database, and Azure Cosmos DB. More sources will be available soon.

Mirroring involves using Data Factory behind the scenes for the first load of the data and also for keeping the data in sync continuously (features such as Change Data Capture in the source system will be used for that purpose). The great thing about it is that you don’t have to deal with any of it; it just works perfectly behind the scenes.
To understand the reasoning behind mirroring, let’s address some of the pain points when you have your data in a non-Fabric object (such as Snowflake) and want to use Microsoft Fabric objects for analytics (such as Power BI reports)
Data Integration: Where is the ROI?
Not all organizations use the same database technology; some use Microsoft databases such as Azure SQL Database and Azure Cosmos DB, and some use other technologies such as Snowflake for their cloud-based database system.
When it comes to using Microsoft Fabric for analytics over your data, if the data isn’t available in Microsoft Fabric as a Lakehouse or Warehouse, often the very first step is to bring that data into Fabric. The process of bringing the data, or in other words, Data Integration, is a long, resource-intensive, and time-consuming process. Analytics teams usually find it hard to get a budget approved for such a process because it is very hard to show the return on investment for that piece of the project. What would you say to your manager? “We spend three months working with the entire team here to bring the data from Snowflake to Microsoft Fabric!” is not even a report or insightful analytical results to show, just pure integration.
Of course, you have to consider all aspects of making it a successful integration because it is not just the first load of the data. It is also keeping it up-to-date with the source system. Many things might go wrong, and that is one of the reasons why the data integration piece of the project usually takes time: You have to get it working perfectly for the other parts of the system to work.
Reduce the costs
If you pull the data in a non-incremental way from the data source, the integration process would be faster because you don’t have to deal with delta load. You will do a full load each time, but then you will have another issue: the source systems (especially cloud-based systems) charge you based on the load of transactions. The cost would go sky-high if you pull millions of records out of Snowflake every night.
If you decide to use another method for your Power BI reporting, such as Direct Query, then every time filtering or slicing and dicing the report by any of the users, you will send queries to the source system, and these would all cost money at the end of the month.
Increase the performance
The large volume of data in the source systems usually causes some implementations to use Direct Query to the source system, which has a really slow performance. Direct Query performs very slowly compared to Import Data, which is the preferred way of connecting Power BI semantic models.
Benefits of Fabric Mirroring
Some of these pain points are familiar to you, perhaps already. What the benefits of Mirroring at Microsoft Fabric are; let’s check them below;
- No time spent on data integration
- No cost for the Mirrored data stored in Fabric (That is right)
- Continuous near real-time synchronization with the source database
- Using the data of the source database inside Fabric, like any warehouse object
- Cross-joining that data with other warehouses or lakehouses
- Having a super-fast Direct Lake connection to that data from the Power BI semantic model
- Reducing the costs associated with transactions on the source database system
Sample Demo
Let’s go through a sample demo of Mirroring so that you can see how it works. I will be using a Snowflake database source for this example, but the process will be similar for Azure SQL database and Azure Cosmos DB (and any other sources available for Mirroring in the future).
I have a database in Snowflake that includes just one table with customer data.
In Fabric, we can create a Mirrored Snowflake warehouse by selecting the item under the Data Warehousing workload.
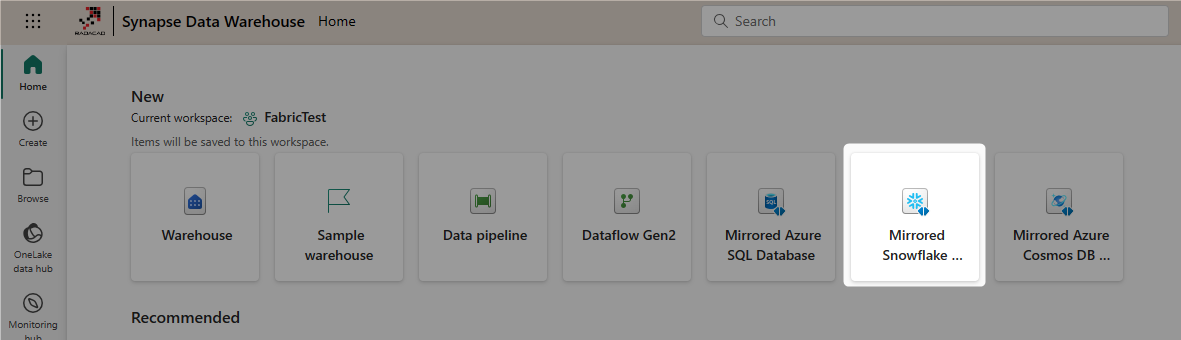
After setting a name for the Mirrored warehouse, you can choose the source as Snowflake;
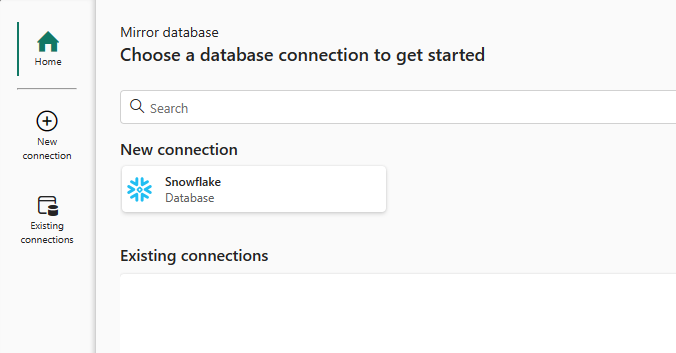
Then, enter the credentials and details of the Snowflake source warehouse;
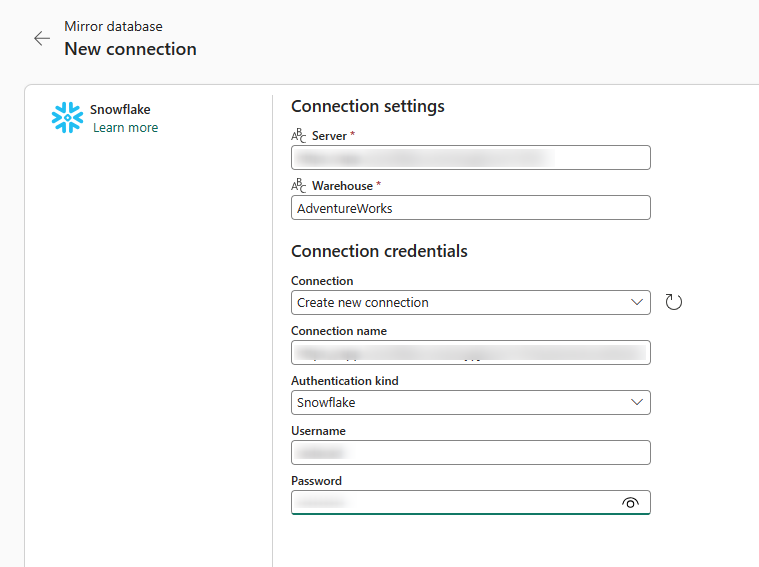
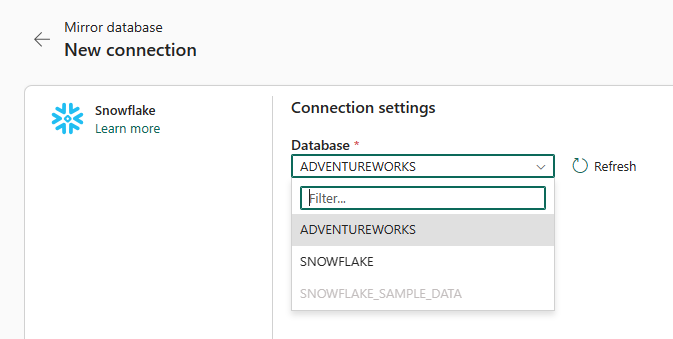
Then, choose the database you want to select for Mirroring;
If the database includes many tables, and you need a few in Fabric, you can disable the Mirroring for the entire database and select specific tables. Otherwise, Mirror all data.
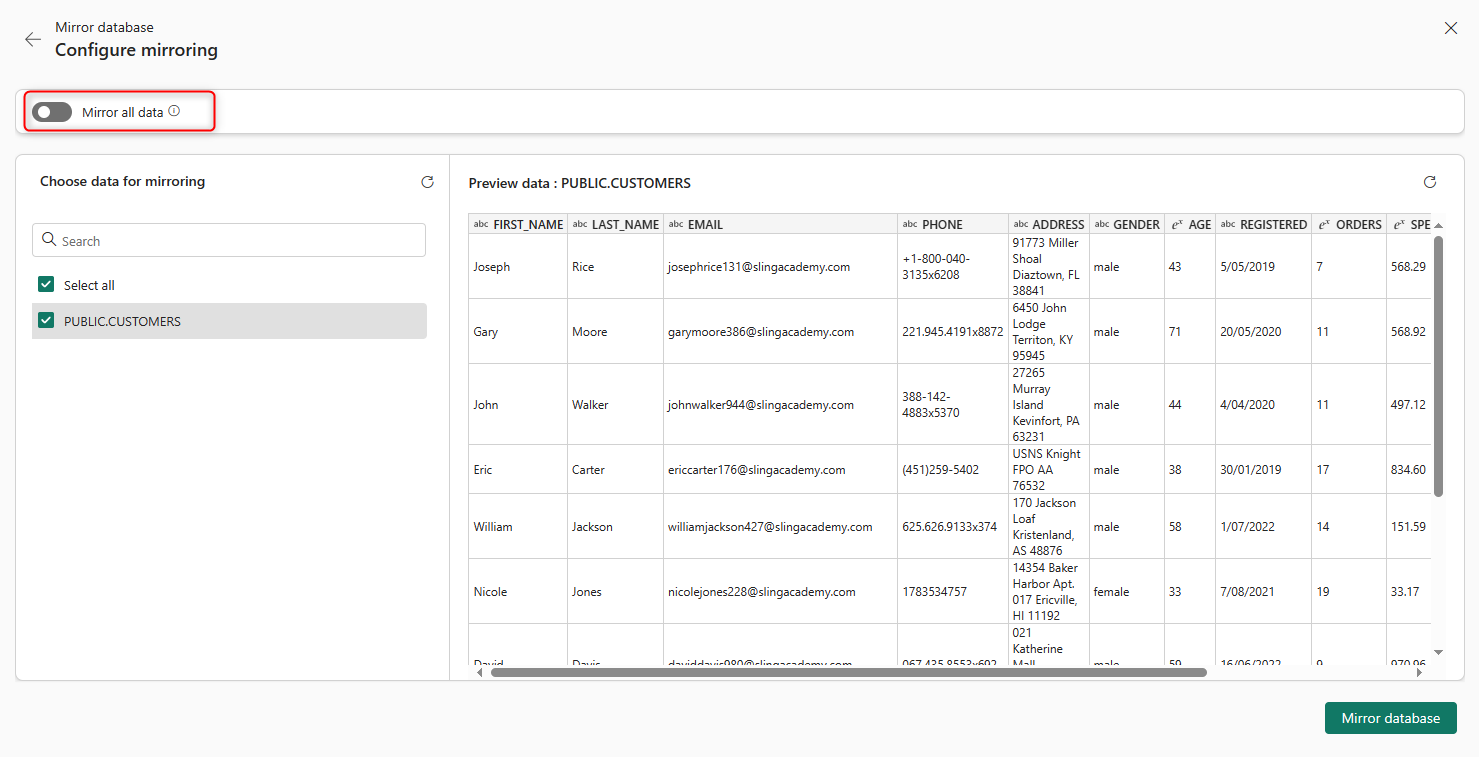
That’s it, then wait for the Mirror to be created for the first time.
You can also see the process by clicking on Monitor replication;
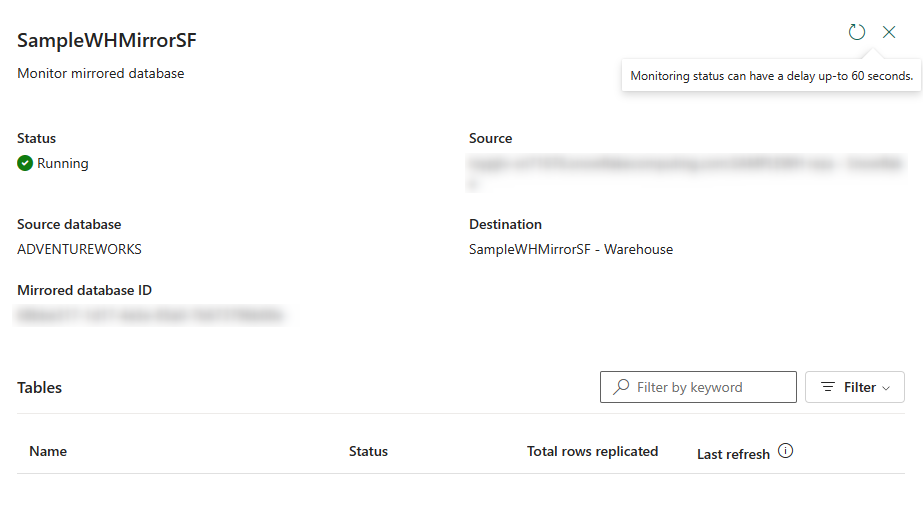
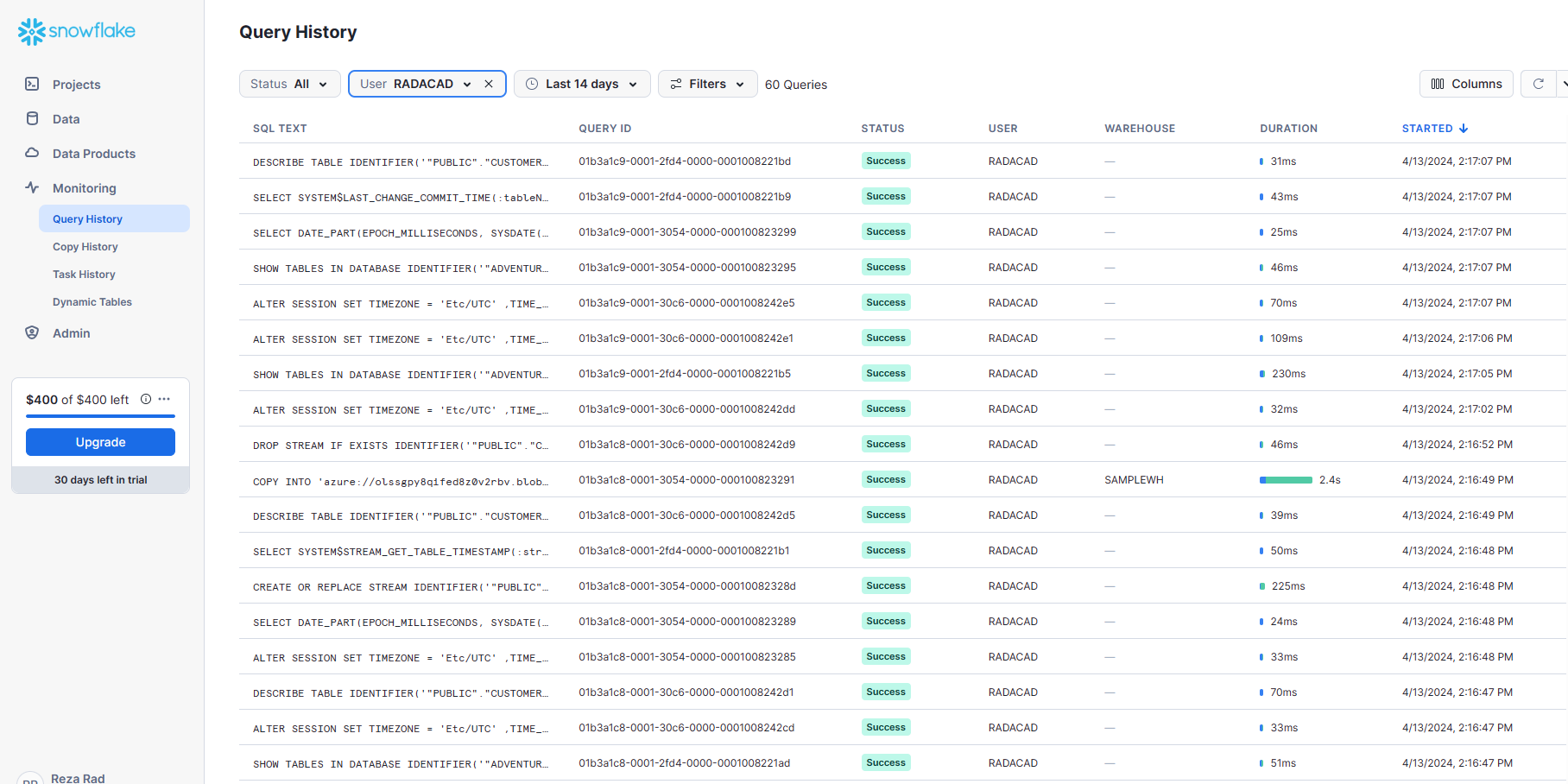
The mirroring process will send some queries to the snowflake, which you can see;
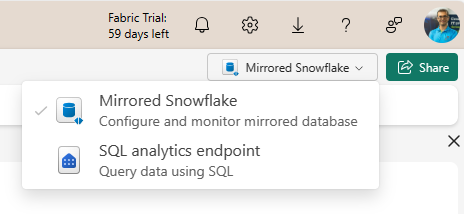
When the data is available in the Mirrored database, you can create a Semantic model by switching to SQL Endpoint.
Then, you can create a report using that semantic model.
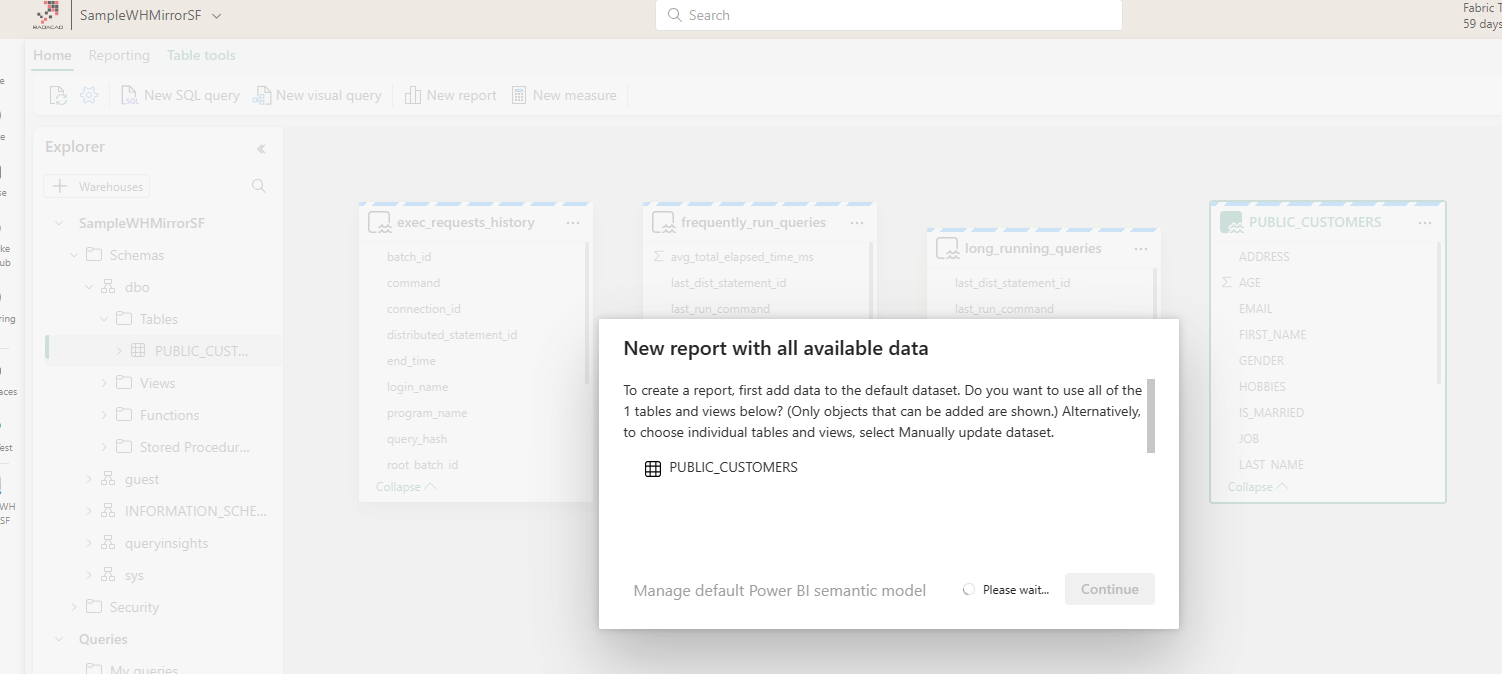
Below is the sample report I created;
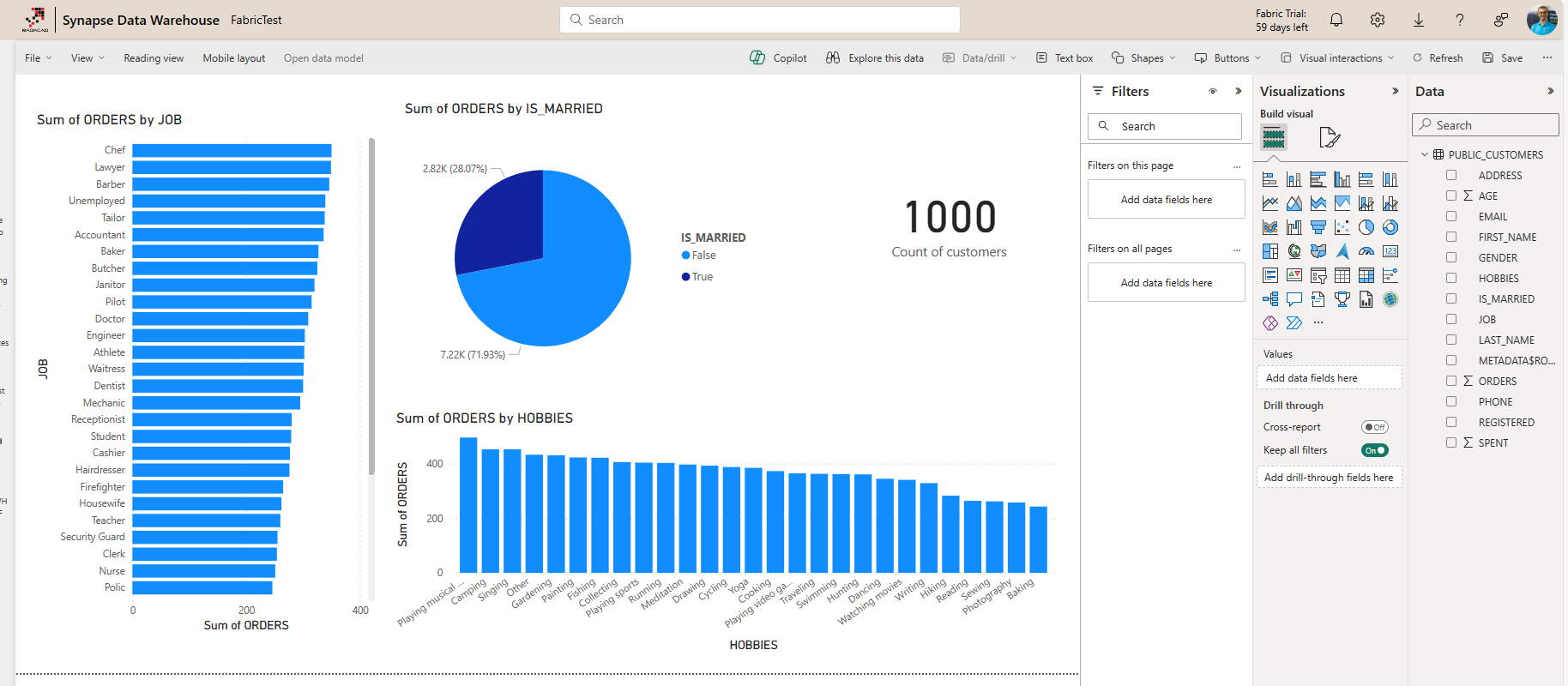
This is a Power BI report live connected to a Sematic model, which uses a Direct Lake connection to the Mirrored Warehouse. As you can see in the report above, I have 1,000 customers.
Let’s see how the data updates in the source system will be synced in the report. I insert a couple of records in the Snowflake database manually;
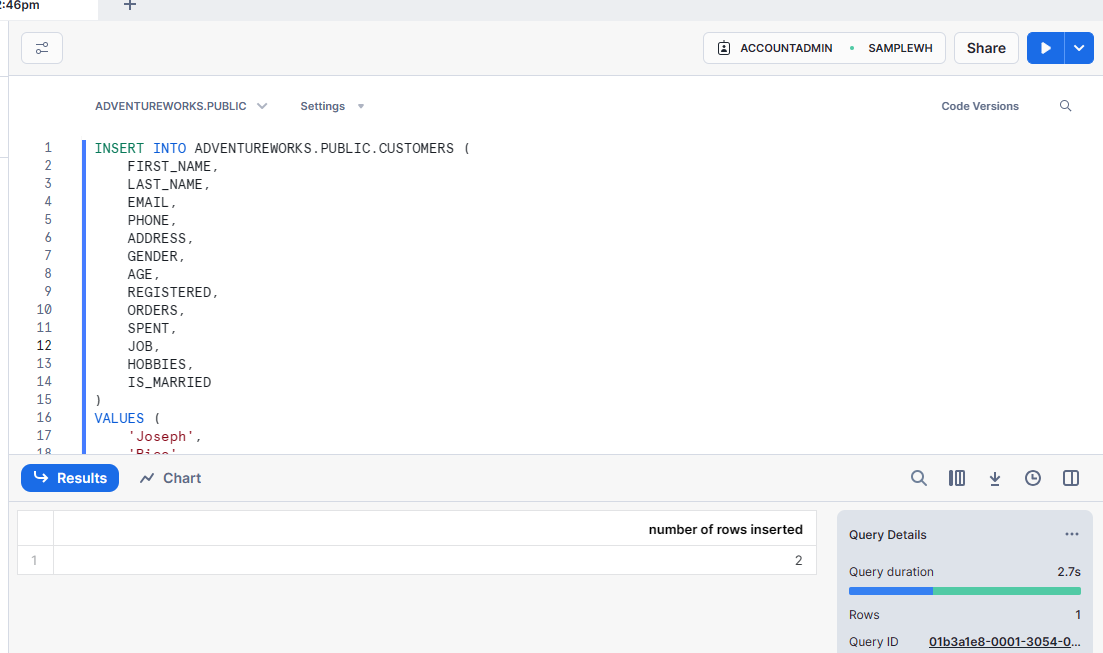
I added two customer records in the Snowflake. Now, when I go back to the report and refresh it (I don’t need to refresh the Sematic Model as it uses the Direct Lake mode), I see the customer count is 1,002.
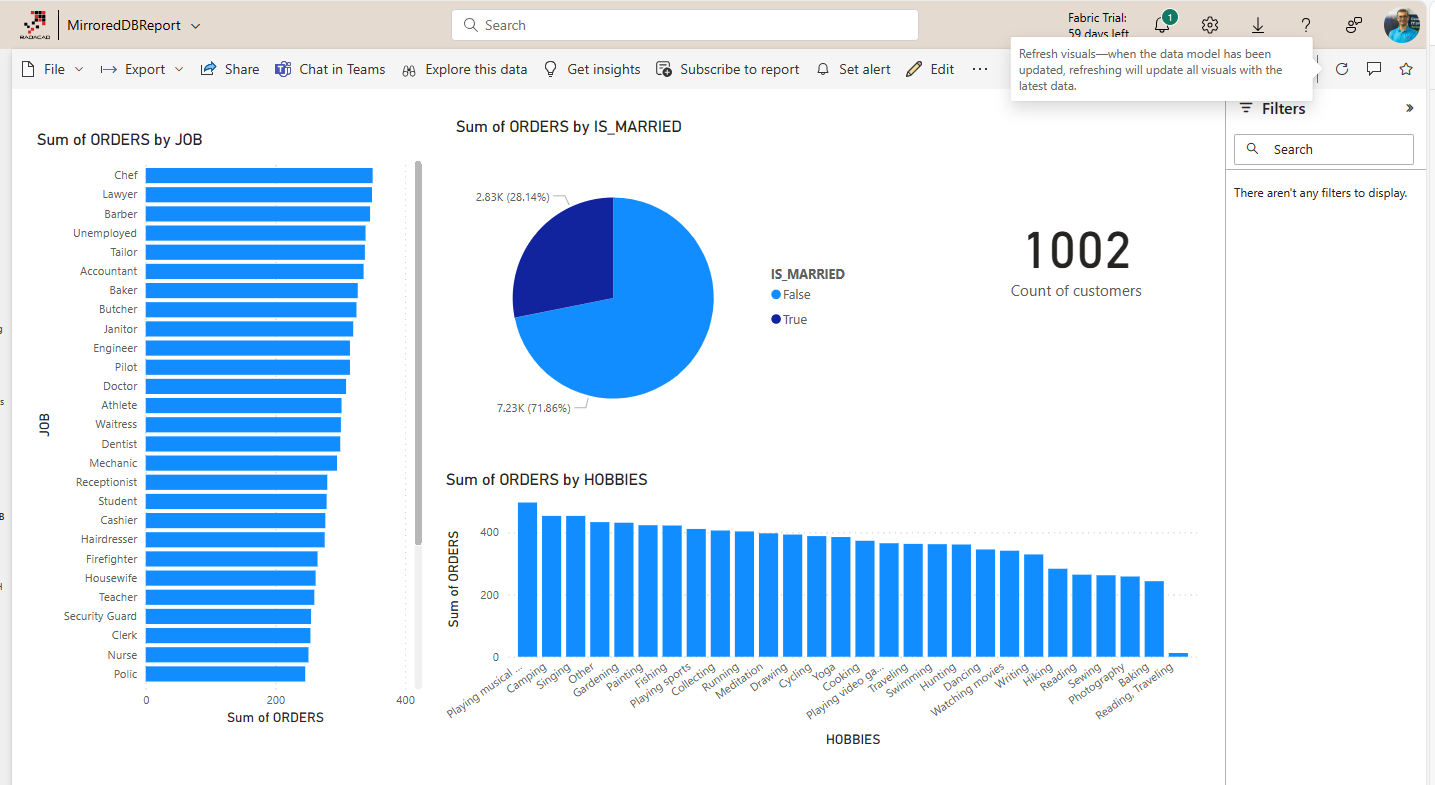
The mirroring process is very efficient. You have to try it yourself and see. If you ever want to stop the mirroring or change some configuration for it, you can. However, it would be best left to run all the time so that you have your data up-to-date.
Summary
If your data is stored in Snowflake (or any other sources that Mirroring supports), then this is a game changer for you. Instead of spending time, resources, and money to integrate the data from your source system into Fabric, instead of dealing with slow connection modes such as DirectQuery, and instead of spending extra money for extra transactions sent to the source system, you can use Mirroring. Mirroring generates a replicated copy of the source database and will keep it synchronized. The mirroring won’t cost you extra money, it would in fact saves you some money from the source system too, it is fast, efficient, and the performance of your report at the end will be super fast because it uses Direct Lake connection once the data is in Fabric warehouse.
If you are using any of the sources supported by Mirroring (Snowflake, Azure SQL Database, Azure Cosmos DB), I strongly suggest to you to give this feature a try, this would turn the tides in your favor with your analytics project.




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.