

With the Microsoft Fabric announcement, There are also additional features in Power BI that makes the connection between Power BI and other Microsoft Fabric objects seamless and more profound. One of these features is the Direct Lake connection in Power BI. In this article and video, we’ll talk about the Direct Lake, how it differs from other types of connections in Power BI, and how you can use it in an example.
Video
What is Microsoft Fabric
Knowing about Microsoft Fabric can be helpful before we start talking about Direct Lake in Power BI. Microsoft Fabric is an end-to-end Data Analytics platform software-as-a-service from Microsoft. This platform uses multiple workloads to carry all services related to data analytics, such as data integration, storage, data warehousing, data engineering, Business intelligence, Data science, etc.
These are good starting points if you want to get yourself more familiar with Microsoft Fabric;
Connection Modes in Power BI
Power BI uses multiple methods of connections. These are the methods that Power BI accesses the data and respond to the visualization queries. Any visual that you see in the Power BI report uses a dataset, which then uses one of the types of connections below;
- Import Data or Scheduled Refresh
- DirectQuery
- Live Connection
- Composite Mode
- Direct Lake (New. The topic of this article)
I have an article comparing all of the connection types here. To understand what DirectLake is, we’ll go through a quick introduction to two of the connection types above; Import Data and DirectQuery.
Import Data
This type of connection is the fastest. The data from the source is IMPORTED into Power BI. Power BI has a proprietary file format, which the data stores in that format and then expands into the memory of an Analysis Services Dataset. The data, then, will be available to query in a very high-performant and responsive way.
The Data will be compressed based on the Vertipaq compression engine. However, this method would still consume extra storage beside the data source. Import Data might not be an option in cases dealing with massive data. Another problem with the Import Data is the need to schedule the dataset to refresh to get up-to-date data. If you need live data, then Import Data won’t fit the purpose.
I explained in detail about the Import Data connection mode here;
DirectQuery
For scenarios where the data size is enormous, and the live data (or by some called real-time data) is required, the DirectQuery mode works better in Power BI. DirectQuery mode won’t create a copy of the data. It will keep the data in the source only. However, the Analysis services will have an engine that translates queries from the visuals into the code language the data source understands (for example, SQL), sends that code to the data source, and gets the result back.
The process of sending the SQL code to the data source and getting the data back is very slow. DirectQuery provides access to the data without the need to refresh the dataset. However, it comes at a considerable cost of reducing the performance. To avoid the performance issue, one can create a composite model where part of the data is imported and part of it is DirectQuery, this mode of connection is called the Composite model.
To learn more about DirectQuery, read my article here:
Direct Lake
The data storage component of Microsoft Fabric is OneLake. OneLake stores the files in parquet format. The Microsoft team implemented enhancements in the parquet files to make them very efficient for VertiPaq querying. The result is that when a Power BI dataset reads data from OneLake, it can query the parquet files directly and doesn’t even need to send SQL queries to it. This will lead to an excellent performance (similar to Import Data) and, simultaneously, for live data (no refresh is needed). This new way of connecting Power BI is called Direct Lake.
The diagram below from Microsoft (Source: https://learn.microsoft.com/en-us/power-bi/enterprise/directlake-overview ) shows clearly how DirectLake is different from Import Data and DirectQuery.
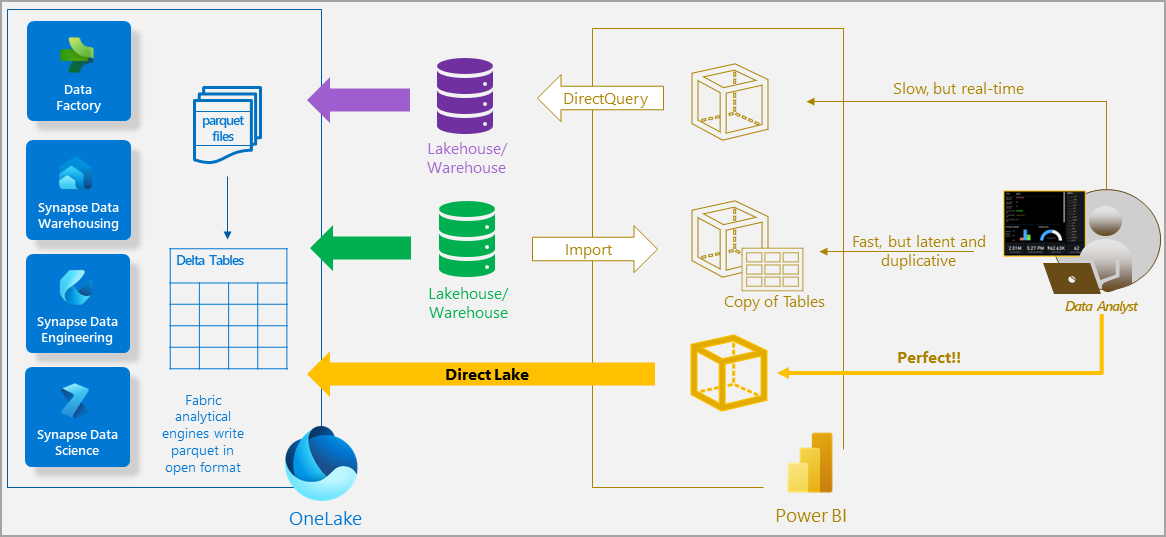
Direct Lake benefits from both connection types; it is high-speed for performance and doesn’t need a scheduled refresh.
The secret that the DirectLake is working far better than DirectQuery is the enhancements on the Parquet files in OneLake to respond to the Vertipaq queries.
How it works: Lakehouse
Direct Lake works with the data available in the OneLake. This means you must use an object that stores data in OneLake. At the time of writing this article, Lakehouse is supporting Direct Lake. Lakehouse is an object in Microsoft Fabric that can store structured and non-structured data. I have explained the Lakehouse in detail in my article here;
The article above also explains creating a Lakehouse and loading data using a Dataflow.
The Dataset associated with the Lakehouse
The Lakehouse comes with a default Power BI dataset. This dataset has a default written next to its name in the workspace.
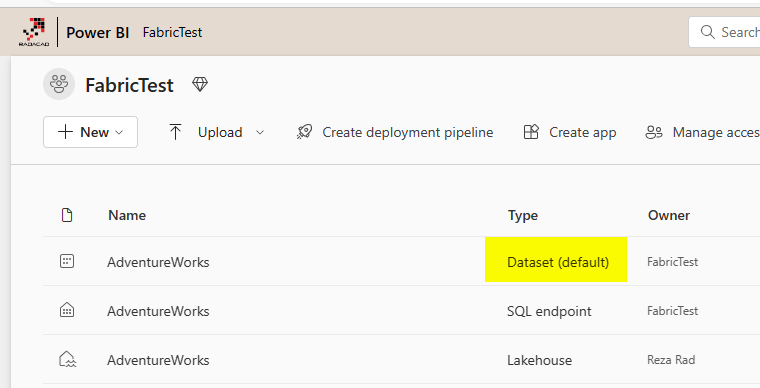
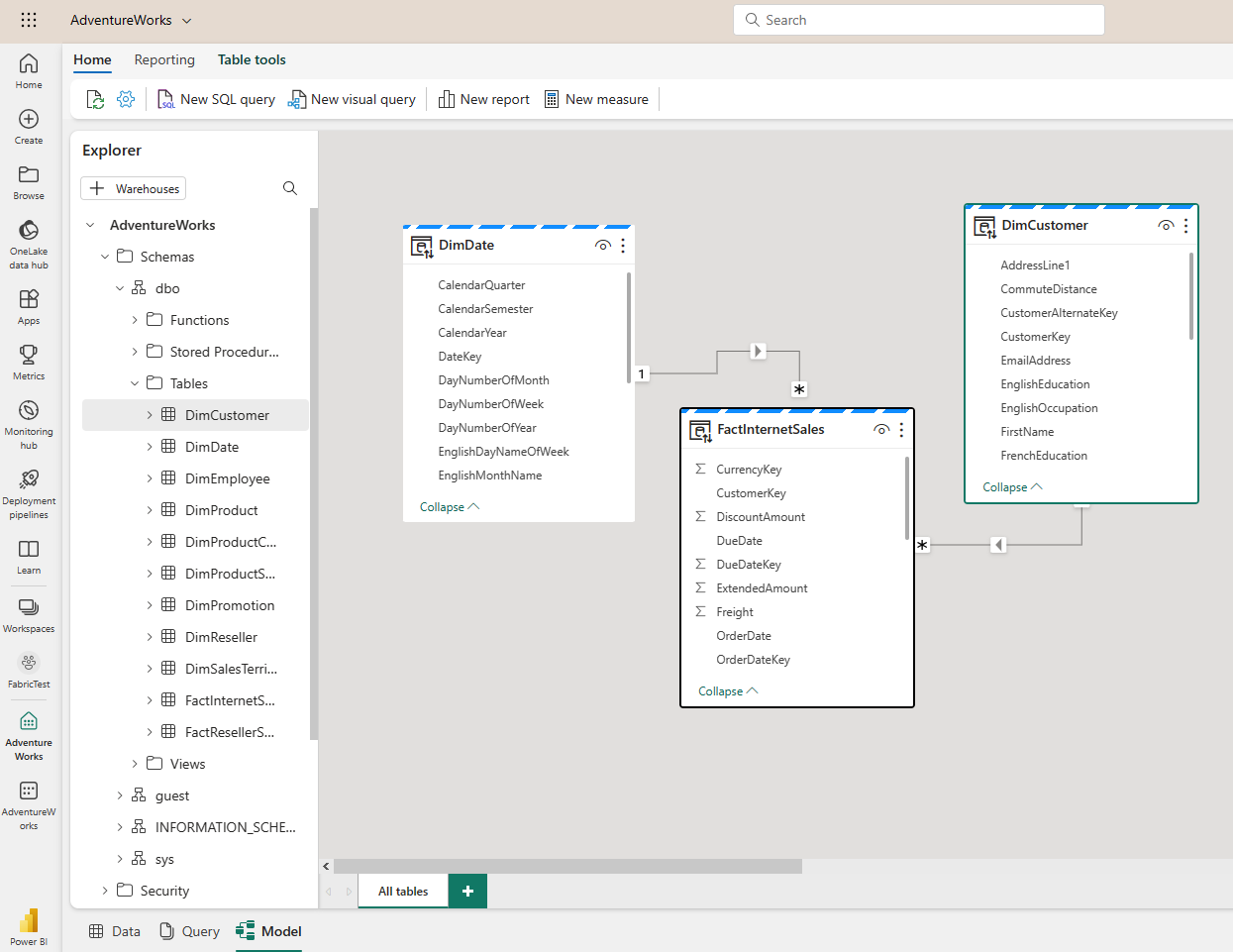
The default dataset usually has all the tables of the Lakehouse in it. You can then create relationships between objects and apply some other modeling changes. To access this default dataset and use the web modeling editor, you need to click on the SQL endpoint of the Lakehouse.
The Direct Lake connection is indicated when you hover over the table headers in the model view.
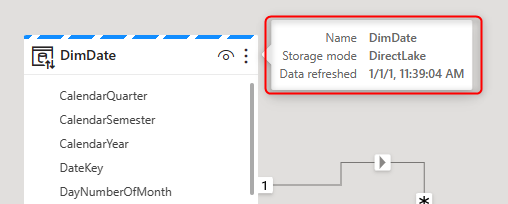
Using the Direct Lake connection, you can also create a new Power BI Dataset. The Dataset has to be made using the web experience (at the time of writing this article, only creating it from the web experience will initiate a Direct Lake connection).
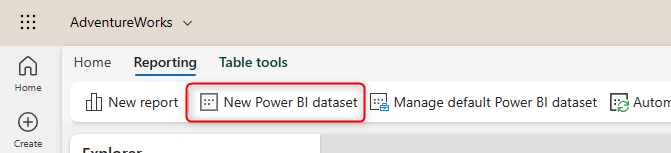
Any Power BI report connected to this dataset will then use the Direct Lake connection.
Limitations
With every new feature, there are always limitations, which generally will be lifted when the feature matures through time. The same is true about the Direct Lake. Limitations about using the web experience, inability to use calculated columns or some of the data types, etc., are among the limitations of this connection mode. Remember that this type of connection is still in preview.
Data Refresh
The default Power BI Dataset associated with the Lakehouse will be automatically refreshed when the data changes. However, if you created a custom Power BI dataset with a Direct Lake connection, you can go to the settings of that dataset and change this behavior;
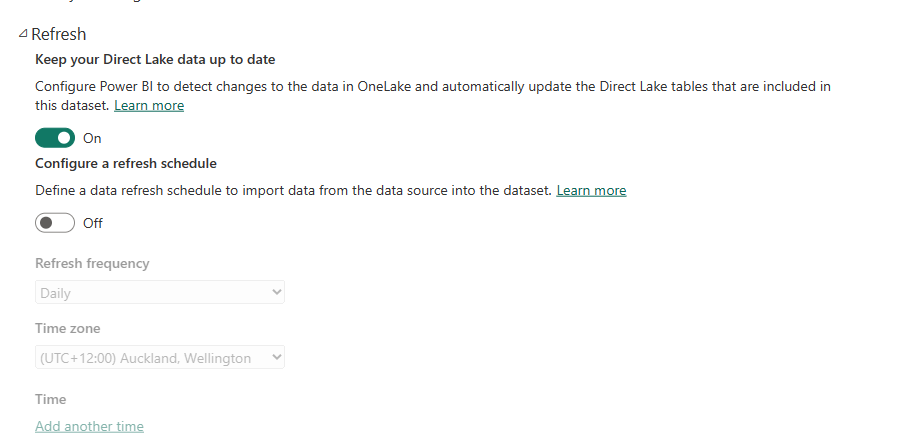
If you disable the option above, the automatic update of the dataset upon changes in the data will be disabled. This might be good for scenarios where the data takes some time to be loaded into the Lakehouse. If you disable it, you must invoke the refresh to update the data.
The concept of a refresh here differs from refreshing data for the Import mode. The refresh here means that the data of the Lakehouse will be exposed for queries coming from Power BI.
Summary
Direct Lake is the newest type of connection in Power BI. When the data is stored using a Lakehouse inside the OneLake, Power BI dataset supports a specific type of connection called Direct Lake. This type of connection is fast (like an import data connection) and real-time (like a DirectQuery connection). The secret is that the visual queries won’t be translated to SQL queries to run against the SQL endpoint of the Lakehouse; they would run directly on Parquet files stored in OneLake.
I recommend reading the articles below as they are also related to this topic;
- Import Data or Scheduled Refresh
- DirectQuery
- Live Connection
- Composite Mode
- Comparing connection types in Power BI
- What is Microsoft Fabric
- How to enable Fabric in your organization
- Lakehouse




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.