

Microsoft Fabric runs some workloads under the Spark engine, but what is it really? In this article, I’ll take you through the question of what Spark is, What benefits it has, how it is associated with Fabric, what configurations you have, and other things you need to know about it.
Video
What is Spark?
Apache Spark is an open-source project which is originally developed at UC Berkeley in 2009. It is a parallel processing analytics engine for large-scale data processing. It is for big data analytics, and compared to previous technologies such as Hadoop it is 100 times faster.

Apache Spark (or Spark in short) is a multi-language engine; you can communicate with the engine using the languages below;
- Python
- SQL
- Scala
- R
- Java
Spark comes with some high-level tools/libraries that can be used for different purposes;
- Spark SQL: relational queries processing engine
- Pandas: Libraries to work with data
- MLib: for machine learning
- GraphX; for graph processing
- Structured Streaming: for streaming
Spark in Fabric
The use of Spark in Microsoft Fabric is fully managed and abstracted. This means that the complexity of spinning up a Spark instance is managed behind the scenes for you. You have the ability to control some of the configurations and settings, but most of the hard work is done for you.
Spark compute is used specifically for the data engineering and data science experience in Fabric, and specifically is in use when you run a Notebook or a Spark job Definition.
Spark Pool and Spark instance
An instance of Spark will be initiated only when you connect to it, which is using one of the methods below;
- Executing a code in Notebook
- Executing Spark Job Definition
The initiated spark instance will be under a set of configurations and characteristics (metadata) that control how the instance runs. This set of metadata characteristics is called Spark Pool. In other words; Spark Pool tell the Spark engine that what kind of resources we need for our analytical tasks.

Image Source: https://learn.microsoft.com/en-us/fabric/data-engineering/spark-compute
Spark Node
Spark would run the applications (or codes) under what is called a cluster, which is usually managed by multiple Nodes. Consider Nodes as machines or threads that actually do the job. It is often set in a way that there is one header node called the driver and multiple (at least two) worker nodes. The header node controls the cluster, while the worker nodes actually execute the work; they are also called executors. The screenshot below shows this process;
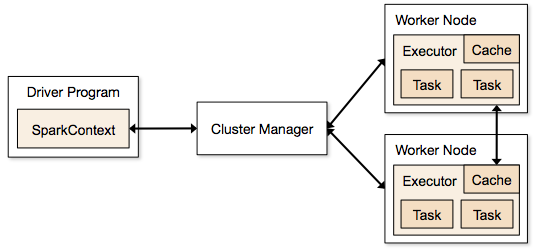
Image Source: https://spark.apache.org/docs/1.1.1/cluster-overview.html
Fabric Spark Pools
Well, the above explanation and details looked quite technical, but the good news is that most of that is abstracted and managed behind the scenes. You don’t even need to set these; there are default configurations.
Two types of Spark Pools are available in the Fabric environment: Starter Pool and Custom Pool.
Starter Pool VS Custom Pool
Starter Pool is an easy-to-use Spark Pool that can be initiated very fast within seconds. This is what is by default associated with a workspace when assigned to a Fabric capacity.
The Starter Pool comes with some pre-defined configurations of node size, autoscale, and dynamic allocation setup, which can differ depending on your Fabric Capacity license. This is an example of a Starter Pool configuration;

Image Source: https://learn.microsoft.com/en-us/fabric/data-engineering/spark-compute
Custom Pool, on the other hand, is customized by you; you can decide the number of Nodes you want, the size of the node, and other configurations.
The Starter Pool is designed for developers who are not very experienced with Spark, while the Custom Pool is better for experienced Spark users.

Image source: https://learn.microsoft.com/en-us/fabric/data-engineering/spark-compute
Fabric Workspace Setup for Spark
You can set up the Spark Pool configuration at the Workspace level in the Microsoft Fabric environment. You have to go to Workspace Settings to find the options.
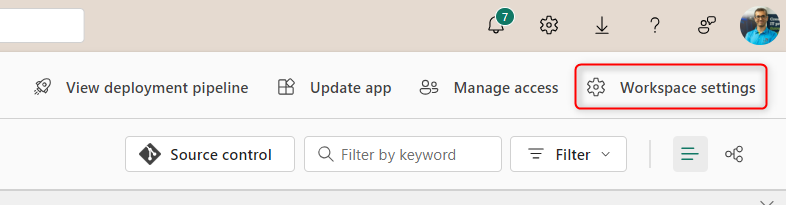
Under the Workspace settings, you can see the Data Engineering/Science tab, and under that; Spark settings.
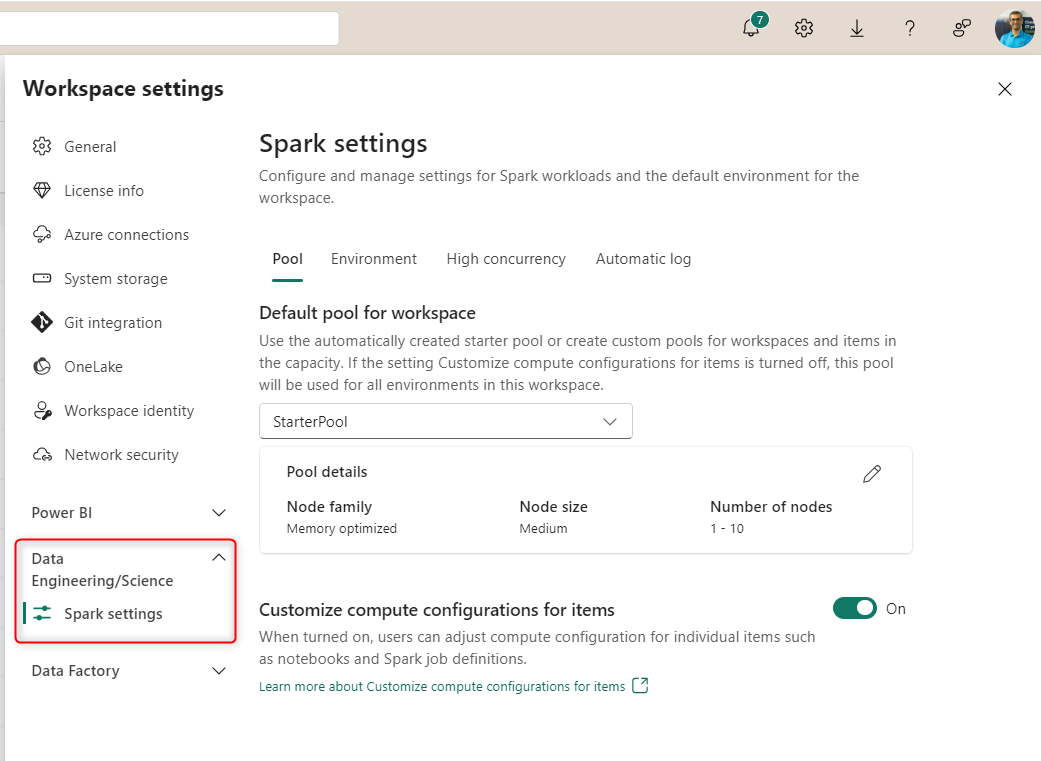
Workspaces are by default associated with a Starter Pool depending on the Fabric capacity size, but you can adjust that using the Edit button.
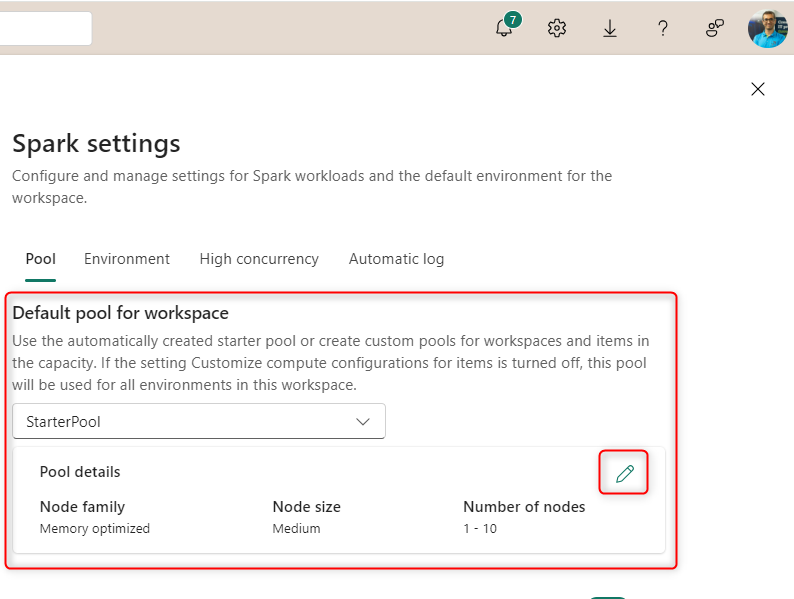
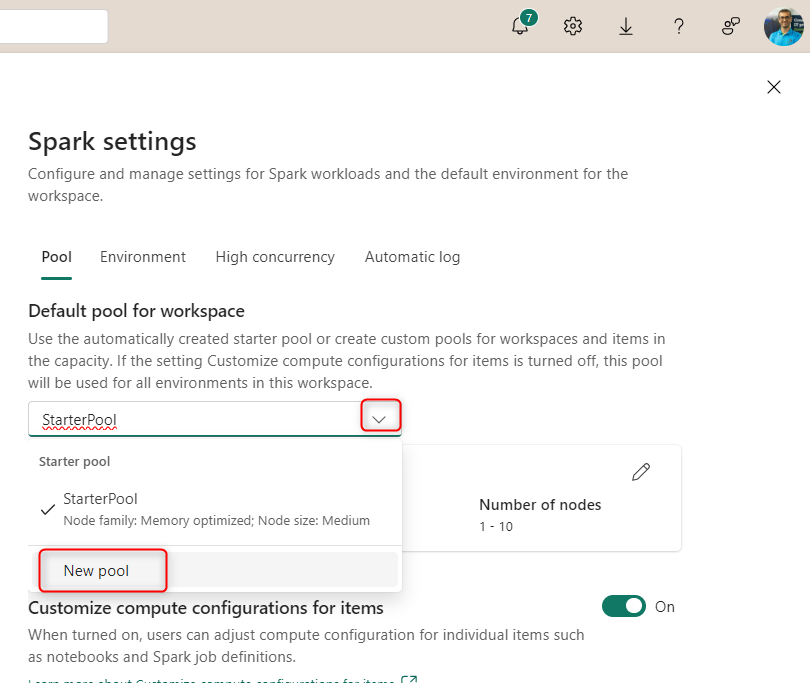
Or if you want to create a new pool (which will be a Custom Pool), then choose it under the dropdown.
For the Custom Pool, you can set the name, the node size, Autoscale, and Dynamic Allocation settings.
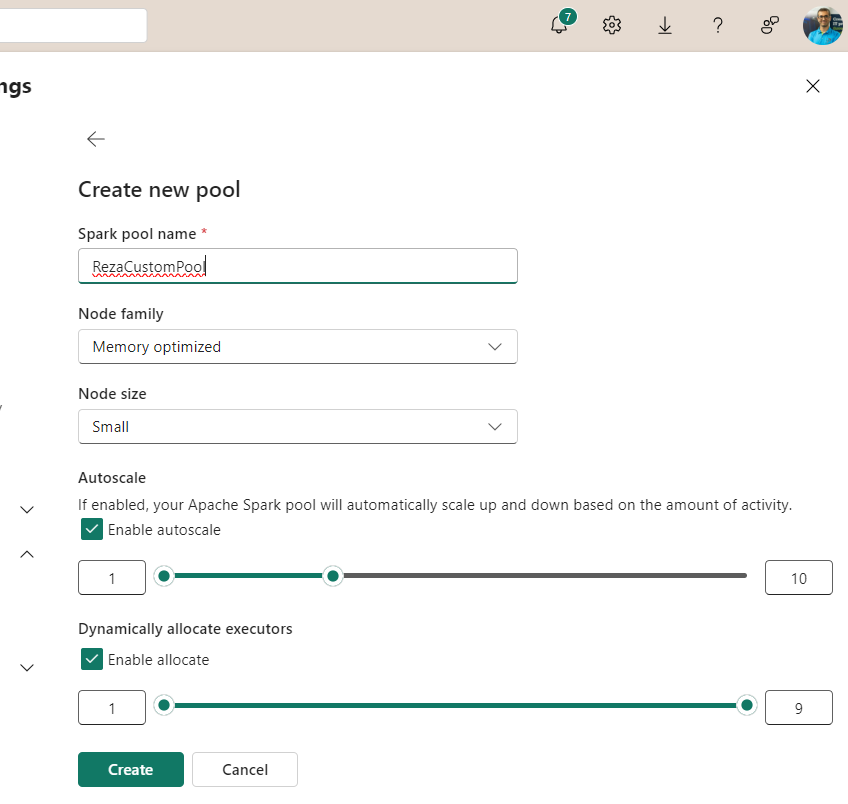
Autoscale
Autoscale allows automatic scaling up and down based on demand. You can choose the minimum and maximum node count for Autoscale, and then the cluster will decide, based on the activities, whether to expand to more nodes or scale down. You can also disable this function, which would then always use a fixed number of nodes.
Dynamic allocation
Dynamic allocation will give Spark some freedom to get more executors for a certain job if needed or release some of them if they are no longer in use.
Single-Node Setup
You can also create a Spark Pool as a Single Node setup, as the below screenshot shows.
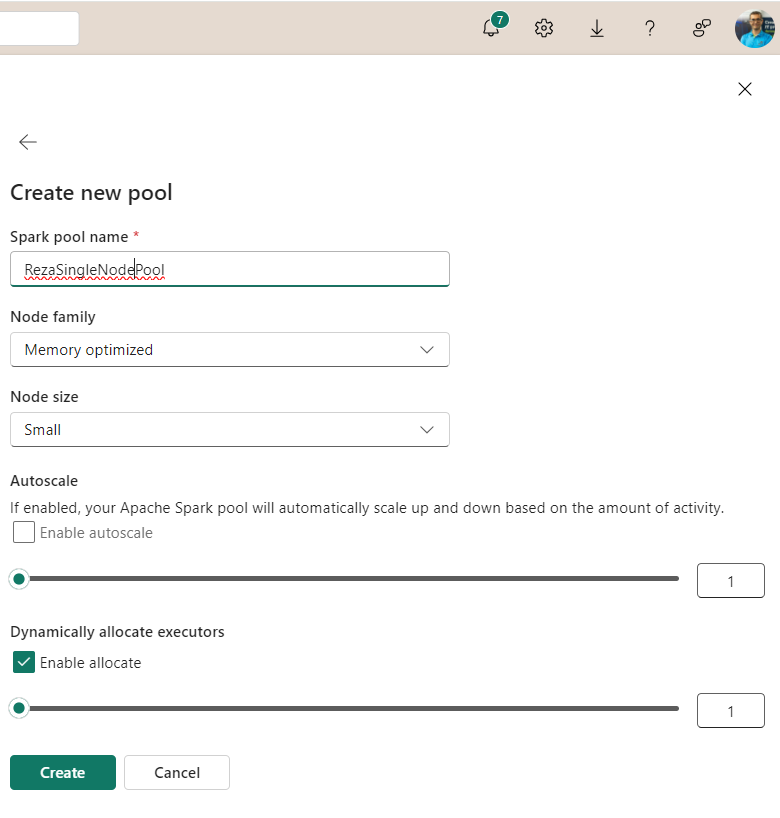
Although a multiple-node structure works better for most use cases because it provides Spark with parallel processing, there are specific situations in which a single-node setup might work better.
For example, for a data science data exploration and preparation task, Pandas is used often for data processing, and that doesn’t run on a multi-thread process. A single-node setup would be a good candidate for that kind of job. In a single-node setup, the driver and the executor will be the same node, all in one machine.
Spark use in Action: Notebook
Last but not least. Here is an example Notebook that runs under a Spark cluster.
The code below reads data from a CSV file in one cell and saves it as a Delta table in another cell.
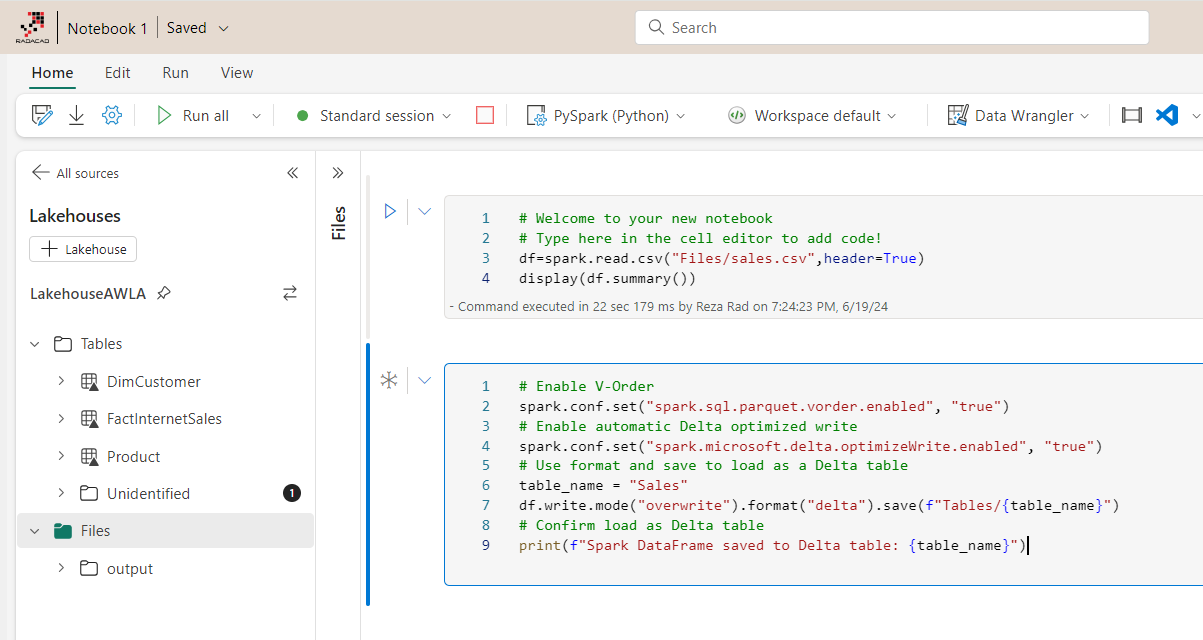
When the code above executes, it will create a session under the Spark instance. You can check the session details.
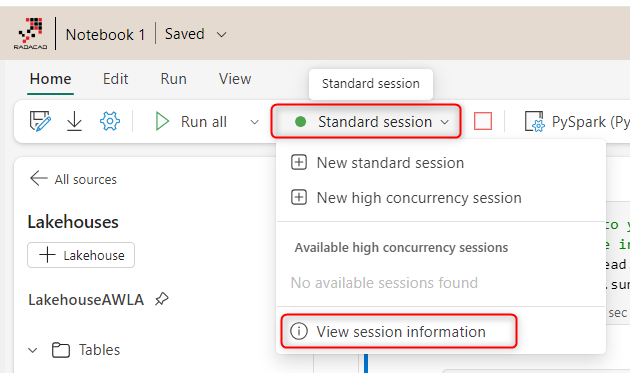
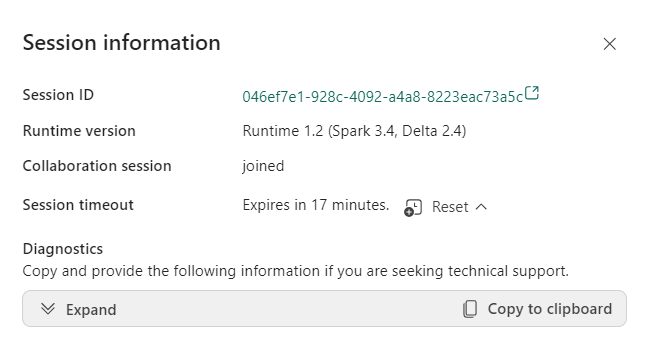
The session information gives you some details which also includes the session expiry (which is part of the dynamic allocation process);
You can also see the Spark job execution details under each cell in the Notebook;
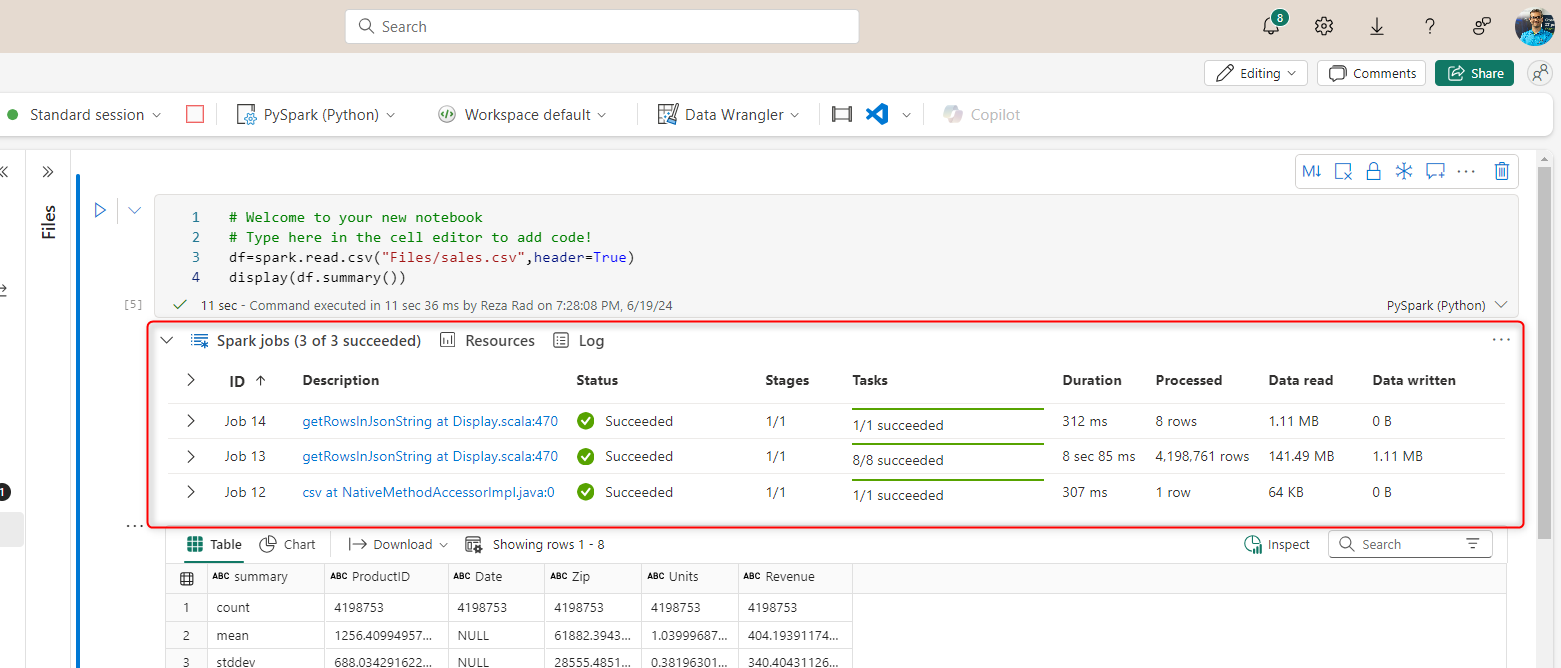
The Resources tab is useful for showing you how resources are consumed/allocated.
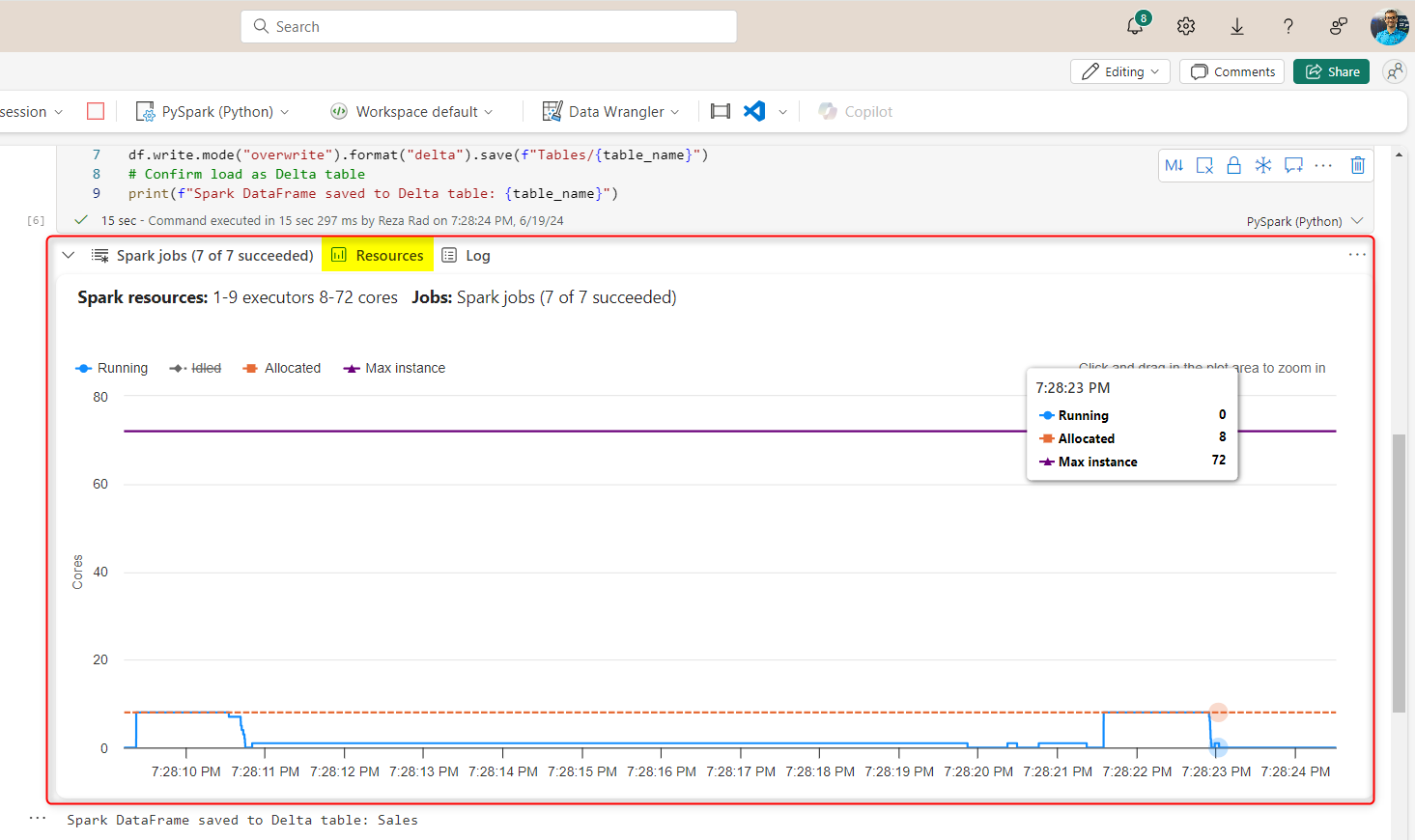
There are many more details explained in the Log tab.
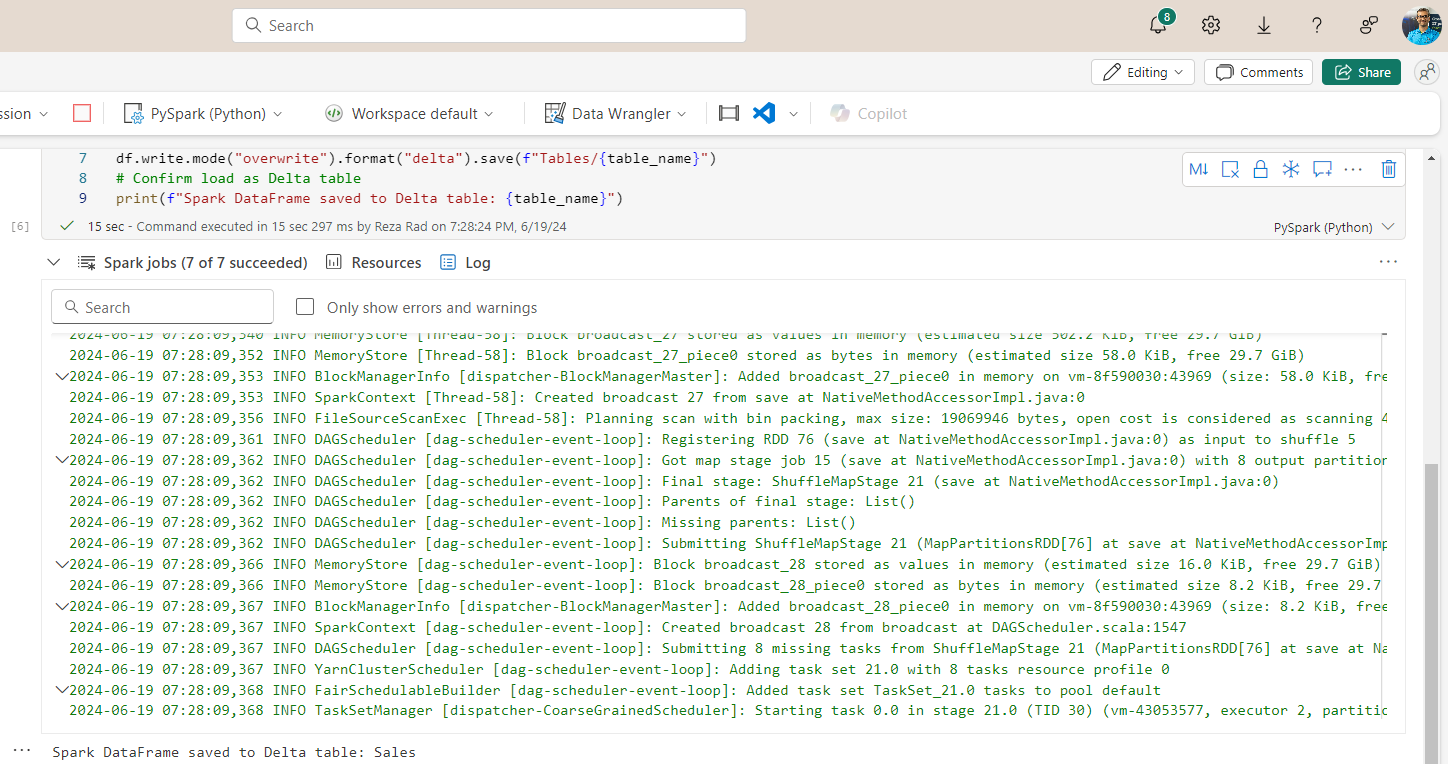
Microsoft Fabric does a good job of abstracting all of those details from you. However, you can configure things as you saw previously in the workspace settings and see some execution processes when the jobs are running in the Notebook.
Summary
Apache Spark is the parallel processing engine for data analytics behind the scenes of Microsoft Fabric. This engine is used when you use Data Engineering or Data Science workloads, specifically when running a Notebook or Spark Job Definition. The Spark configuration can be set at the Workspace level as Spark Pools using the Starter Pool or Custom Pool, and some of the Spark session execution details can be monitored when you run the code in Notebook or Spark Job Definition.
Here are some links to learn more about some of the concepts mentioned in this article;
- An introduction to Microsoft Fabric
- What is Notebook
- Lakehouse in Data Engineering
- Delta Lake table structure
- Workspace structure in your environment




Reza is author of more than 14 books on Microsoft Business Intelligence, most of these books are published under Power BI category. Among these are books such as Power BI DAX Simplified, Pro Power BI Architecture, Power BI from Rookie to Rock Star, Power Query books series, Row-Level Security in Power BI and etc.
He is an International Speaker in Microsoft Ignite, Microsoft Business Applications Summit, Data Insight Summit, PASS Summit, SQL Saturday and SQL user groups. And He is a Microsoft Certified Trainer.
Reza’s passion is to help you find the best data solution, he is Data enthusiast.
His articles on different aspects of technologies, especially on MS BI, can be found on his blog: https://radacad.com/blog.